博客是我工作的好帮手,遇到困难就来博客找资料
分类: 系统运维
2017-02-08 14:26:57
Zeppelin为0.5.6
Zeppelin默认自带本地spark,可以不依赖任何集群,下载bin包,解压安装就可以使用。
使用其他的spark集群在yarn模式下。
配置:
vi zeppelin-env.sh

添加:
export SPARK_HOME=/usr/crh/current/spark-client
export SPARK_SUBMIT_OPTIONS="--driver-memory 512M --executor-memory 1G"export HADOOP_CONF_DIR=/etc/hadoop/conf

注意:设置完重启解释器。
Properties的master属性如下:

新建Notebook
Tips:几个月前zeppelin还是0.5.6,现在最新0.6.2,zeppelin 0.5.6写notebook时前面必须加%spark,而0.6.2若什么也不加就默认是scala语言。
zeppelin 0.5.6不加就报如下错:
Connect to 'databank:4300' failed
%spark.sqlselect count(*) from tc.gjl_test0
报错:

com.fasterxml.jackson.databind.JsonMappingException: Could not find creator property with name 'id' (in class org.apache.spark.rdd.RDDOperationScope)
at [Source: {"id":"2","name":"ConvertToSafe"}; line: 1, column: 1]
at com.fasterxml.jackson.databind.JsonMappingException.from(JsonMappingException.java:148)
at com.fasterxml.jackson.databind.DeserializationContext.mappingException(DeserializationContext.java:843)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.addBeanProps(BeanDeserializerFactory.java:533)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.buildBeanDeserializer(BeanDeserializerFactory.java:220)
at com.fasterxml.jackson.databind.deser.BeanDeserializerFactory.createBeanDeserializer(BeanDeserializerFactory.java:143)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createDeserializer2(DeserializerCache.java:409)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createDeserializer(DeserializerCache.java:358)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createAndCache2(DeserializerCache.java:265)
at com.fasterxml.jackson.databind.deser.DeserializerCache._createAndCacheValueDeserializer(DeserializerCache.java:245)
at com.fasterxml.jackson.databind.deser.DeserializerCache.findValueDeserializer(DeserializerCache.java:143)
at com.fasterxml.jackson.databind.DeserializationContext.findRootValueDeserializer(DeserializationContext.java:439)
at com.fasterxml.jackson.databind.ObjectMapper._findRootDeserializer(ObjectMapper.java:3666)
at com.fasterxml.jackson.databind.ObjectMapper._readMapAndClose(ObjectMapper.java:3558)
at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:2578)
at org.apache.spark.rdd.RDDOperationScope$.fromJson(RDDOperationScope.scala:85)
at org.apache.spark.rdd.RDDOperationScope$$anonfun$5.apply(RDDOperationScope.scala:136)
at org.apache.spark.rdd.RDDOperationScope$$anonfun$5.apply(RDDOperationScope.scala:136)
at scala.Option.map(Option.scala:145)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:136)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:130)
at org.apache.spark.sql.execution.ConvertToSafe.doExecute(rowFormatConverters.scala:56)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$5.apply(SparkPlan.scala:132)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$5.apply(SparkPlan.scala:130)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:150)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:130)
at org.apache.spark.sql.execution.SparkPlan.executeTake(SparkPlan.scala:187)
at org.apache.spark.sql.execution.Limit.executeCollect(basicOperators.scala:165)
at org.apache.spark.sql.execution.SparkPlan.executeCollectPublic(SparkPlan.scala:174)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.DataFrame$$anonfun$org$apache$spark$sql$DataFrame$$execute$1$1.apply(DataFrame.scala:1499)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:56)
at org.apache.spark.sql.DataFrame.withNewExecutionId(DataFrame.scala:2086)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$execute$1(DataFrame.scala:1498)
at org.apache.spark.sql.DataFrame.org$apache$spark$sql$DataFrame$$collect(DataFrame.scala:1505)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1375)
at org.apache.spark.sql.DataFrame$$anonfun$head$1.apply(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.withCallback(DataFrame.scala:2099)
at org.apache.spark.sql.DataFrame.head(DataFrame.scala:1374)
at org.apache.spark.sql.DataFrame.take(DataFrame.scala:1456)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.zeppelin.spark.ZeppelinContext.showDF(ZeppelinContext.java:297)
at org.apache.zeppelin.spark.SparkSqlInterpreter.interpret(SparkSqlInterpreter.java:144)
at org.apache.zeppelin.interpreter.ClassloaderInterpreter.interpret(ClassloaderInterpreter.java:57)
at org.apache.zeppelin.interpreter.LazyOpenInterpreter.interpret(LazyOpenInterpreter.java:93)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer$InterpretJob.jobRun(RemoteInterpreterServer.java:300)
at org.apache.zeppelin.scheduler.Job.run(Job.java:169)
at org.apache.zeppelin.scheduler.FIFOScheduler$1.run(FIFOScheduler.java:134)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:178)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:292)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
原因:
进入/opt/zeppelin-0.5.6-incubating-bin-all目录下:
# ls lib |grep jackson jackson-annotations-2.5.0.jar jackson-core-2.5.3.jar jackson-databind-2.5.3.jar
将里面的版本换成如下版本:
# ls lib |grep jackson jackson-annotations-2.4.4.jar jackson-core-2.4.4.jar jackson-databind-2.4.4.jar
测试成功!
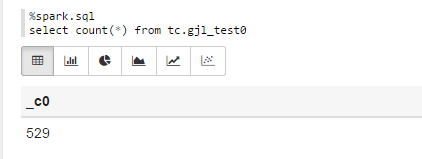
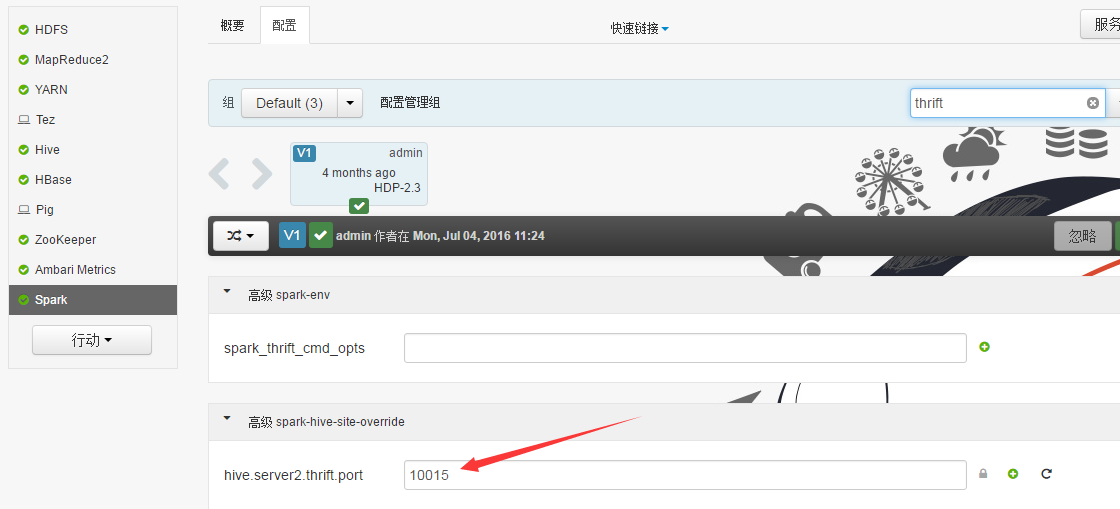
Sparksql也可直接通过hive jdbc连接,只需换端口,如下图:

zeppelin主要有以下功能
数据提取
数据发现
数据分析
数据可视化

目前版本(0.5-0.6)之前支持的数据搜索引擎有如下

环境
centOS 6.6
编译准备工作
sudo yum update sudo yum install openjdk-7-jdk sudo yum install git sudo yum install npm
下载源码
git clone https://github.com/apache/incubator-zeppelin.git
编译,打包
cd incubator-zeppelin #build for spark 1.4.x ,hadoop 2.4.x mvn clean package -Pspark-1.4 -Dhadoop.version=2.4.0 -Phadoop-2.4 -DskipTests -P build-distr

结果会生成在zeppelin-distribution/target下
解压
tar -zxvf zeppelin-0.6.0-incubating-SNAPSHOT.tar.gz
修改配置,在zeppelin-site.xml中可以修改端口号等信息,zeppelin-env.sh中修改一些启动环境变量。
cp zeppelin-site.xml.template zeppelin-site.xml cp zeppelin-env.sh.template zeppelin-env.sh
启动zeppelin
./bin/zeppelin-daemon.sh start
关闭zeppelin(记得要用命令关闭,不然你很可能再也起不来,别问我怎么知道的。)
./bin/zeppelin-daemon.sh stop

安装环节至此结束,后续使用篇主要是hive与spark-sql的可视化使用,有时间将慢慢添加。
1.首先我们要下载zeppelin的压缩包,当我们解压之后(这一台主机上面已经安装过了java的环境)
2.修改配置环境
进入conf/
将zeppelin-env.sh.template修改为zeppelin-env.sh
将zeppelin-site.xml.template修改为zeppelin-site.xml

然后我们接下来修改conf/zeppelin-env.sh新增
export SPARK_MASTER_IP=192.168.109.136
export SPARK_LOCAL_IP=192.168.109.136
3.启动zeppelin
进入zeppelin:进入bin目录下执行./zeppelin-daemon.sh start
然后浏览器访问192.168.109.136:8080进入界面
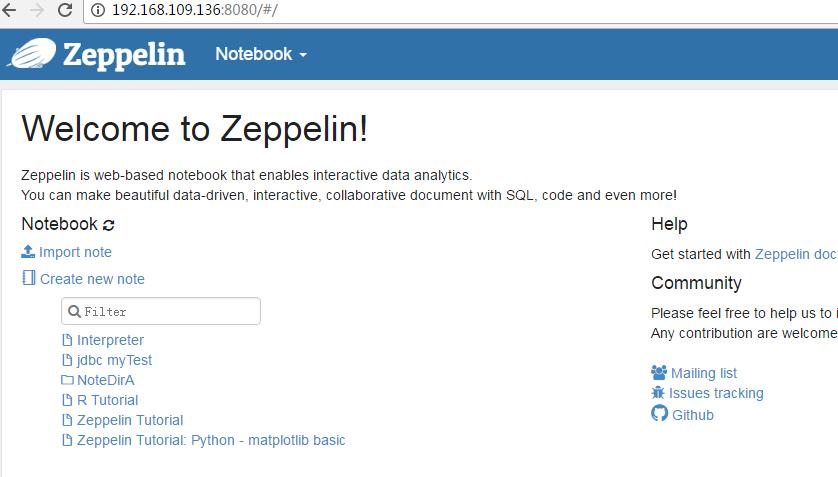
此时就启动成功
4.zeppelin简单实用
1.text
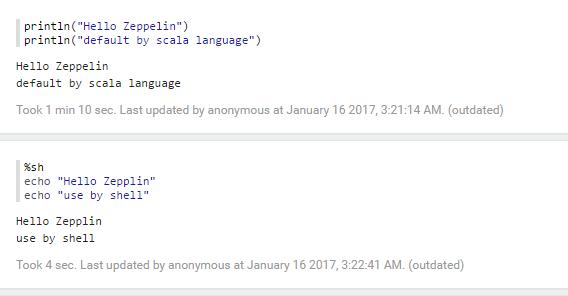
2.html

3.table
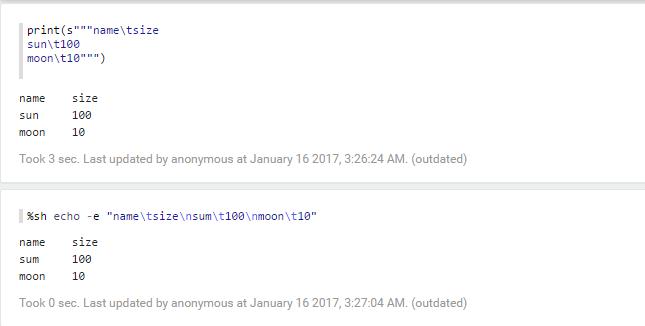

5.可以对数据进行分析
对于我做的最多的分析,就是基于学校的那个资料,我有学校里面的信息,这个里面的每一行的信息是以","
进行分隔,这个其中里面的民族,此时我们对这个民族进行分析
由于我们这个zeppelin是在linux里面的启动,所以我们必须把原有的数据放到linux的里面,此时zeppelin读的文件目录是linux里面的目录
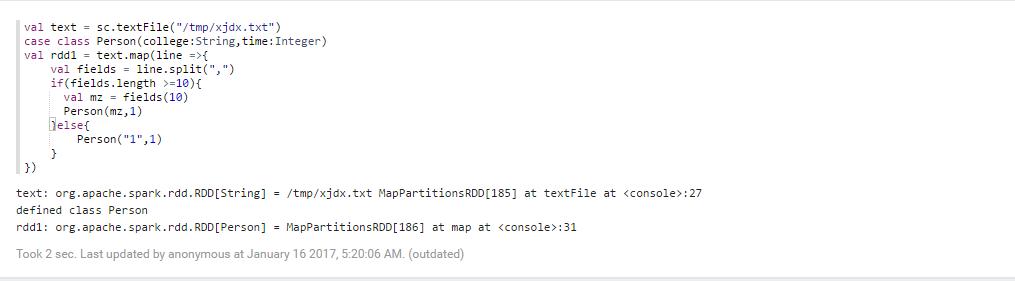



则此时我们就可以对数据库里面的东西进行视图分析,我们通过这个数据,我们发现通过读取数据
,以分组的方式,然后在查询数据有多少个,这样就可以对数据进行显示
a.
val text = sc.textFile("/tmp/xjdx.txt")case class Person(college:String,time:Integer)
val rdd1 = text.map(line =>{
val fields = line.split(",") if(fields.length >=10){
val mz = fields(10)
Person(mz,1)
}else{
Person("1",1)
}
})
b.
rdd1.toDF().registerTempTable("rdd1")
c.
%sql select college,count(1) from rdd1 group by college
1.简单介绍和安装:
(1)Spark使用scala编写,运行在JVM(java虚拟机)上。所以,安装Spark需要先安装JDK。安装好java后,到官网下载安装包(压缩文件): ,当前使用的版本是:spark-1.6.1-bin-hadoop2.4.tgz。
(2)解压,查看目录内容:
tar -zxvf spark-1.6.1-bin-hadoop2.4.tgz
cd spark-1.6.1-bin-hadoop2.4
这样我们可以在单机模式下运行Spark了,Spark也可以运行在Mesos、YARN等上。
2.Spark交互式shell:
(1) Spark只支持Scala和Python两种Shell。为了对Spark Shell有个感性的认识,我们可以follow官网的quick-start教程:
首先启动Spark shell,Scala和Python有2种不同启动方式(下面,我们以Scala为例介绍):
Scala:
./bin/spark-shell
scala启动shell参数:
./bin/spark-shell --name "axx" --conf spark.cores.max=5 --conf spark.ui.port=4041
Python:
./bin/pyspark
启动后有如下界面:
如果需要修改显示的日志级别,修改$SPARK_HOME/conf/log4j.properties文件。
(2)Spark中第一个重要名词:RDD(Resilient Distributed Dataset),弹性分布式数据集。
在Spark中,使用RDD来进行分布式计算。RDD是Spark对于分布数据和分布计算的基本抽象。
RDD包括两类操作,actions 和 transformations;
行动操作(actions):会产生新的值。会对RDD计算出一个结果,并把结果返回到驱动器程序中(例如shell命令行中,我们输入一个计算指令,spark为我们返回的结果值),或把结果存储到外部存储系统(如HDFS)中(我们在后边还会看到rdd.saveAsTextFile())。
转化操作(transformations):会产生一个新的RDD。
val lines = sc.textFile("file:///spark/spark/README.md")
通过读取文件的方式来定义一个RDD。默认地,textFile会读取HDFS上的文件,加上file://指定读取本地路径的文件。
lines.count()
lines.first()
上边是2个actions操作,分别返回RDD的行数和第一行数据。
val linesWithSpark = lines.filter(line=>lines.contains("spark"))
上边是一个transformations操作,生成一个新的RDD,该RDD是lines的一个子集,只返回包含spark的行。
3.Spark核心概念:
每个Spark应用都包含一个驱动程序,该驱动程序在集群中执行并行计算。在前面的事例中,驱动程序就是spark shell本身。驱动程序通过SparkContext对象(对计算集群的一个连接)来访问Spark。
为了运行RDD操作,驱动程序会管理一些叫做执行器的节点。当在分布式系统中运行时,架构图如下:
4.独立应用:
除了在shell中运行,还可以运行独立应用。与Spark Shell主要区别是,当开发独立应用时,你需要自己初始化SparkContext。
4.1 初始化SparkContext
首先,需要创建SparkConf对象来配置应用,然后通过SparkConf来创建SparkContext。初始化SparkContext对象:
SparkConf conf = new SparkConf().setAppName("wc_ms");
JavaSparkContext sc = new JavaSparkContext(conf);
setAppName可以设置这个独立应用的名称,后期我们可以在WebUI上监控这个应用。
4.2 开发WordCount程序:
通过Maven构建Spark程序,pom只需要引入一个依赖(根据具体的Spark版本而定):
WordCount.java
package com.vip.SparkTest;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
public class WordCount {
public static void main(String[] args) {
String inputfile = args[0];
String outputfile = args[1];
//得到SparkContext
SparkConf conf = new SparkConf().setAppName("wc_ms");
JavaSparkContext sc = new JavaSparkContext(conf);
//加载文件到RDD
JavaRDD
//flatMap方法,来自接口JavaRDDLike,JavaRDD继承接口JavaRDDLike。
//将文件拆分成一个个单词(通过空格分开);transformation操作,生成一个新的RDD。
JavaRDD
new FlatMapFunction
{
@Override
public Iterable
// TODO Auto-generated method stub
return Arrays.asList(content.split(" "));
}
}
);
//先转换成元组(key-value),word - 1 word2 - 1;
//再Reduce汇总计算
JavaPairRDD
new PairFunction
@Override
public Tuple2
// TODO Auto-generated method stub
return new Tuple2
}
}
).reduceByKey(
new Function2
@Override
public Integer call(Integer x, Integer y) throws Exception {
// TODO Auto-generated method stub
return x+y;
}
}
)
;
counts.saveAsTextFile(outputfile);
sc.close();
}
}
上边对应的步骤做了注释。
4.3 发布应用到Spark(单机或者集群):
(1)首先,要将开发好的程序打包:
mvn package
得到jar包:SparkTest-0.0.1-SNAPSHOT.jar
(2)将相关文件上传到服务器上:
将要做count的文本文件、jar文件上传服务器。
(3)使用spark-submit启动应用:
$SPARK_HOME/bin/spark-submit \
--class "com.vip.SparkTest.WordCount" \
--master local \
./SparkTest-0.0.1-SNAPSHOT.jar "输入目录" "输出目录"
说明: --class 指定程序的主类;
--master 指定Spark的URL,因为是在本机,所以指定了local
输入目录:包含所有输入的文本文件(可能是一个或多个文件)。
输出目录:这块要特别注意,首先这是一个目录,不能是文件;再次这个目录不能事先创建,否则报错。
spark-shell导入第三方依赖
对于spark下已经有的依赖,直接
import SparkContext
但是有些第三方依赖,需要从外部引入
spark-shell --jars /home/wangtuntun/下载/nscala-time_2.10-2.12.0.jar
如果有多个jar包需要导入,中间用逗号隔开
spark下dataframe转为rdd格式
dataframe可以实现很多操作,但是存储到本地的时候,只能存 parquest格式
需要存储源格式,需要转换为rdd类型
将dataframe中的每一行都map成有逗号相连的string,就变为了一个rdd
基于spark2.0整合spark-sql + mysql + parquet + HDFS
一、概述 spark 2.0做出的改变大家可以参考官网以及其他资料,这里不再赘述由于spark1.x的sqlContext在spark2.0中被整合到sparkSession,故而利用spark-shell客户端操作会有些许不同,具体如下文所述
二、spark额外配置
1. 正常配置不再赘述,这里如果需要读取MySQL数据,则需要在当前用户下的环境变量里额外加上JDBC的驱动jar包 例如我的是:mysql-connector-java-5.1.18-bin.jar 存放路径是$SPARK_HOME/jars 所以需要额外配置环境变量
export PATH = $PATH:$SPARK_HOME/jars
2. 启动spark-shell
bin/spark-shell --master=spark://h4:7077 --driver-class-path=./jars/mysql-connector-java-5.1.18-bin.jar --jars=./jars/mysql-connector-java-5.1.18-bin.jar
3. spark-sql采用sql方式执行操作正常启动之后可以先通过spark-sql建立数据库并切换到当前新建的数据库
spark.sql("create database spark")
可以查看下是否新建成功
spark.sql("show databases ").show
创建成功之后切换数据库
spark.sql("use spark")
现在开始读取远程MySQL数据
val sql = """CREATE TABLE student USING org.apache.spark.sql.jdbc OPTIONS ( url "jdbc:mysql://worker2:3306/spark", dbtable "student", user "root", password "root" )"""
执行:
spark.sql(sql);
等待执行完毕之后,将表数据存入缓存
spark.sql("cache table student")
此时即可进行操作,例如:val studentDF = spark.sql("select id,name from student")
完成需求查询之后,可将结果以parquet的格式保存到HDFS
studentDF.write.parquet("hdfs://h4:9000/test/spark/parquet")
也可以写成json格式
studentDF.write.json("hdfs://h4:9000/test/spark/json")
三、拓展
集群状态下,硬件配置32G内存 2T硬盘,spark配了4核,内存分配了20G的情况下,测试速度如下: 2700万条记录的表导入spark用时1秒以内 sparksql将其以json格式存入HDFS用时288秒,共1.0G,将其以parquet格式存入HDFS用时207秒,共86.6M,可见parquet的优势还是比较明显
dates=pd.date_range('20160728',periods=6) #创建固定频度的时间序列
df=pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD')) #创建6*4的随机数,索引,列名称。
df2=pd.DataFrame({'A':pd.Timestamp('20160728'),'B':pd.Series(1)})#字典创建Dataframe,假如字典的数据长度不同,以最长的数据为准。
df2.dtypes #查看各行的数据格式
df2.head() df2.tail(5) #查看前、后几列
df.columns df.value #查看列名、value
df.describe() #查看描述性的统计,比如每一列的count、mean、std...
df.T df.sort(columns='C') #转秩、排序
df['A'] df[1:3]#选择A列数据,选择1-2行数据,切片操作得到的是行数据。
df.loc[:,['A','B']] #选择多列数据
df.loc['20160728':'20160730',['A','B']] #选择局部区域
df.at[dates[0],'A'] #选择某个值
df.iloc[3] df.iloc[1,1]#提取第四行数据,取第2行第2列的这个数
df.iloc[3:5,0:2] #像array一样切片操作
df.iloc[[1,2,4],[0,2]] #提取不连续的行和列
df.iat[1,1]#专门取某个数,效率比较高
df[(df.D>0)&(df.C<0)] #选择D列数据大于0的行
df[['A','B']][(df.D>0)&(df.C<0)]#选择D列数据大于0的行,只返回A,B两列
df['D'].isin(alist)#alist是一个预先定义的列表,把要筛选的值写到列表中,查找D数据中含有alist的值
os.getcwd()#获得当前的工作目录
df=pd.read_csv('',encoding='gbk',sep=',')#读取csv文件
counts=df[u'专业名称'].value_counts() #计数统计
plt=counts.plot(kind='bar').get_figure()
plt.savefig('d/plot.png') #画图
good=df[df[u'高考分数']>520] #筛选
good_counts=good[u'专业名称'].value_counts()
per=good_counts/counts #计算百分比,直接利用矩阵的除法
df.groupby('A').first() #按A列分组,输出每一组的第一行数据
df.groupby(['A','B']) #按两列分组
#创建函数,作为分组标准。 下例:如果列名是abem中的之一,就分为组别v反之为w
def get_type(letter):
if letter.lower() in 'abem':
return 'v'
else:
return 'w'
grouped=df.groupby(get_type,axis=1)
import pandas.util.testing as tm
colors=tm.choice(['red','green'],size=10)
foods=tm.choice(['eggs','ham'],size=10) #随机创建两个数组
index=pd.MultiIndex.from.arrays([colors,foods],names=['color','food']) #创建MultiIndex对象,然后创建DataFrame对象
df.pd.DataFrame(np.random.randn(10,2),index=index)
print df.query('color=="red"') #查询
grouped=df.groupby(level='food')#在分组中使用索引
df.index.names=[None,None]
print df.query('ilevel_0=="red"')#删除了索引名称,只能使用ilevel_0表示第一个索引
grouped=df.groupby(level=1)
grouped.aggregate(np.sum) #计算各组的总和
print grouped.aggregate(np.sum).reset_index()#将索引转化为列向量
df.groupby(level=['color'],as_index=False).sum()#能达到一样的效果
print grouped.size()#返回每个组的数据量
print grouped.discribe()#返回各组数据的描述性信息
#transformation标准化数据
import pandas as pd
import numpy as np
index=pd.date_range('20140101',periods=100)
ts=pd.Series(np.random.normal(0.5,2,100),index)
print ts.head()
key=lambda x:x.month
zscore=lambda x:(x-x.mean())/x.std()
transformed=ts.groupby(key).transform(zscore)
print type(transformed)
print transformed.groupby(key).mean()
print transformed.groupby(key).std()
#使用agg
grouped=df.groupby(level='color').agg(['SUM':np.sum,'MEAN':np.mean,'STD':np.std])
#通过lambda匿名函数来进行特殊计算
print grouped['a'].agg({'lambda':lambda x:np.mean(abs(x))})
#按月分组
key =lambda x:x.month
grouped=ts.groupby(key).agg({'SUM':np.sum,'MEAN':np.mean,'STD':np.std})
print grouped
#索引不是日期
df.groupby(df['date'].apply(lambda x:x.month)).first()
df.set_index('date')#或者将date设置为索引
#如果日期是字符串形式存储的
date_string =('2010-09-01','2020-01-01')
a=pd.Series([pd.to_datetime(date) for date in date_string])
#增加列
df['c']=pd.Series(np.random.randn(10),index=df.index)
df.insert(1,'e',df['a'])#在a列后面插入e列
del df['c'] #删除列c
df2=df.drop(['a','b'],axis=1)#df数据不变,删除后的数据放入df2中
b=df.pop('b')
df.insert(0,'b',b)#移动,pop移除之后再插入
#字符串操作
s=pd.Series(list('ABCDEF')
s.str.lower()
s.str.upper()#大小写
s.str.len()
s.str.split('_').str.get(1) #获取切割后的某个元素
s.str.replace('^a|b$','X',case=False)#替换,第一个参数是正则表达式,第二个是要替换的字符串
s=pd.Series(['a1','a2','b1','b2',c])
s.str.extract('([ab])(\d)?') #使用extract方法提取数字:第一个参数是正则表达式,括号表示要提取的部分,结果是a 1,a 2,b 1,b 2,NaN NaN,无法匹配的
s.str.extract('(?P
pattern=r'[a-z][0-9]'
print s.str.contains(pattern,na=False)#匹配字符串,na参数用来说明出现NaN数据时匹配成True还是False
s.str.match(pattern,as_index=False)#严格匹配字符串
s.str.endswith('l',na=False) #等效于contains('l$',na=False)
s.str.startwith('l',na=False)#等效于contains('^l',na=False)
#读写数据库
import MySQLdb
con=MySQLdb.connect(host="localhost",db="")
sql="SELECT * FROM..."
df=pd.read_sql(sql,con,index_col='id')
con2=execute('DROP TABLE IF EXISTS wheather')
pd.io.sql.write_frame(df,"wheather",con2)
#缺失值数据处理
df=pd.DataFrame(np.random.randn(5,3),index=list('abcde'),columns=['one','two','three'])
df.ix[1,:-1]=np.nan #在简单的运算中,遇到缺失值,运算结果也是缺失值,在描述性统计中,Nan都是作为0进行运算
#df.loc[:,['one','three']]
df.fillna(0) #用0填充缺失值 df.fillna('missing') 用字符串代替缺失值
df.fillna(method='pad')#用前一个数据代替NaN
df.fillna(method='bfill',limit=1)#用后一个数据替代NaN,限制每列只能替代一个NaN
df.fillna(df.mean()['one':'two'])#用平均数代替,选择one,two两列进行缺失值处理
df.dropna(axis=0) #删除含有NaN的行,axis=1 删除列
df.interpolate() #使用插值来估计NaN 如果index是数字,可以设置参数method='value' ,如果是时间,可以设置method='time'
df.replace({1:11,2:12})
Pandas是Python下一个开源数据分析的库,它提供的数据结构DataFrame极大的简化了数据分析过程中一些繁琐操作。
1. 基本使用:创建DataFrame. DataFrame是一张二维的表,大家可以把它想象成一张Excel表单或者Sql表。Excel 2007及其以后的版本的最大行数是1048576,最大列数是16384,超过这个规模的数据Excel就会弹出个框框“此文本包含多行文本,无法放置在一个工作表中”。
Pandas处理上千万的数据是易如反掌的sh事情,同时随后我们也将看到它比SQL有更强的表达能力,可以做很多复杂的操作,要写的code也更少。 说了一大堆它的好处,要实际感触还得动手码代码。首要的任务就是创建一个DataFrame,它有几种创建方式:
列表,序列(pandas.Series), numpy.ndarray的字典
二维numpy.ndarray
别的DataFrame
结构化的记录(structured arrays)
其中,我最喜欢的是通过二维ndarray创建DataFrame,因为代码敲得最少:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(3, 4))
df
0 1 2 3
0 0.236175 -0.394792 -0.171866 0.304012
1 0.651926 0.989046 0.160389 0.482936
2 -1.039824 0.401105 -0.492714 -1.220438
当然你还可以参考我的这篇文章从mysql数据库或者csv文件中载入数据到dataframe。
Pandas的基本用法,后来有些朋友问Pandas怎么从数据库中读取数据,怎么从文件中读取数据之类的问题,因此单独开篇文章介绍Pandas如何读取数据到Dataframe。将Dataframe写入文件和数据库可以参考这篇文章
1. Pandas读取Mysql数据
要读取Mysql中的数据,首先要安装Mysqldb包。假设我数据库安装在本地,用户名位myusername,密码为mypassword,要读取mydb数据库中的数据,那么对应的代码如下:
import pandas as pd
import MySQLdb
mysql_cn= MySQLdb.connect(host='localhost', port=3306,user='myusername', passwd='mypassword', db='mydb')
df = pd.read_sql('select * from test;', con=mysql_cn)
mysql_cn.close()
上面的代码读取了test表中所有的数据到df中,而df的数据结构为Dataframe。
2. Pandas读取csv文件数据
Pandas读取csv文件中的数据要简单的多,不用额外安装程序包,假设我们要读取test.csv中的数据, 对应的代码如下:
df = pd.read_csv(loggerfile, header=None, sep=',')
header=None表示没有头部,sep=’,’表示字段之间的分隔符为逗号。
dataframe中index用来标识行,column标识列,shape表示维度。
df.index
df.columns
df.shape
通过describe方法,我们可以对df中的数据有个大概的了解:
df.describe()
0 1 2 3
count 3.000000 3.000000 3.000000 3.000000
mean -0.050574 0.331786 -0.168064 -0.144496
std 0.881574 0.694518 0.326568 0.936077
min -1.039824 -0.394792 -0.492714 -1.220438
25% -0.401824 0.003156 -0.332290 -0.458213
50% 0.236175 0.401105 -0.171866 0.304012
75% 0.444051 0.695076 -0.005739 0.393474
max 0.651926 0.989046 0.160389 0.482936
2. 数据select, del, update。
按照列名select:
df[0]
0 0.236175
1 0.651926
2 -1.039824
按照行数select:
1
df[:3] #选取前3行
按照索引select:
df.loc[0]
0 0.236175
1 -0.394792
2 -0.171866
3 0.304012
按照行数和列数select:
df.iloc[3] #选取第3行
df.iloc[2:4] #选取第2到第3行
df.iloc[0,1] #选取第0行1列的元素
dat.iloc[:2, :3] #选取第0行到第1行,第0列到第2列区域内的元素
df1.iloc[[1,3,5],[1,3]] #选取第1,3,5行,第1,3列区域内的元素
删除某列:
del df[0]
df
1 2 3
0 -0.394792 -0.171866 0.304012
1 0.989046 0.160389 0.482936
2 0.401105 -0.492714 -1.220438
删除某行:
df.drop(0)
1 2 3
1 0.989046 0.160389 0.482936
2 0.401105 -0.492714 -1.220438
3.运算。
基本运算:
df[4] = df[1] + df[2]
1 2 3 4
0 -0.394792 -0.171866 0.304012 -0.566659
1 0.989046 0.160389 0.482936 1.149435
2 0.401105 -0.492714 -1.220438 -0.091609
map运算,和python中的map有些类似:
df[4].map(int)
0 0
1 1
2 0
apply运算:
df.apply(sum)
1 0.995359
2 -0.504192
3 -0.433489
4 0.491167
4. Group by 操作。
pandas中的group by 操作是我的最爱,不用把数据导入excel或者mysql就可以进行灵活的group by 操作,简化了分析过程。
df[0] = ['A', 'A', 'B']
df
1 2 3 4 0
0 -0.394792 -0.171866 0.304012 -0.566659 A
1 0.989046 0.160389 0.482936 1.149435 A
2 0.401105 -0.492714 -1.220438 -0.091609 B
g = df.groupby([0])
g.size()
A 2
B 1
g.sum()
1 2 3 4
0
A 0.594254 -0.011478 0.786948 0.582776
B 0.401105 -0.492714 -1.220438 -0.091609
5. 导出到csv文件
dataframe可以使用to_csv方法方便地导出到csv文件中,如果数据中含有中文,一般encoding指定为”utf-8″,否则导出时程序会因为不能识别相应的字符串而抛出异常,index指定为False表示不用导出dataframe的index数据。
df.to_csv(file_path, encoding='utf-8', index=False)
如何从数据库中读取数据到DataFrame中?pandas提供这这样的接口完成此工作——read_sql()。下面我们用离子来说明这个方法。
我们要从sqlite数据库中读取数据,引入相关模块
read_sql接受两个参数,一个是sql语句,这个你可能需要单独学习;一个是con(数据库连接)、read_sql直接返回一个DataFrame对象
打印一下,可以看到已经成功的读取了数据
我们还可以使用index_col参数来规定将那一列数据设置为index
结果输出为:
当然,我们可以设置多个index,只要将index_col的值设置为列表
输出结果为:
写入数据库也很简单,下面第二句用于删除数据库中已有的表"weather_2012",然后将df保存到数据库中的"weather_2012"表
假如我们使用的是mysql数据库也没问题,我们只需要建立与mysql的连接即可,用下面的con代替上面的con可以达到的效果相同。
补充:
(1)DateFrane 可以将结果转换成DataFrame
DataFrame 可以将结果转换成DataFrame
(2)存储
pd.io.sql.write_frame(df, "user_copy", conn)#不能用已经移除
pd.io.sql.to_sql(piece, "user_copy", conn,flavor='mysql',if_exists='replace')#必须制定flavor='mysql'
从一个数据库读取存储到另一个数据库
(3)根据条件添加一列数据
piece['xb'] = list(map(lambda x: '男' if x == '123' else '女', piece['pwd']))
(4)如果有汉字,链接时必须知道字符类型 charset="utf8"
(5)最后实现代码(迭代读取数据,根据一列内容新增一列,)
最后代码
(7)sqlalchemy链接 需要制定一些中文 create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/jd?charset=utf8", max_overflow=5)
