博客是我工作的好帮手,遇到困难就来博客找资料
分类: 系统运维
2017-02-07 20:59:15
Apache Zeppelin介绍:A web-based notebook that enables interactive data analytics. You can make beautiful data-driven, interactive and collaborative documents with SQL, Scala and more.
安装说明:
下载地址:download.html当前最新版是0.6.1
点击下载后解压到指定文件夹,你的zeppelin就安装完成了,很简单。
但是zeppelin依赖于jdk,所以使用zeppelin前还需要机器拥有jdk环境。
解压完毕后需要配置几个地方:
将conf中的zeppelin-env.sh.template与zeppelin-site.xml.template 重命名,去掉template
修改conf/zepplin-env.sh
新增
export SPARK_MASTER_IP=127.0.0.1
export SPARK_LOCAL_IP=127.0.0.1修改
export ZEPPELIN_MEM="-Xmx2048m -XX:PermSize=256M"
需要注意的是lib下的jar包,默认带的jackson-databind-2.5.3.jar包是无法使用的,这点不知道为什么zeppelin怎么处理的,
需要将jackson-databind/jackson-annonations/jackson-core三个jar包全部替换成2.6.5版本的就可以了。
启动zeppelin:进入bin目录下执行 ./zeppelin-daemon.sh start
然后浏览器访问127.0.0.1:8080就进入如下页面:
ok,你的zeppelin安装成功了!
其实zeppelin就是一个java web项目,这样理解起来似乎就容易点了,接下来为了可以使用sql统计数据,我们来操作一下如何添加interpreter:
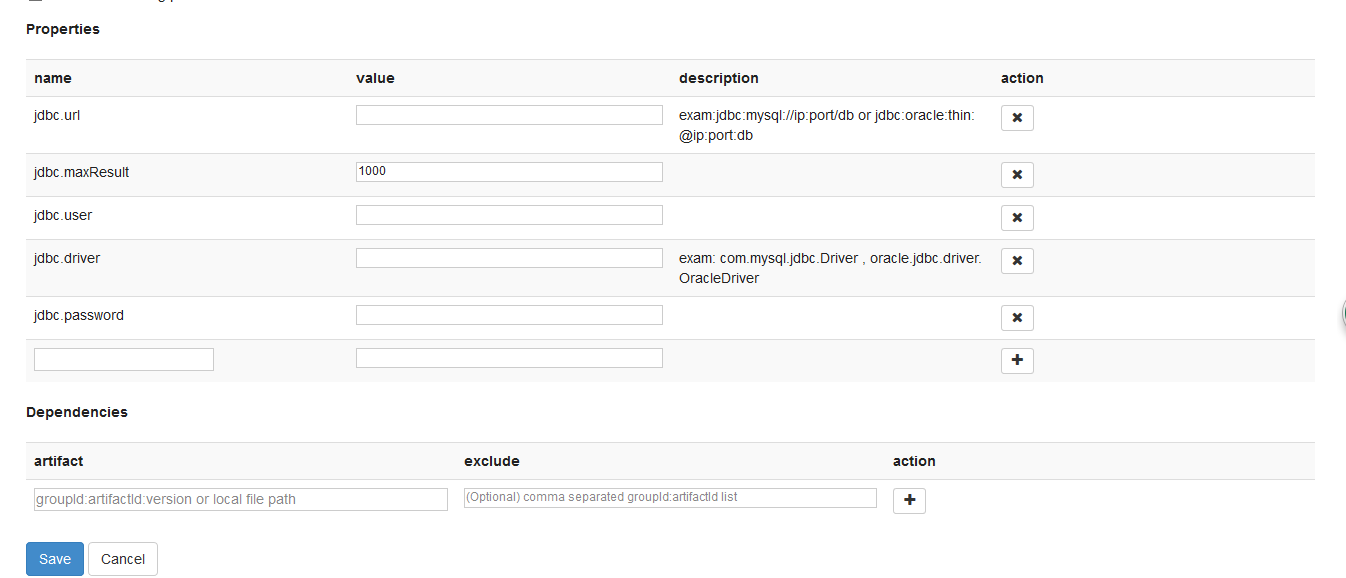
首先修改conf/zeppelin-site.xml,添加org.apache.zeppelin.jdbc.JdbcInterpreter
进入lib目录下上传 JdbcInterpreter.jar、mysql-connection-.....jar两个jar包
然后重启zeppelin,进入web页面的interpreter下,点击create:添加完成之后是这个样子:
然后进入notebook页面: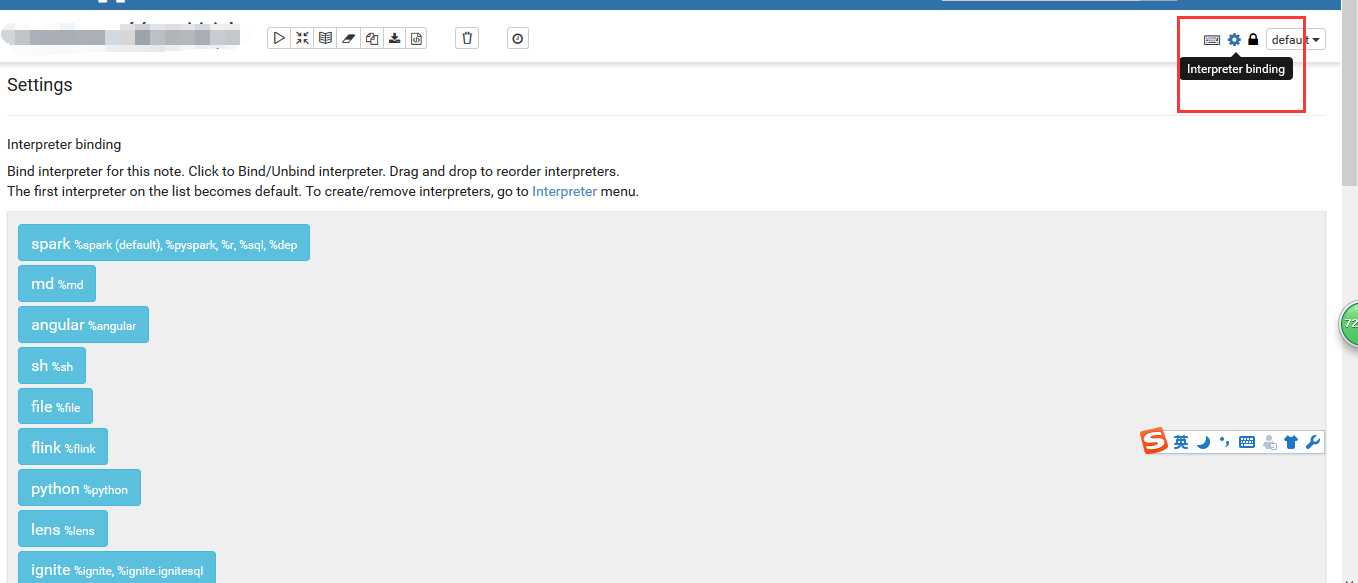 绑定刚刚添加的interpreter就可以使用了:
绑定刚刚添加的interpreter就可以使用了:
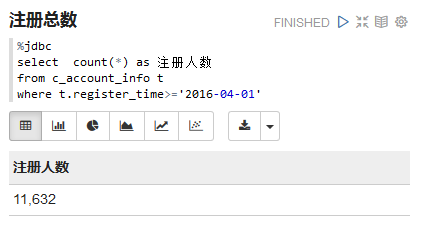
![]()
这样一个JdbcInterpreter就添加完毕了。
至于以后再想和redis、solr一起使用也是相应的加入jar包就可以了~
就我个人来说zeppelin可以满足企业运营这块的需求,包括日活、百度引流统计、ngnix日志分析、用户行为分析、热门词汇、整体数据统计、多维度数据统计等等。
