在linux下用vim打开jpg文件,使用%!xxd进行16进制显示时,文件头显示为"3f3f
3f3f 0011 0804"文件尾端显示为 "3f3f
0a";而同样的操作在windows下,就显示为"ffd8 ffc0 0011 0804"和 "ffd9
0a",这才是正确的jpeg文件头和文件尾标志。
很蹊跷 !
初时,我以为是jpeg在windows和linux下是不同的文件头,后来把jpg后缀去掉,就一个纯文件,现象依旧。考虑可能不是操作系统的差异了。
重新使用ghex打开jpeg数据查看,发现显示正常,为"ffd8 ffc0 0011
0804"和 "ffd9 0a",正确。
估计应该是vim的问题了。
3f的ascii码是?,那表示vim对文件头、尾没有正常解析,是不是和vim解析文件时用的编码格式有关系呢?
打开.vimrc配置项,屏蔽掉下面这句话:
set fileencodings=utf-8,gb2312,gbk,gb18030,ucs-bom
再用vim打开jpeg文件,显示"ffd8 ffc0 0011 0804"和 "ffd9 0a",
显示正确。
原来,为了支持识别和显示中文,我规定了vim的fileencodings,
当vim打开文件时,会使用规定的编码格式对数据进行解析,可惜jpeg的文件头FFD8、尾FFD9
不是任何一个中文的编码,vim找不到对应的中文字,就显示为??,即:3f3f。
至此,困惑全部打开。
通常
来说文件分为文本和二进制文件两大类,文本文件的编辑很容易,Windows下的notepad、UltraEdit都很好用,二进制文件的编辑在
Windows下也有很多工具,UltraEdit也不错,但是Linux下呢?今天终于发现了一个好方法,但是最终出处找不到了。
首先创建一个二进制文件:
-
[oracle@logserver tmp]$ echo -n "ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz" > test.bin
-
[oracle@logserver tmp]$ cat test.bin
-
ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz
-
[oracle@logserver tmp]$
注意echo 一定要跟上 -n 选项,否则会被自动加上一个换行行,再用vim打开 test.bin
-
[oracle@logserver tmp]$ vim -b test.bin
vim 的 -b 选项是告诉 vim 打开的是一个二进制文件,不指定的话,会在后面加上 0x0a ,即一个换行符。
在命令模式下键入:
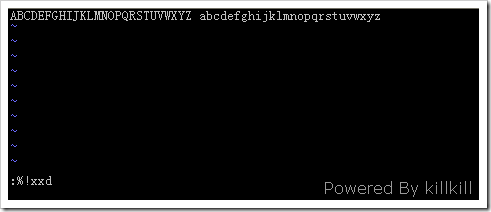
如果 vim 后面没有加 -b 选项就会出现可恶的 0x0a:
如果有 -b 选项就不会有这种情况:
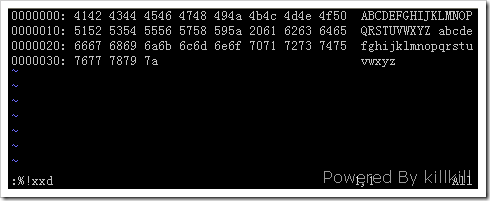
然后进入编辑模式改,改就是了,我将A、B对应的41、42改成61、62,将a、b对应的61、62改成41、42。
回到命令模式输入:
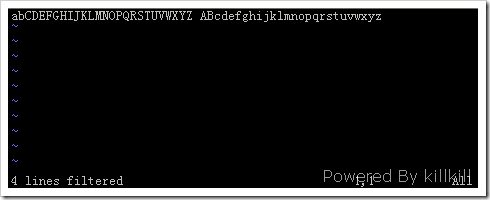
此时可以发现AB和ab的位置互换了。
最后在命令模式中输入 :wq 保存退出即可。
-----------------------------------------------------------------------------------------------------------
vim可以很方便地编辑二进制文件,个人认为它比emacs的二进制编辑方式更好用。vim中二进制文件的编辑是先通过外部程序xxd来把文件dump成其二进制的文本形式,然后就可以按通常的编辑方式对文件进行编辑,编辑完成后再用xxd 转化为原来的形式即可。
可分如下几步进行:
(1) 首先以二进制方式编辑这个文件: vim -b datafile
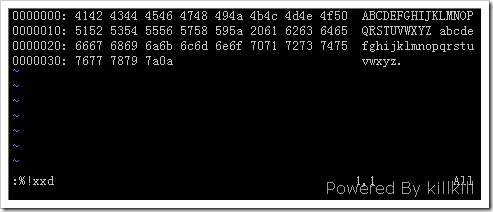
(2) 现在用 xxd 把这个文件转换成十六进制: :%!xxd
文本看起来像这样:
0000000: 1f8b 0808 39d7 173b 0203 7474 002b 4e49 ....9..;..tt.+NI
0000010: 4b2c 8660 eb9c ecac c462 eb94 345e 2e30 K,.`.....b..4^.0
0000020: 373b 2731 0b22 0ca6 c1a2 d669 1035 39d9 7;'1.".....i.59.
现在你可以随心所欲地阅读和编辑这些文本了。 Vim 把这些信息当作普通文本来对待。修改了十六进制部分并不导致可显示字符部分的改变,反之亦然。
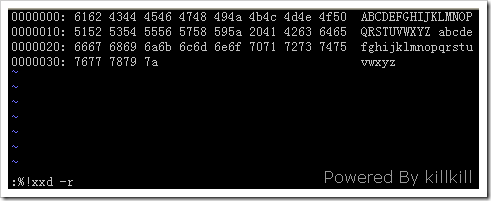
(3) 最后,用下面的命令把它转换回来: :%!xxd -r
只有十六进制部分的修改才会被采用。右边可显示文本部分的修改忽略不计。
xxd是linux的一个命令,vim可以通过”!”来调用外部命令,其功能就是进行十六进制的dump或者反之。
VIM 编辑二进制文件 (vim手册载录)
*23.4* 二进制文件
你可以用 Vim 来编辑二进制文件。Vim 本非为此而设计的,因而有若干局限。但你能读取一个文件,改动一个字符,然后把它存盘。结果是你的文件就只有那一个字符给改了,其它的就跟原来那个一模一样。
要保证 Vim 别把它那些聪明的窍门用错地方,启动 Vim 时加上 ”-b” 参数:
vim -b datafile
这个参数设定了 'binary' 选项。其作用是排除所有的意外副作用。例如,'textwidth' 设为零,免得文本行给擅自排版了。并且,文件一律以
Unix 文件格式读取。
二进制模式可以用来修改某程序的消息报文。小心别插入或删除任何字符,那会让程序运行出问题。用 “R” 命令进入替换模式。
文件里的很多字符都是不可显示的。用 Hex 格式来显示它们的值:
:set display=uhex
另外,也可以用命令 “ga” 来显示光标下的字符值。当光标位于一个 字符上时,该命令的输出看起来就像这样:
<^[> 27, Hex 1b, Octal 033
文件中也许没那么多换行符。你可以关闭 'wrap' 选项来获得总览的效果:
:set nowrap
字节位置
要发现你在文件中的当前字节位置,请用这个命令:
g CTRL-G
其输出十分冗长:
Col 9-16 of 9-16; Line 277 of 330; Word 1806 of 2058; Byte 10580 of 12206
最后两个数字就是文件中的当前字节位置和文件字节总数。这已经考虑了 'fileformat' 选项导致换行符字节不同的影响。
要移到文件中某个指定的字节,请用 “go” 命令。例如,要移到字节 2345:
2345go
使用 XXD
一个真正的二进制编辑器用两种方式来显示文本: 二进制和十六进制格式。你可以在 Vim 里通过转换程序 “xxd” 来达到这效果。该程序是随 Vim 一起发布的。
首先以二进制方式编辑这个文件:
vim -b datafile
现在用 xxd 把这个文件转换成十六进制:
:%!xxd
文本看起来像这样:
0000000: 1f8b 0808 39d7 173b 0203 7474 002b 4e49 ....9..;..tt.+NI
0000010: 4b2c 8660 eb9c ecac c462 eb94 345e 2e30 K,.`.....b..4^.0
0000020: 373b 2731 0b22 0ca6 c1a2 d669 1035 39d9 7;'1.".....i.59.
现在你可以随心所欲地阅读和编辑这些文本了。 Vim 把这些信息当作普通文本来对待。修改了十六进制部分并不导致可显示字符部分的改变,反之亦然。
最后,用下面的命令把它转换回来:
:%!xxd -r
只有十六进制部分的修改才会被采用。右边可显示文本部分的修改忽略不计。
--------------------------------------------------------------------------------------------------------
xxd使用手册
目录:
★ 命令行参数简介
★ xxd使用中的注意事项
★ xxd使用举例
. 从偏移0x10开始显示,也就是缺省情况下的第一行不显示
. 显示倒数0x30个字节(缺省情况下倒数3行)
. 显示120字节,连续显示,每行20字节
. 显示120字节,每行12字节
. 显示0x6c偏移开始的12个字节
. 创建一个65537字节大小的文件,除了最后一个字节是'A',其余都是0x00
. 使用autoskip选项
. 创建只包含一个'A'字节的文件
. 复制输入文件到输出文件,且给输出文件前部增加100字节的0x00
. 二进制文件打补丁
. Read single characters from a serial line
★ 命令行参数简介
xxd -h
xxd [options] [infile [outfile]]
xxd -r [options] [infile [outfile]]
xxd可以创建给定文件或标准输入的hexdump,也可以还原一个hexdump成以前的二进
制文件。如果没有指定文件或指定文件名为-,则采用标准输入。如果没有指定输出
文件或指定文件名为-,则采用标准输出。
-a
toggle autoskip: A single '*' replaces nul-lines. Default off.
-b
采用2进制显示,而不是默认的16进制
xxd -l 32 -b scz.sh
0000000: 00100011 00100001 00100000 00101111 01100010 01101001 #! /bi
0000006: 01101110 00101111 01110011 01101000 00001010 00100011 n/sh.#
000000c: 00001010 00100011 00100000 11001000 10100001 11010110 .# ...
0000012: 11110111 11001001 11101000 10110001 10111000 10111010 ......
0000018: 11000101 00001010 00100011 00100000 01100011 01100001 ..# ca
000001e: 01110100 00100000 t
-c cols
默认16,-i指定时采用12,-p指定时采用30,-b指定时采用6,最大256
-c8、-c 8、-c 010是等价的,其他选项类似。
xxd -c 8 -l 32 -g 1 scz.sh
0000000: 23 21 20 2f 62 69 6e 2f #! /bin/
0000008: 73 68 0a 23 0a 23 20 c8 sh.#.# .
0000010: a1 d6 f7 c9 e8 b1 b8 ba ........
0000018: c5 0a 23 20 63 61 74 20 ..# cat
-E
不用ASCII显示,而采用EBCDIC编码,不影响16进制显示
xxd -E -l 32 -g 1 scz.sh
0000000: 23 21 20 2f 62 69 6e 2f 73 68 0a 23 0a 23 20 c8 ......>........H
0000010: a1 d6 f7 c9 e8 b1 b8 ba c5 0a 23 20 63 61 74 20 .O7IY...E..../..
-g bytes
比较下面三种显示方式,缺省bytes为2,指定-b时采用1。
xxd -l 32 -g 0 scz.sh
0000000: 2321202f62696e2f73680a230a2320c8 #! /bin/sh.#.# .
0000010: a1d6f7c9e8b1b8bac50a232063617420 ..........# cat
xxd -l 32 -g 1 scz.sh
0000000: 23 21 20 2f 62 69 6e 2f 73 68 0a 23 0a 23 20 c8 #! /bin/sh.#.# .
0000010: a1 d6 f7 c9 e8 b1 b8 ba c5 0a 23 20 63 61 74 20 ..........# cat
xxd -l 32 -g 2 scz.sh
0000000: 2321 202f 6269 6e2f 7368 0a23 0a23 20c8 #! /bin/sh.#.# .
0000010: a1d6 f7c9 e8b1 b8ba c50a 2320 6361 7420 ..........# cat
-h
显示帮助信息
-i
以C语言数组形式显示,如果输入来自stdin,则有所区别
unsigned char scz_sh[] = {
0x23, 0x21, 0x20, 0x2f, 0x62, 0x69, 0x6e, 0x2f, 0x73, 0x68, 0x0a, 0x23,
0x0a, 0x23, 0x20, 0xc8, 0xa1, 0xd6, 0xf7, 0xc9, 0xe8, 0xb1, 0xb8, 0xba,
0xc5, 0x0a, 0x23, 0x20, 0x63, 0x61, 0x74, 0x20
};
unsigned int scz_sh_len = 32;
注意区分下面两条命令执行效果的不同
xxd -l 12 -i < scz.sh
0x23, 0x21, 0x20, 0x2f, 0x62, 0x69, 0x6e, 0x2f, 0x73, 0x68, 0x0a, 0x23
xxd -l 12 -i scz.sh
unsigned char scz_sh[] = {
0x23, 0x21, 0x20, 0x2f, 0x62, 0x69, 0x6e, 0x2f, 0x73, 0x68, 0x0a, 0x23
};
unsigned int scz_sh_len = 12;
-l len
只显示这么多字节
-p
以连续的16进制表示显示,比较下面的不同显示效果
xxd -u -l 32 scz.sh
0000000: 2321 202F 6269 6E2F 7368 0A23 0A23 20C8 #! /bin/sh.#.# .
0000010: A1D6 F7C9 E8B1 B8BA C50A 2320 6361 7420 ..........# cat
xxd -u -l 32 -p scz.sh
2321202F62696E2F73680A230A2320C8A1D6F7C9E8B1B8BAC50A23206361
7420
-r
reverse operation: convert (or patch) hexdump into binary.
If not writing to stdout, xxd writes into its output file without
truncating it. Use the combination -r -p to read plain hexadecimal
dumps without line number information and without a particular
column layout. Additional Whitespace and line-breaks are allowed
anywhere.
这个选项要用的话,一定要提前测试
-seek offset
When used after -r : revert with added to file positions
found in hexdump.
-s [+][-]seek
start at bytes abs. (or rel.) infile offset. + indicates
that the seek is relative to the current stdin file position
(meaningless when not reading from stdin). - indicates that the seek
should be that many characters from the end of the input (or if
combined with + : before the current stdin file position).
Without -s option, xxd starts at the current file position.
-u
采用大写16进制字母显示,缺省采用小写16进制字母
-v
显示版本信息
★ xxd使用中的注意事项
xxd -r has some builtin magic while evaluating line number information. If the ouput file
is seekable, then the linenumbers at the start of each hexdump line may be out of order,
lines may be missing, or overlapping. In these cases xxd will lseek(2) to the next position.
If the output file is not seekable, only gaps are allowed, which will be filled by null-
bytes.
xxd -r never generates parse errors. Garbage is silently skipped.
When editing hexdumps, please note that xxd -r skips everything on the input line after
reading enough columns of hexadecimal data (see option -c). This also means, that changes to
the printable ascii (or ebcdic) columns are always ignored. Reverting a plain (or
postscript) style hexdump with xxd -r -p does not depend on the correct number of columns.
Here an thing that looks like a pair of hex-digits is interpreted.
xxd -s +seek may be different from xxd -s seek , as lseek(2) is used to "rewind" input. A
'+' makes a difference if the input source is stdin, and if stdin's file position is not at
the start of the file by the time xxd is started and given its input. The following
examples may help to clarify (or further confuse!)...
Rewind stdin before reading; needed because the `cat' has already read to the end of stdin.
% sh -c 'cat > plain_copy; xxd -s 0 > hex_copy' < file
Hexdump from file position 0x480 (=1024+128) onwards. The `+' sign means "relative to the
current position", thus the `128' adds to the 1k where dd left off.
% sh -c 'dd of=plain_snippet bs=1k count=1; xxd -s +128 > hex_snippet' < file
Hexdump from file position 0x100 ( = 1024-768) on.
% sh -c 'dd of=plain_snippet bs=1k count=1; xxd -s +-768 > hex_snippet' < file
However, this is a rare situation and the use of `+' is rarely needed. the author prefers
to monitor the effect of xxd with strace(1) or truss(1), whenever -s is used.
★ xxd使用举例
.. 从偏移0x10开始显示,也就是缺省情况下的第一行不显示
xxd -s 0x10 scz.sh
.. 显示倒数0x30个字节(缺省情况下倒数3行)
xxd -s -0x30 -g 1 scz.sh
.. 显示120字节,连续显示,每行20字节
xxd -l 120 -p -c 20 scz.sh
.. 显示120字节,每行12字节
xxd -l 120 -c 12 -g 1 scz.sh
.. 显示0x6c偏移开始的12个字节
xxd -l 12 -c 12 -g 1 -s 0x6c scz.sh
.. 创建一个65537字节大小的文件,除了最后一个字节是'A',其余都是0x00
echo 10000: 41 | xxd -r > scz.txt
od -A x -t x1 scz.txt
000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
*
010000 41
010001
.. 使用autoskip选项
xxd -a scz.txt
0000000: 0000 0000 0000 0000 0000 0000 0000 0000 ................
*
0010000: 41 A
注意,缺省情况下autoskip功能是关闭的,但od看样子缺省就是打开的。
.. 创建只包含一个'A'字节的文件
echo '010000: 41' | xxd -r -s -0x10000 > scz_1
注意对比这些效果
echo '010: 41 42 43 44 45 46' | xxd -r -s 0 > scz_1
echo '010: 41 42 43 44 45 46' | xxd -r -s -0x10 > scz_1
等价于
echo '0: 41 42 43 44 45 46' | xxd -r -s 0 > scz_1
echo '010: 41 42 43 44 45 46' | xxd -r -s -0x12 > scz_1
执行的时候报错,xxd: sorry, cannot seek backwards.
echo '010: 41 42 43 44 45 46' | xxd -r -s 0x10 > scz_1
等价于
echo '020: 41 42 43 44 45 46' | xxd -r -s 0 > scz_1
.. 复制输入文件到输出文件,且给输出文件前部增加100字节的0x00
xxd scz_1 | xxd -r -s 100 > scz_2
od -A x -t x1 scz_2
000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
*
000060 00 00 00 00 41
000065
.. 二进制文件打补丁
echo '0: 41 42 43 44 45 46' | xxd -r -s 0 > scz_1
od -A x -t x1 scz_1
echo '4: 47 48' | xxd -r - scz_1
od -A x -t x1 scz_1
.. Use xxd as a filter within an editor such as vim(1) to hexdump a region
marked between `a' and `z'.
:'a,'z!xxd
.. Use xxd as a filter within an editor such as vim(1) to recover a
binary hexdump marked between `a' and `z'.
:'a,'z!xxd -r
.. Use xxd as a filter within an editor such as vim(1) to recover one line
of a hexdump. Move the cursor over the line and type:
!!xxd -r
.. Read single characters from a serial line
xxd -c1 < /dev/term/b &
stty < /dev/term/b -echo -opost -isig -icanon min 1
echo -n foo > /dev/term/b