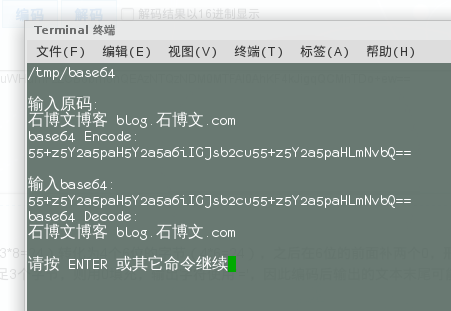
分类: C/C++
2014-09-14 21:36:09
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于2的6次方等于64,所以每6个位元为一个单元,对应某个可打印字符。三个字节有24个位元,对应于4个Base64单元,即3个字节需要用4个可打印字符来表示。它可用来作为电子邮件的传输编码。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9 ,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如uuencode的其他编码方法,和之后binhex的版本使用不同的64字符集来代表6个二进制数字,但是它们不叫Base64。Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据。
在MIME格式的电子邮件中,base64可以用来将binary的字节序列数据编码成ASCII字符序列构成的文本。使用时,在传输编码方式中指定base64。使用的字符包括大小写字母各26个,加上10个数字,和加号「+」,斜杠「/」,一共64个字符,等号「=」用来作为后缀用途。
编码后的数据比原始数据略长,为原来的\frac{4}{3}。在电子邮件中,根据RFC-822规定,每76个字符,还需要加上一个回车换行。可以估算编码后数据长度大约为原长的135.1%。
转换的时候,将三个byte的数据,先后放入一个24bit的缓冲区中,先来的byte占高位。数据不足3byte的话,缓冲区中剩下的bit用0补足。然后,每次取出6(因为2^6=64)个bit,按照其值选择ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/中的字符作为编码后的输出。不断进行,直到全部输入数据转换完成。
如果最后剩下两个输入数据,在编码结果后加1个「=」;如果最后剩下一个输入数据,编码结果后加2个「=」;如果没有剩下任何数据,就什么都不要加,这样才可以保证资料还原的正确性。
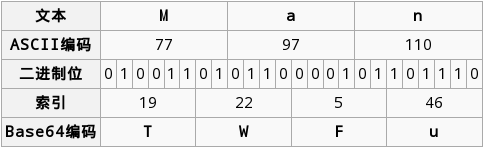
在此例中,Base64算法将三个字符编码为4个字符.
 Base64索引表
Base64索引表 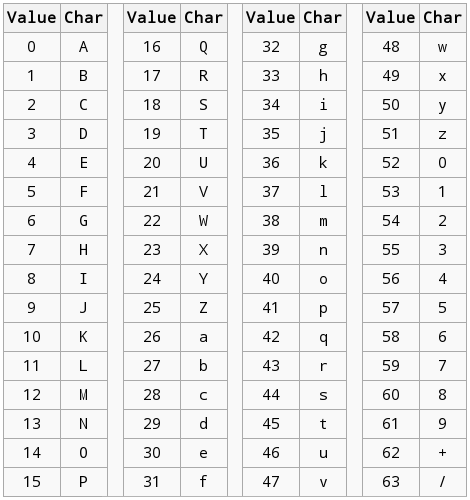
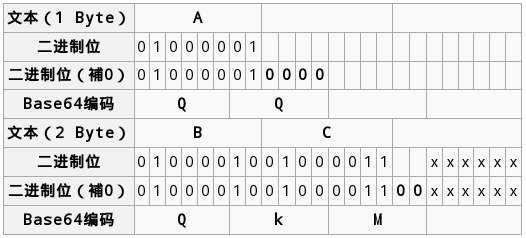
如果要编码的字节数不能被3整除,最后会多出1个或2个字节,那么可以使用下面的方法进行处理:先使用0字节值在末尾补足,使其能够被3整除,然后再进行base64的编码。在编码后的base64文本后加上一个或两个'='号,代表补足的字节数。也就是说,当最后剩余一个八位字节(一个byte)时,最后一个6位的base64字节块有四位是0值,最后附加上两个等号;如果最后剩余两个八位字节(2个byte)时,最后一个6位的base字节块有两位是0值,最后附加一个等号。 参考下表:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
/**
*
* base64 编码/解码 未进行任何数据检查
*
* */
#include
#include
#include
using namespace std;
static char encode[64]={'A','B','C','D','E','F','G','H','I','J','K','L','M','N',
'O','P','Q','R','S','T','U','V','W','X','Y','Z','a','b',
'c','d','e','f','g','h','i','j','k','l','m','n','o','p',
'q','r','s','t','u','v','w','x','y','z','0','1','2','3',
'4','5','6','7','8','9','+','/'};
static map
void initData(){
for (unsigned i(0);i!=64;++i){
decode[encode[i]]=i;
}
}
// base64编码,三变四
void encodeAppend(const string::const_iterator& it, string& str){
unsigned raw(((unsigned)*it & 0xff)<<16 |
((unsigned)*(it+1) & 0xff)<<8 |
((unsigned)*(it+2) & 0xff));
for (int i(18);i>=0;i-=6){
str+=encode[raw>>i & 63];
}
}
string& base64Encode(string strRaw,string& str){
str.clear();
// 补'='个数
unsigned plusEq(0);
// 补0到长度为3的倍数
while (strRaw.size() % 3){
strRaw+=(char)0;
++plusEq;
}
string::const_iterator it(strRaw.begin());
unsigned count(0);
while (it != strRaw.end()){
encodeAppend(it,str);
// 每76个字符换行,每次增加4个字符所以每19轮换行一次
if (++count%19 == 0){
str+='\n';
}
it+=3;
}
// 修改'='
while (plusEq){
str[str.size()-plusEq]='=';
--plusEq;
}
return str;
}
// base64解码,四变三
void decodeAppend(const string::const_iterator& it,string& str){
unsigned raw(decode[*it]<<18 |
decode[*(it+1)]<<12 |
decode[*(it+2)]<<6 |
decode[*(it+3)]);
for (int i(16);i>=0;i-=8){
str+=(char)(raw>>i);
}
}
string& base64Decode(const string& strRaw,string& str){
str.clear();
for (string::const_iterator it(strRaw.begin());it!=strRaw.end();it+=4){
decodeAppend(it,str);
}
return str;
}
int main(){
initData();
string strRaw,str;
cout<
getline(cin,strRaw);
cout<<"base64 Encode:"<
<
cout<
getline(cin,strRaw);
cout<<"base64 Decode:"<
<
return 0;
}
|
首先,建立encode和decode对应关系表,为后面编码解码准备.
在函数 encodeAppend 和 decodeAppend 中,分别完成了三个字符转四个字符,与四个字符还原三个字符,这是base64编码法的核心部分.
base64Encode 和 base64Decode 为算法的调用部分,完成了数据的初始化,切割等. 由于在这里没有作数据有效性检查,所以此代码在遇到畸形数据时会崩溃,实际应用前应该加上数据检查相关代码.