实践Linux的理论
全部博文(61)
分类: LINUX
2014-04-28 21:37:11
原文地址:<zz>Linux 字符设备驱动程序实现 作者:fj1161
一、主设备号和此设备号
主设备号表示设备对应的驱动程序;次设备号由内核使用,用于正确确定设备文件所指的设备。
内核用dev_t类型(
在实际使用中,是通过
|
(dev_t)-->主设备号、次设备号 |
MAJOR(dev_t dev) |
|
主设备号、次设备号-->(dev_t) |
MKDEV(int major,int minor) |
建立一个字符设备之前,驱动程序首先要做的事情就是获得设备编号。其这主要函数在
|
int register_chrdev_region(dev_t first, unsigned int count, |
分配之设备号的最佳方式是:默认采用动态分配,同时保留在加载甚至是编译时指定主设备号的余地。
以下是在scull.c中用来获取主设备好的代码:
|
if (scull_major) { |
在这部分中,比较重要的是在用函数获取设备编号后,其中的参数name是和该编号范围关联的设备名称,它将出现在/proc/devices和sysfs中。
看到这里,就可以理解为什么mdev和udev可以动态、自动地生成当前系统需要的设备文件。udev就是通过读取sysfs下的信息来识别硬件设备的.
(请看《理解和认识udev》
URL:http://blog.chinaunix.net/u/6541/showart_396425.html)


二、一些重要的数据结构
大部分基本的驱动程序操作涉及及到三个重要的内核数据结构,分别是file_operations、file和inode,它们的定义都在
file_operations
是一个函数指针的集合,标记式初始化允许结构成员重新排序; 在某种情况下, 真实的性能提高已经实现, 通过安放经常使用的成员的指针在相同硬件高速存储行中.
struct module *owner
第一个 file_operations 成员根本不是一个操作; 它是一个指向拥有这个结构的模块的指针. 这个成员用来在它的操作还在被使用时阻止模块被卸载. 几乎所有时间中, 它被简单初始化为 THIS_MODULE, 一个在
loff_t (*llseek) (struct file *, loff_t, int);
llseek 方法用作改变文件中的当前读/写位置, 并且新位置作为(正的)返回值. loff_t 参数是一个"long offset", 并且就算在 32位平台上也至少 64 位宽. 错误由一个负返回值指示. 如果这个函数指针是 NULL, seek 调用会以潜在地无法预知的方式修改 file 结构中的位置计数器( 在"file 结构" 一节中描述).
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
用来从设备中获取数据. 在这个位置的一个空指针导致 read 系统调用以 -EINVAL("Invalid argument") 失败. 一个非负返回值代表了成功读取的字节数( 返回值是一个 "signed size" 类型, 常常是目标平台本地的整数类型).
ssize_t (*aio_read)(struct kiocb *, char __user *, size_t, loff_t);
初始化一个异步读 -- 可能在函数返回前不结束的读操作. 如果这个方法是 NULL, 所有的操作会由 read 代替进行(同步地).
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
发送数据给设备. 如果 NULL, -EINVAL 返回给调用 write 系统调用的程序. 如果非负, 返回值代表成功写的字节数.
ssize_t (*aio_write)(struct kiocb *, const char __user *, size_t, loff_t *);
初始化设备上的一个异步写.
int (*readdir) (struct file *, void *, filldir_t);
对于设备文件这个成员应当为 NULL; 它用来读取目录, 并且仅对文件系统有用.
unsigned int (*poll) (struct file *, struct poll_table_struct *);
poll 方法是 3 个系统调用的后端: poll, epoll, 和 select, 都用作查询对一个或多个文件描述符的读或写是否会阻塞. poll 方法应当返回一个位掩码指示是否非阻塞的读或写是可能的, 并且, 可能地, 提供给内核信息用来使调用进程睡眠直到 I/O 变为可能. 如果一个驱动的 poll 方法为 NULL, 设备假定为不阻塞地可读可写.
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
ioctl 系统调用提供了发出设备特定命令的方法(例如格式化软盘的一个磁道, 这不是读也不是写). 另外, 几个 ioctl 命令被内核识别而不必引用 fops 表. 如果设备不提供 ioctl 方法, 对于任何未事先定义的请求(-ENOTTY, "设备无这样的 ioctl"), 系统调用返回一个错误.
int (*mmap) (struct file *, struct vm_area_struct *);
mmap 用来请求将设备内存映射到进程的地址空间. 如果这个方法是 NULL, mmap 系统调用返回 -ENODEV.
int (*open) (struct inode *, struct file *);
尽管这常常是对设备文件进行的第一个操作, 不要求驱动声明一个对应的方法. 如果这个项是 NULL, 设备打开一直成功, 但是你的驱动不会得到通知.
int (*flush) (struct file *);
flush 操作在进程关闭它的设备文件描述符的拷贝时调用; 它应当执行(并且等待)设备的任何未完成的操作. 这个必须不要和用户查询请求的 fsync 操作混淆了. 当前, flush 在很少驱动中使用; SCSI 磁带驱动使用它, 例如, 为确保所有写的数据在设备关闭前写到磁带上. 如果 flush 为 NULL, 内核简单地忽略用户应用程序的请求.
int (*release) (struct inode *, struct file *);
在文件结构被释放时引用这个操作. 如同 open, release 可以为 NULL.
int (*fsync) (struct file *, struct dentry *, int);
这个方法是 fsync 系统调用的后端, 用户调用来刷新任何挂着的数据. 如果这个指针是 NULL, 系统调用返回 -EINVAL.
int (*aio_fsync)(struct kiocb *, int);
这是 fsync 方法的异步版本.
int (*fasync) (int, struct file *, int);
这个操作用来通知设备它的 FASYNC 标志的改变. 异步通知是一个高级的主题, 在第 6 章中描述. 这个成员可以是NULL 如果驱动不支持异步通知.
int (*lock) (struct file *, int, struct file_lock *);
lock 方法用来实现文件加锁; 加锁对常规文件是必不可少的特性, 但是设备驱动几乎从不实现它.
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
这些方法实现发散/汇聚读和写操作. 应用程序偶尔需要做一个包含多个内存区的单个读或写操作; 这些系统调用允许它们这样做而不必对数据进行额外拷贝. 如果这些函数指针为 NULL, read 和 write 方法被调用( 可能多于一次 ).
ssize_t (*sendfile)(struct file *, loff_t *, size_t, read_actor_t, void *);
这个方法实现 sendfile 系统调用的读, 使用最少的拷贝从一个文件描述符搬移数据到另一个. 例如, 它被一个需要发送文件内容到一个网络连接的 web 服务器使用. 设备驱动常常使 sendfile 为 NULL.
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
sendpage 是 sendfile 的另一半; 它由内核调用来发送数据, 一次一页, 到对应的文件. 设备驱动实际上不实现 sendpage.
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
这个方法的目的是在进程的地址空间找一个合适的位置来映射在底层设备上的内存段中. 这个任务通常由内存管理代码进行; 这个方法存在为了使驱动能强制特殊设备可能有的任何的对齐请求. 大部分驱动可以置这个方法为 NULL.[ ]
int (*check_flags)(int)
这个方法允许模块检查传递给 fnctl(F_SETFL...) 调用的标志.
int (*dir_notify)(struct file *, unsigned long);
这个方法在应用程序使用 fcntl 来请求目录改变通知时调用. 只对文件系统有用; 驱动不需要实现 dir_notify.
struct file_operations scull_fops = {
.owner = THIS_MODULE,
.llseek = scull_llseek,
.read = scull_read,
.write = scull_write,
.ioctl = scull_ioctl,
.open = scull_open,
.release = scull_release,
};
文件结构
struct file, 定义于
在内核源码中, struct file 的指针常常称为 file 或者 filp("file pointer"). 我们将一直称这个指针为 filp 以避免和结构自身混淆. 因此, file 指的是结构, 而 filp 是结构指针.
struct file 的最重要成员在这展示. 如同在前一节, 第一次阅读可以跳过这个列表. 但是, 在本章后面, 当我们面对一些真实 C 代码时, 我们将更详细讨论这些成员.
mode_t f_mode;
文件模式确定文件是可读的或者是可写的(或者都是), 通过位 FMODE_READ 和 FMODE_WRITE. 你可能想在你的 open 或者 ioctl 函数中检查这个成员的读写许可, 但是你不需要检查读写许可, 因为内核在调用你的方法之前检查. 当文件还没有为那种存取而打开时读或写的企图被拒绝, 驱动甚至不知道这个情况.
loff_t f_pos;
当前读写位置. loff_t 在所有平台都是 64 位( 在 gcc 术语里是 long long ). 驱动可以读这个值, 如果它需要知道文件中的当前位置, 但是正常地不应该改变它; 读和写应当使用它们作为最后参数而收到的指针来更新一个位置, 代替直接作用于 filp->f_pos. 这个规则的一个例外是在 llseek 方法中, 它的目的就是改变文件位置.
unsigned int f_flags;
这些是文件标志, 例如 O_RDONLY, O_NONBLOCK, 和 O_SYNC. 驱动应当检查 O_NONBLOCK 标志来看是否是请求非阻塞操作( 我们在第一章的"阻塞和非阻塞操作"一节中讨论非阻塞 I/O ); 其他标志很少使用. 特别地, 应当检查读/写许可, 使用 f_mode 而不是 f_flags. 所有的标志在头文件
struct file_operations *f_op;
和文件关联的操作. 内核安排指针作为它的 open 实现的一部分, 接着读取它当它需要分派任何的操作时. filp->f_op 中的值从不由内核保存为后面的引用; 这意味着你可改变你的文件关联的文件操作, 在你返回调用者之后新方法会起作用. 例如, 关联到主编号 1 (/dev/null, /dev/zero, 等等)的 open 代码根据打开的次编号来替代 filp->f_op 中的操作. 这个做法允许实现几种行为, 在同一个主编号下而不必在每个系统调用中引入开销. 替换文件操作的能力是面向对象编程的"方法重载"的内核对等体.
void *private_data;
open 系统调用设置这个指针为 NULL, 在为驱动调用 open 方法之前. 你可自由使用这个成员或者忽略它; 你可以使用这个成员来指向分配的数据, 但是接着你必须记住在内核销毁文件结构之前, 在 release 方法中释放那个内存. private_data 是一个有用的资源, 在系统调用间保留状态信息, 我们大部分例子模块都使用它.
struct dentry *f_dentry;
关联到文件的目录入口( dentry )结构. 设备驱动编写者正常地不需要关心 dentry 结构, 除了作为 filp->f_dentry->d_inode 存取 inode 结构.
真实结构有多几个成员, 但是它们对设备驱动没有用处. 我们可以安全地忽略这些成员, 因为驱动从不创建文件结构; 它们真实存取别处创建的结构.
inode 结构
inode 结构由内核在内部用来表示文件. 因此, 它和代表打开文件描述符的文件结构是不同的. 可能有代表单个文件的多个打开描述符的许多文件结构, 但是它们都指向一个单个 inode 结构.
inode 结构包含大量关于文件的信息. 作为一个通用的规则, 这个结构只有 2 个成员对于编写驱动代码有用:
dev_t i_rdev;
对于代表设备文件的节点, 这个成员包含实际的设备编号.
struct cdev *i_cdev;
struct cdev 是内核的内部结构, 代表字符设备; 这个成员包含一个指针, 指向这个结构, 当节点指的是一个字符设备文件时.
i_rdev 类型在 2.5 开发系列中改变了, 破坏了大量的驱动. 作为一个鼓励更可移植编程的方法, 内核开发者已经增加了 2 个宏, 可用来从一个 inode 中获取主次编号:
unsigned int iminor(struct inode *inode);
unsigned int imajor(struct inode *inode);
为了不要被下一次改动抓住, 应当使用这些宏代替直接操作 i_rdev.


三、字符设备的注册
内核内部使用struct cdev结构来表示字符设备。在内核调用设备的操作之前,必须分配并注册一个或多个struct cdev。代码应包含
注册一个独立的cdev设备的基本过程如下:
1、为struct cdev 分配空间(如果已经将struct cdev 嵌入到自己的设备的特定结构体中,并分配了空间,这步略过!)
struct cdev *my_cdev = cdev_alloc();
my_cdev->ops=&my_ops;
2、初始化struct cdev
void cdev_init(struct cdev *cdev, const struct file_operations *fops)
3、初始化cdev.owner
cdev.owner = THIS_MODULE;
4、cdev设置完成,通知内核struct cdev的信息(在执行这步之前必须确定你对struct cdev的以上设置已经完成!)
int cdev_add(struct cdev *p, dev_t dev, unsigned count)
这里, dev 是 cdev 结构, num 是这个设备响应的第一个设备号, count 是应当关联到设备的设备号的数目. 常常 count 是 1, 但是有多个设备号对应于一个特定的设备的情形. 例如, 设想 SCSI 磁带驱动, 它允许用户空间来选择操作模式(例如密度), 通过安排多个次编号给每一个物理设备.
在使用 cdev_add 是有几个重要事情要记住. 第一个是这个调用可能失败. 如果它返回一个负的错误码, 你的设备没有增加到系统中. 它几乎会一直成功, 但是, 并且带起了其他的点: cdev_add 一返回, 你的设备就是"活的"并且内核可以调用它的操作. 除非你的驱动完全准备好处理设备上的操作, 你不应当调用 cdev_add.
5、从系统中移除一个字符设备:void cdev_del(struct cdev *p)
以下是scull中的初始化代码(之前已经为struct scull_dev 分配了空间):
|
/* |
老方法
如果你深入浏览 2.6 内核的大量驱动代码, 你可能注意到有许多字符驱动不使用我们刚刚描述过的 cdev 接口. 你见到的是还没有更新到 2.6 内核接口的老代码. 因为那个代码实际上能用, 这个更新可能很长时间不会发生. 为完整, 我们描述老的字符设备注册接口, 但是新代码不应当使用它; 这个机制在将来内核中可能会消失.
注册一个字符设备的经典方法是使用:
int register_chrdev(unsigned int major, const char *name, struct file_operations *fops);
这里, major 是感兴趣的主编号, name 是驱动的名子(出现在 /proc/devices), fops 是缺省的 file_operations 结构. 一个对 register_chrdev 的调用为给定的主编号注册 0 - 255 的次编号, 并且为每一个建立一个缺省的 cdev 结构. 使用这个接口的驱动必须准备好处理对所有 256 个次编号的 open 调用( 不管它们是否对应真实设备 ), 它们不能使用大于 255 的主或次编号.
如果你使用 register_chrdev, 从系统中去除你的设备的正确的函数是:
int unregister_chrdev(unsigned int major, const char *name);
major 和 name 必须和传递给 register_chrdev 的相同, 否则调用会失败.


四、scull模型的内存使用
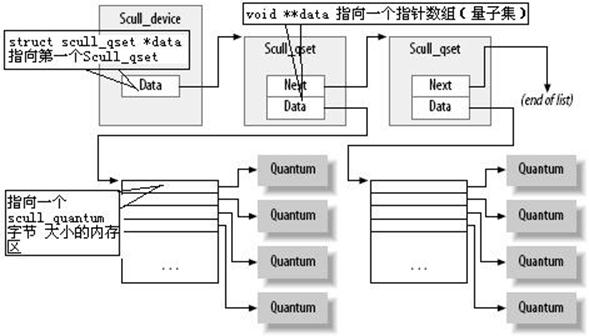
以下是scull模型的结构体:
|
/* |
scull驱动程序引入了两个Linux内核中用于内存管理的核心函数,它们的定义都在
|
void *kmalloc(size_t size, int flags); |
以下是scull模块中的一个释放整个数据区的函数(类似清零),将在scull以写方式打开和scull_cleanup_module中被调用:
|
int scull_trim(struct scull_dev *dev) |
以下是scull模块中的一个沿链表前行得到正确scull_set指针的函数,将在read和write方法中被调用:
|
/*Follow the list*/ |
其实这个函数的实质是:如果已经存在这个scull_set,就返回这个scull_set的指针。如果不存在这个scull_set,一边沿链表为scull_set分配空间一边沿链表前行,直到所需要的scull_set被分配到空间并初始化为止,就返回这个scull_set的指针。


五、open和release
open方法提供给驱动程序以初始化的能力,为以后的操作作准备。应完成的工作如下:
(1)检查设备特定的错误(如设备未就绪或硬件问题);
(2)如果设备是首次打开,则对其进行初始化;
(3)如有必要,更新f_op指针;
(4)分配并填写置于filp->private_data里的数据结构。
int (*open)(struct inode *inode, struct file *filp);
inode 参数有我们需要的信息,以它的 i_cdev 成员的形式, 里面包含我们之前建立的 cdev 结构. 唯一的问题是通常我们不想要 cdev 结构本身, 我们需要的是包含 cdev 结构的 scull_dev 结构. C 语言使程序员玩弄各种技巧来做这种转换; 但是, 这种技巧编程是易出错的, 并且导致别人难于阅读和理解代码. 幸运的是, 在这种情况下, 内核 hacker 已经为我们实现了这个技巧, 以 container_of 宏的形式, 在
而根据scull的实际情况,他的open函数只要完成第四步(将初始化过的struct scull_dev dev的指针传递到filp->private_data里,以备后用)就好了,所以open函数很简单。但是其中用到了定义在
|
#define container_of(ptr, type, member) ({ \ |
其实从源码可以看出,其作用就是:通过指针ptr,获得包含ptr所指向数据(是member结构体)的type结构体的指针。即是用指针得到另外一个指针。
这个宏使用一个指向 container_field 类型的成员的指针, 它在一个 container_type 类型的结构中, 并且返回一个指针指向包含结构. 在 scull_open, 这个宏用来找到适当的设备结构:
struct scull_dev *dev; /* device information */ dev = container_of(inode->i_cdev, struct scull_dev, cdev); filp->private_data = dev; /* for other methods */
一旦它找到 scull_dev 结构, scull 在文件结构的 private_data 成员中存储一个它的指针, 为以后更易存取.
识别打开的设备的另外的方法是查看存储在 inode 结构的次编号. 如果你使用 register_chrdev 注册你的设备, 你必须使用这个技术. 确认使用 iminor 从 inode 结构中获取次编号, 并且确定它对应一个你的驱动真正准备好处理的设备.
scull_open 的代码(稍微简化过)是:
int scull_open(struct inode *inode, struct file *filp) {
struct scull_dev *dev; /* device information */
dev = container_of(inode->i_cdev, struct scull_dev, cdev);
filp->private_data = dev;/* for other methods */
/* now trim to 0 the length of the device if open was write-only */
if ( (filp->f_flags & O_ACCMODE) == O_WRONLY) { scull_trim(dev); /* ignore errors */ } return 0; /* success */ }
release方法提供释放内存,关闭设备的功能。应完成的工作如下:
(1)释放由open分配的、保存在file->private_data中的所有内容;
(2)在最后一次关闭操作时关闭设备。
由于前面定义了scull是一个全局且持久的内存区,所以他的release什么都不做。
int scull_release(struct inode *inode, struct file *filp) { return 0; }


六、read和write
read和write方法的主要作用就是实现内核与用户空间之间的数据拷贝。
ssize_t read(struct file *filp, char __user *buff, size_t count, loff_t *offp);
ssize_t write(struct file *filp, const char __user *buff, size_t count, loff_t *offp);
对于 2 个方法, filp 是文件指针, count 是请求的传输数据大小. buff 参数指向持有被写入数据的缓存, 或者放入新数据的空缓存. 最后, offp 是一个指针指向一个"long offset type"对象, 它指出用户正在存取的文件位置. 返回值是一个"signed size type"; 它的使用在后面讨论.
让我们重复一下, read 和 write 方法的 buff 参数是用户空间指针. 因此, 它不能被内核代码直接解引用.这个限制有几个理由:
依赖于你的驱动运行的体系, 以及内核被如何配置的, 用户空间指针当运行于内核模式可能根本是无效的. 可能没有那个地址的映射, 或者它可能指向一些其他的随机数据.
就算这个指针在内核空间是同样的东西, 用户空间内存是分页的, 在做系统调用时这个内存可能没有在 RAM 中. 试图直接引用用户空间内存可能产生一个页面错, 这是内核代码不允许做的事情. 结果可能是一个"oops", 导致进行系统调用的进程死亡.
置疑中的指针由一个用户程序提供, 它可能是错误的或者恶意的. 如果你的驱动盲目地解引用一个用户提供的指针, 它提供了一个打开的门路使用户空间程序存取或覆盖系统任何地方的内存. 如果你不想负责你的用户的系统的安全危险, 你就不能直接解引用用户空间指针.
因为Linux的内核空间和用户空间隔离的,所以要实现数据拷贝就必须使用在
|
unsigned long copy_to_user(void __user *to, |
而值得一提的是以上两个函数和
|
#define __copy_from_user(to,from,n) (memcpy(to, (void __force *)from, n), 0) |
之间的关系:通过源码可知,前者调用后者,但前者在调用前对用户空间指针进行了检查。
这 2 个函数的角色不限于拷贝数据到和从用户空间: 它们还检查用户空间指针是否有效. 如果指针无效, 不进行拷贝; 如果在拷贝中遇到一个无效地址, 另一方面, 只拷贝部分数据. 在 2 种情况下, 返回值是还要拷贝的数据量. scull 代码查看这个错误返回, 并且如果它不是 0 就返回 -EFAULT 给用户.
至于实际的设备方法, read 方法的任务是从设备拷贝数据到用户空间(使用 copy_to_user), 而 write 方法必须从用户空间拷贝数据到设备(使用 copy_from_user). 每个 read 或 write 系统调用请求一个特定数目字节的传送, 但是驱动可自由传送较少数据 -- 对读和写这确切的规则稍微不同, 在本章后面描述.
不管这些方法传送多少数据, 它们通常应当更新 *offp 中的文件位置来表示在系统调用成功完成后当前的文件位置. 内核接着在适当时候传播文件位置的改变到文件结构. pread 和 pwrite 系统调用有不同的语义; 它们从一个给定的文件偏移操作, 并且不改变其他的系统调用看到的文件位置. 这些调用传递一个指向用户提供的位置的指针, 并且放弃你的驱动所做的改变.
read方法
read 的返回值由调用的应用程序解释:
如果这个值等于传递给 read 系统调用的 count 参数, 请求的字节数已经被传送. 这是最好的情况.
如果是正数, 但是小于 count, 只有部分数据被传送. 这可能由于几个原因, 依赖于设备. 常常, 应用程序重新试着读取. 例如, 如果你使用 fread 函数来读取, 库函数重新发出系统调用直到请求的数据传送完成.
如果值为 0, 到达了文件末尾(没有读取数据).
一个负值表示有一个错误. 这个值指出了什么错误, 根据
前面列表中漏掉的是这种情况"没有数据, 但是可能后来到达". 在这种情况下, read 系统调用应当阻塞.
ssize_t scull_read(struct file *filp, char __user *buf, size_t count, loff_t *f_pos)
{
struct scull_dev *dev = filp->private_data;
struct scull_qset *dptr; /* the first listitem */
int quantum = dev->quantum, qset = dev->qset;
int itemsize = quantum * qset; /* how many bytes in the listitem */
int item, s_pos, q_pos, rest;
ssize_t retval = 0;
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
if (*f_pos >= dev->size)
goto out;
if (*f_pos + count > dev->size)
count = dev->size - *f_pos;
/* find listitem, qset index, and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum;
q_pos = rest % quantum;
/* follow the list up to the right position (defined elsewhere) */
dptr = scull_follow(dev, item);
if (dptr == NULL || !dptr->data || ! dptr->data[s_pos])
goto out; /* don't fill holes */
/* read only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_to_user(buf, dptr->data[s_pos] + q_pos, count))
{
retval = -EFAULT;
goto out;
}
*f_pos += count;
retval = count;
out:
up(&dev->sem);
return retval;
}
write, 象 read, 可以传送少于要求的数据, 根据返回值的下列规则:
如果值等于 count, 要求的字节数已被传送.
如果正值, 但是小于 count, 只有部分数据被传送. 程序最可能重试写入剩下的数据.
如果值为 0, 什么没有写. 这个结果不是一个错误, 没有理由返回一个错误码. 再一次, 标准库重试写调用. 我们将在第 6 章查看这种情况的确切含义, 那里介绍了阻塞.
一个负值表示发生一个错误; 如同对于读, 有效的错误值是定义于
不幸的是, 仍然可能有发出错误消息的不当行为程序, 它在进行了部分传送时终止. 这是因为一些程序员习惯看写调用要么完全失败要么完全成功, 这实际上是大部分时间的情况, 应当也被设备支持. scull 实现的这个限制可以修改, 但是我们不想使代码不必要地复杂.
write 的 scull 代码一次处理单个量子, 如 read 方法做的:
ssize_t scull_write(struct file *filp, const char __user *buf, size_t count, loff_t *f_pos)
{
struct scull_dev *dev = filp->private_data;
struct scull_qset *dptr;
int quantum = dev->quantum, qset = dev->qset;
int itemsize = quantum * qset;
int item, s_pos, q_pos, rest;
ssize_t retval = -ENOMEM; /* value used in "goto out" statements */
if (down_interruptible(&dev->sem))
return -ERESTARTSYS;
/* find listitem, qset index and offset in the quantum */
item = (long)*f_pos / itemsize;
rest = (long)*f_pos % itemsize;
s_pos = rest / quantum;
q_pos = rest % quantum;
/* follow the list up to the right position */
dptr = scull_follow(dev, item);
if (dptr == NULL)
goto out;
if (!dptr->data)
{
dptr->data = kmalloc(qset * sizeof(char *), GFP_KERNEL);
if (!dptr->data)
goto out;
memset(dptr->data, 0, qset * sizeof(char *));
}
if (!dptr->data[s_pos])
{
dptr->data[s_pos] = kmalloc(quantum, GFP_KERNEL);
if (!dptr->data[s_pos])
goto out;
}
/* write only up to the end of this quantum */
if (count > quantum - q_pos)
count = quantum - q_pos;
if (copy_from_user(dptr->data[s_pos]+q_pos, buf, count))
{
retval = -EFAULT;
goto out;
}
*f_pos += count;
retval = count;
/* update the size */
if (dev->size < *f_pos)
dev->size = *f_pos;
out:
up(&dev->sem);
return retval;
}
readv 和 writev
Unix 系统已经长时间支持名为 readv 和 writev 的 2 个系统调用. 这些 read 和 write 的"矢量"版本使用一个结构数组, 每个包含一个缓存的指针和一个长度值. 一个 readv 调用被期望来轮流读取指示的数量到每个缓存. 相反, writev 要收集每个缓存的内容到一起并且作为单个写操作送出它们.
如果你的驱动不提供方法来处理矢量操作, readv 和 writev 由多次调用你的 read 和 write 方法来实现. 在许多情况, 但是, 直接实现 readv 和 writev 能获得更大的效率.
矢量操作的原型是:
ssize_t (*readv) (struct file *filp, const struct iovec *iov, unsigned long count, loff_t *ppos);
ssize_t (*writev) (struct file *filp, const struct iovec *iov, unsigned long count, loff_t *ppos);
这里, filp 和 ppos 参数与 read 和 write 的相同. iovec 结构, 定义于
struct iovec
{
void __user *iov_base; __kernel_size_t iov_len;
};
每个 iovec 描述了一块要传送的数据; 它开始于 iov_base (在用户空间)并且有 iov_len 字节长. count 参数告诉有多少 iovec 结构. 这些结构由应用程序创建, 但是内核在调用驱动之前拷贝它们到内核空间.
矢量操作的最简单实现是一个直接的循环, 只是传递出去每个 iovec 的地址和长度给驱动的 read 和 write 函数. 然而, 有效的和正确的行为常常需要驱动更聪明. 例如, 一个磁带驱动上的 writev 应当将全部 iovec 结构中的内容作为磁带上的单个记录.
很多驱动, 但是, 没有从自己实现这些方法中获益. 因此, scull 省略它们. 内核使用 read 和 write 来模拟它们, 最终结果是相同的.
七、模块实验
这次模块实验的使用是友善之臂SBC2440V4,使用Linux2.6.22.2内核。
模块程序链接:scull模块源程序
模块测试程序链接:模块测试程序
|
量子大小为6: [Tekkaman2440@SBC2440V4]#cd /lib/modules/ [Tekkaman2440@SBC2440V4]#insmod scull.ko scull_quantum=6 [Tekkaman2440@SBC2440V4]#cat /proc/devices
启动测试程序 [Tekkaman2440@SBC2440V4]#./scull_test write error! code=6 write error! code=6 write error! code=6 write ok! code=2 read error! code=6 read error! code=6 read error! code=6 read ok! code=2 [0]=0 [1]=1 [2]=2 [3]=3 [4]=4 [5]=5 [6]=6 [7]=7 [8]=8 [9]=9 [10]=10 [11]=11 [12]=12 [13]=13 [14]=14 [15]=15 [16]=16 [17]=17 [18]=18 [19]=19
改变量子大小为默认值4000: 启动测试程序 改变量子大小为6,量子集大小为2: 启动测试程序 |
实验不仅测试了模块的读写能力,还测试了量子读写是否有效。










