久久不能释怀!
分类: Web开发
2014-12-09 10:13:56
每种数据类型都有一个与之相关的队列,这个队列是由处理器架构而非这个语言本身授权的。校准数据元素允许处理器以高效的方式从内存中抓取数据,并由 此提高性能。为了提供最佳的性能,编译器试图保持这种数据元素的队列。在32位和64位的Linux系统上,英特尔?C++编译器上使用着的数据类型典型 对齐要求如下:
|
Data Type |
32-bit(bytes) |
64-bit(bytes) |
|
char |
1 |
1 |
|
short |
2 |
2 |
|
int |
4 |
4 |
|
long |
8 |
8 |
|
float |
4 |
4 |
|
double |
8 |
8 |
|
long long |
8 |
8 |
|
long double |
4 |
16 |
|
Any pointer |
4 |
8 |
一般情况下,编译器会在任何可能的时候都满足这些数据元素的对齐要求。在使用英特尔?C++和Fortran编译器的情况下,可以使用 -align(C/C++,Fortran语言)编译器开关来强制或禁止自然对齐规则。对于通常含有不同类型的数据元素的结构,编译器试图通过在元素之间 插入未使用的存储来保持的数据元素实现正确对齐。这种技术被称为“填充”。此外,编译器还会以它的最严格的对准成员为基准来对齐整个结构。编译器也可能会 增加结构的空间大小,必要的时候,编译器会通过在结构端部添加填充的方式来使其实现成倍的对齐。这就是所谓的“尾填充”。如此一来,填充就医浪费存储空间 的代价提升了性能。如果是英特尔?至强融核?协处理器,提供给应用程序可用存储的数量本身是有限的,这会带来一个严重的问题。
开发者可以通过给结构元素排序来最小化这种内存浪费,这样最大/最宽的元素会排在前面,接着是第二宽的,依次排开。下面的这个例子能为你阐明用结构的空间大小给数据元素排序影响:
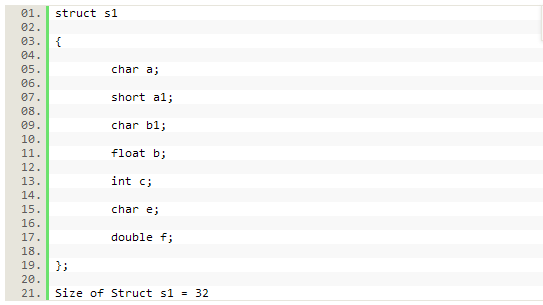
结构s1有11个填充字节,如下表所示:

看看下面的结构s2:
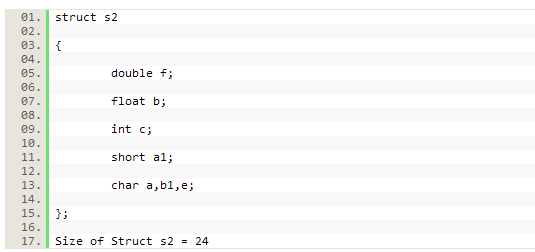
这个结构只包含了3个尾填充的字节,如下图所示:

这样就节省了内存。因此,仅仅在结构定义中重排数据元素就有可能避免内存浪费。
这种给元素排序的一种例外是,如果你的结构比你的高速缓存线(在因特尔至强融核协处理器上是64个字节)更大的话,一些循环或内核就只能接触到结构的一部分。在这种情况下,保持结构的各部分能在内存中一起被接触到可能是有益的,这可能会改善高速缓存局部性。
如果你的结构比高速缓存线更大,并且一些循环和内核只能接触到结构的一部分的话,你可以考虑下通过把大结构分解为多个以单独的排列存储的更小的结构。这就潜在地提升了可接触数据的密度,incident提升了高速缓存的局部性。
你也可以使用_decipsec(align)属性来指导编译器比用其他方式更严格地对齐数据,这个扩展属性的语法如下:
C/C++:
_decipsec(align(n))<数据类型声明>
Fortran:
cDEC$ATRIBUTES ALIGN:n::<数据类型声明>
这里的n是要求的队列,是2的乘幂,在英特尔C++编译器里最大为4096,在英特尔Fortran编译器里最大是16384.你可以使用这个属性 为单个变量,静态结构或自动存储持续期间内请求对齐。然而,这就表示,尽管你提高结构的一致性,但这个属性并不能调整结构内元素的对齐。通过把 _declpsec(align)放在关键字struct前面,你就为仅仅这种类型的对象请求适当的对齐。让我用下面这个例子来说明我的观点:
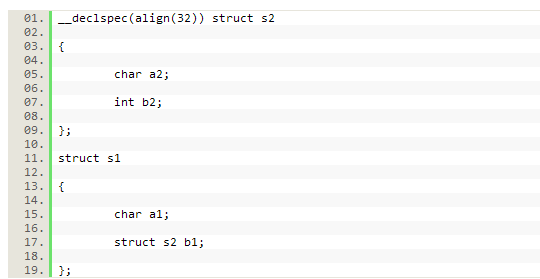
在上述示例中,对字符a2和整数b2的对齐仍然各自保持为1个字节和4个字节,这是默认的。然而,结构s2的每个实例都被对齐到32个字节的边界,正如_declspsec声明里描述的那样。因此,结构s1内部的结构s2目前的每个实例都将对齐到32个字节的边界。
我们还可以通过动态分配结构s2的排列来进一步扩展这个例子:

这种情况下,你仍然需要使用_mm_malloc或一个相当于为指针分配对齐内存的可移植性操作系统接口(POSIX),但通过使用_declspec(align(32)),你就是要为排列arr1中的每一个元素都强制对齐到32个字节。
你也可以使用这个数据对齐支持来为高速缓存线使用最优化提供优势。通过把平常经常在一起使用的小对象聚集到一个结构里,并强制这个结构从高速缓存线 的起始端分配内存,你就能有效地保证每一个对象在需要的时候都能及时地被装载进高速缓存里,这样会有很明显的性能提升。例如,考虑i和j这两个被频繁调用 的变量,他们可能会被分配到不同的告诉缓存线上。你可以像下面这么来声明它们:

通过使用这种方式声明变量,编译器就能确保这些变量被分配在同一个高速缓存线上。
慧都提供,各种IDE低至半价出售(截止日期2014/12/31)。和
