全部博文(573)
分类: LINUX
2018-04-18 10:20:14
linux成功的关键因素之一就是它与其他操作系统和谐共存的能力,在linux下可以安装挂载很多格式的文件系统,之所以能实现就是通过虚拟文件系统这一中间系统层,虚拟文件系统的主要思想是引入了一个通用文件模型,它能够表示所有的文件系统,这也要求,具体文件系统的实现中需要给VFS提供相应的物理组织结构。
通用文件模型有4大对象模型:超级块对象 索引节点对象 目录项对象 文件对象
要注意的是,在VFS看来,超级块以及索引节点是存在于实际物理磁盘的,而目录项和文件对象是VFS在内存中创建的结构,这里也预示着超级块对象和索引节点对象存在这个内存和物理磁盘的同步问题。
这里也说明在VFS看来,实际的物理磁盘除了实际数据外,应该还有超级块和索引节点表,当然这个我们可以在具体文件系统的实现来实现,因为不是所有的文件系统在物理磁盘上有超级块和索引节点表的。
我们首先从空间上来一一介绍VFS这4大对象模型:
1.superblock
1)superblock简介
超级块用来描述特定文件系统的信息。物理的超级块存放在磁盘特定的扇区中 ,分区被mount时将会读取磁盘superblock信息存在于内存中,也就是VFS的超级块对象。VFS超级块是各种具体文件系统在安装时建立的,并在这些文件系统卸载时被自动删除 。超级块对象由结构体 super_block来体现。
VFS中超级块对象的数据结构如下:
1318struct super_block {
1319 struct list_head s_list; // 超级快链表指针
1320 dev_t s_dev; // 设备表示符
1321 unsigned char s_dirt; //脏标志
1322 unsigned char s_blocksize_bits; //以位为单位的块的大小
1323 unsigned long s_blocksize; //以字节为单位的块大小
1324 loff_t s_maxbytes; //文件大小上限
1325 struct file_system_type *s_type; //指向文件系统的file_system_type 数据结构的指针
1326 const struct super_operations *s_op; //超级块方法
1327 const struct dquot_operations *dq_op; //磁盘限额方法
1328 const struct quotactl_ops *s_qcop; //限额控制方法
1329 const struct export_operations *s_export_op; //导出方法
1330 unsigned long s_flags; //登录标志
1331 unsigned long s_magic; //文件系统的魔数
1332 struct dentry *s_root; //目录登录点
1333 struct rw_semaphore s_umount; //卸载信号量
1334 struct mutex s_lock; //超级块信号量
1335 int s_count; //超级块引用计数
1336 atomic_t s_active; //活动引用记数
1337#ifdef CONFIG_SECURITY
1338 void *s_security; //安全模块
1339#endif
1340 const struct xattr_handler **s_xattr;
1341
1342 struct list_head s_inodes; //把所有索引对象链接在一起,存放的是头结点
1343 struct hlist_head s_anon; //匿名目录项
1344#ifdef CONFIG_SMP
1345 struct list_head __percpu *s_files;
1346#else
1347 struct list_head s_files; //链接所有打开的文件。
1348#endif
1349 /* s_dentry_lru and s_nr_dentry_unused are protected by dcache_lock */
1350 struct list_head s_dentry_lru; /* unused dentry lru */
1351 int s_nr_dentry_unused; /* # of dentry on lru */
1352
1353 struct block_device *s_bdev; //相关的块设备
1354 struct backing_dev_info *s_bdi;
1355 struct mtd_info *s_mtd;
1356 struct list_head s_instances; //该类型文件系统
1357 struct quota_info s_dquot; //限额相关选项
1358
1359 int s_frozen;
1360 wait_queue_head_t s_wait_unfrozen;
1361
1362 char s_id[32]; //文本名字
1363
1364 void *s_fs_info; //文件系统特设信息
1365 fmode_t s_mode;
1366
1367 /* Granularity of c/m/atime in ns.
1368 Cannot be worse than a second */
1369 u32 s_time_gran;
1370
1371 /*
1372 * The next field is for VFS *only*. No filesystems have any business
1373 * even looking at it. You had been warned.
1374 */
1375 struct mutex s_vfs_rename_mutex; /* Kludge */
1376
1377 /*
1378 * Filesystem subtype. If non-empty the filesystem type field
1379 * in /proc/mounts will be "type.subtype"
1380 */
1381 char *s_subtype;
1382
1383 /*
1384 * Saved mount options for lazy filesystems using
1385 * generic_show_options()
1386 */
1387 char *s_options;
1388};
我们先看一下内核中superblock的关系图:
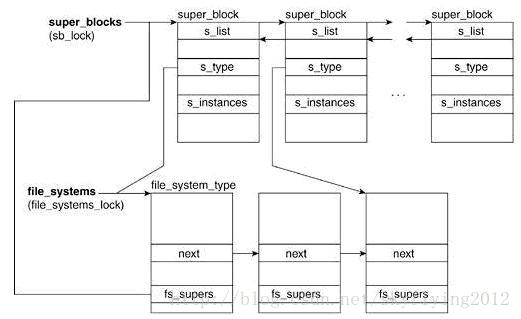
1.s_list :所有的超级块形成一个双联表,s_list.prev和s_list.next分别指向与当前超级块相邻的前一个元素和后一个元素。通常我们通过list_entry宏来获取s_list所在超级块结构体的地址(超级块对像是以双向链表的形式链接在一起的)。
2. s_lock :保护链表免受多处理器系统上的同时访问。
3.s_fs_info: 字段指向具体文件系统的超级块。
例如:超级块对象指的是Ext2文件系统,该字段就指向ext2_sb_info数据结构。
4.s_dirt :来表示该超级块是否是脏的,也就是说,磁盘上的数据是否必须要更新。
5.超级块对象是通过函数alloc_super()创建并初始化的。在文件系统安装时,内核会调用该函数以便从磁盘读取文件系统超级块,并且将其信息填充到内存中的超级块对象中 。
6. 超级对象中最重要的就是s_op,每一种文件系统都应该有自己的super_operations操作实例。它指向超级块的操作函数表, 它由struct super_operations结构体来表示。
现在来看一下它的定义:它的定义在 include/linux/fs.h头文件中可以看到
1560struct super_operations {
1561 struct inode *(*alloc_inode)(struct super_block *sb);
1562 void (*destroy_inode)(struct inode *);
1563
1564 void (*dirty_inode) (struct inode *);
1565 int (*write_inode) (struct inode *, struct writeback_control *wbc);
1566 int (*drop_inode) (struct inode *);
1567 void (*evict_inode) (struct inode *);
1568 void (*put_super) (struct super_block *);
1569 void (*write_super) (struct super_block *);
1570 int (*sync_fs)(struct super_block *sb, int wait);
1571 int (*freeze_fs) (struct super_block *);
1572 int (*unfreeze_fs) (struct super_block *);
1573 int (*statfs) (struct dentry *, struct kstatfs *);
1574 int (*remount_fs) (struct super_block *, int *, char *);
1575 void (*umount_begin) (struct super_block *);
1576
1577 int (*show_options)(struct seq_file *, struct vfsmount *);
1578 int (*show_stats)(struct seq_file *, struct vfsmount *);
1579#ifdef CONFIG_QUOTA
1580 ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t);
1581 ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t);
1582#endif
1583 int (*bdev_try_to_free_page)(struct super_block*, struct page*, gfp_t);
1584};
1>可以看到该结构体中的每一项都是一个指向超级块操作函数的指针,超级块操作函数执行文件系统和索引节点的低层操作。
2>当文件系统需要对超级块执行操作时,要在超级块对象中寻找需要的操作方法
例如:一个文件系统要写自己的超级块,需要调用:
sturct super_block * sb;
sb->s_op->write_super)(sb);
sb是指向文件系统超级块的指针,沿着该指针进入超级块操作函数表,并从表中取得writ_super()函数,该函数执行写入超级块的实际操作。
Tiger-John说明:
尽管writ_super()方法来自超级块,但是在调用时,还是要把超级块作为参数传递给它。
3>.分析其中比较重要的一些数据结构。
a.struct inode * alloc_inode(struct super_block * sb) :创建和初始化一个新的索引结点。
b.void destroy_inode(struct super_block *sb) :释放指定的索引结点 。
c.void dirty_inode(struct inode *inode) :VFS在索引节点被修改时会调用此函数。
d.void write_inode(struct inode *inode, struct writeback_control *wbc) 将指定的inode写回磁盘。
e.void drop_inode( struct inode * inode):删除索引节点。
f.void put_super(struct super_block *sb) :用来释放超级块。
g.void write_super(struct super_block *sb):更新磁盘上的超级块。
h.void sync_fs(struct super_block *sb,in wait):使文件系统的数据元素与磁盘上的文件系统同步,wait参数指定操作是否同步。
i.int statfs(struct super_block *sb,struct statfs *statfs):获取文件系统状态。把文件系统相关的统计信息放在statfs中。
2.inode
1).inode简介
inode 是 UNIX/Linux 操作系统中的一种数据结构,其本质是结构体,它包含了与文件系统中各个文件相关的一些重要信息,例如文件及目录的基本信息,包含时间、档名、使用者及群组等。在 UNIX/Linux中创建文件系统时,同时将会创建大量的 inode 。通常,文件系统磁盘空间中大约百分之一空间分配给了 inode 表。在Linux系统中,内核为每一个新创建的文件分配一个Inode(索引结点),每个文件都有一个惟一的inode号,我们可以将inode简单理解成一个指针,它永远指向本文件的具体存储位置。文件属性保存在索引结点里,在访问文件时,索引结点被复制到内存在,从而实现文件的快速访问。系统是通过索引节点(而不是文件名)来定位每一个文件。
2).inode内容
Block 是记录文件内容数据的区域,至于 inode 则是记录"该文件的相关属性,以及文件内容放置在哪一个 Block 之内"的信息,换句说, inode 除了记录文件的属性外,同时还必须要具有指向( pointer )的功能,亦即指向文件内容放置的区块之中,好让操作系统可以正确的去取得文件的内容,底下几个是 inode 记录的信息(当然不止这些):
3)inode结构体
inode结构体很大这里仅给出几个重要成员

struct inode{ //........ unsigned long i_ino; //节点号 atomic_t i_count; //引用计数 //........ uid_t i_uid; //使用者id gid_t i_gid; //使用者id组 //........ struct timespec i_atime; //最后访问时间 struct timespec i_mtime; //最后修改(modify)时间 struct timespec i_ctime; //最后改变(change)时间 unsigned long i_blocks; //文件的块数 unsigned short i_bytes; //使用的字节数 unsigned long i_state; //状态标志 struct list_head i_devices; //块设备链表 unsigned char i_sock; //是否套接字 atomic_t i_writecount; //写者计数 //........ }
4).关于inode与dataarea
inode table是data area的索引表,data Area中存放真正的数据。

a. linux FS 可以简单分成 superblock inode table与data area两部份。inode table上有许多的inode, 每个inode分别记录一个档案的属性与这个档案分布在哪些datablock上
b. inode table中红色区域即inode size,是128Byte,在liunx系统上通过命令我们可以看到,系统就是这么定义的,Inode size是指分配给一个inode来记录文档属性的磁盘块的大小。
c. data ares中紫色的区域block size,就是我们一般概念上的磁盘块。这块区域是我们用来存放数据的地方。
d. 还有一个逻辑上的概念:FS中每分配2048 byte给data area, 就分配一个inode。但一个inode就并不一定就用掉2048 byte, 也不是说files allocation的最小单位是2048 byte, 它仅仅是代表filesystem中inode table/data area分配空间的比例是128/2048,也就是1/16。
注意:
i-node 是标记文件中数据快存储位置的指针,一个I-NODE中能标记的数据快的个数是固定的,当文件很小时,一个文件对应一个I-node ,当文件比较大时一个文件对应多个I-NODE,一个inode对应一个文件,但文件可以有多个inode。是1:n的关系。
3.dentry
1)dentry简介
dentry是Linux文件系统中某个索引节点(inode)的链接,每个dentry代表路径中的一个特定部分。这个索引节点可以是文件,也可以是目录。inode(可理解为ext2 inode)对应于物理磁盘上的具体对象,dentry是一个内存实体,没有对应的磁盘数据结构,VFS根据字符串形式的路径名现场创建他,在dentry中,d_inode成员指向对应的inode。也就是说,一个inode可以在运行的时候链接多个dentry,而d_count记录了这个链接的数量。另外dentry对象有三种状态:被使用,未被使用和负状态。
2).dentry的结构体
struct dentry { atomic_t d_count; //目录项对象使用计数器,可以有未使用态,使用态和负状态 unsigned int d_flags; //目录项标志 struct inode *d_inode; //与文件名关联的索引节点 struct dentry *d_parent; //父目录的目录项对象 struct list_head d_hash; //散列表表项的指针 struct list_head d_lru; //未使用链表的指针 struct list_head d_child; //父目录中目录项对象的链表的指针 struct list_head d_subdirs; //对目录而言,表示子目录目录项对象的链表 struct list_head d_alias; //相关索引节点(别名)的链表 int d_mounted; //对于安装点而言,表示被安装文件系统根项 struct qstr d_name; //文件名 unsigned long d_time; /* used by d_revalidate */ struct dentry_operations *d_op; //目录项方法 struct super_block *d_sb; //文件的超级块对象 vunsigned long d_vfs_flags; void *d_fsdata; //与文件系统相关的数据 unsigned char d_iname [DNAME_INLINE_LEN]; //存放短文件名};
下面给出进一步的解释
一个有效的dentry结构必定有一个inode结构,这是因为一个目录项要么代表着一个文件,要么代表着一个目录,而目录实际上也是文件。所以,只要dentry结构是有效的,则其指针d_inode必定指向一个inode结构。可是,反过来则不然,一个inode却可能对应着不止一个dentry结构;也就是说,一个文件可以有不止一个文件名或路径名。这是因为一个已经建立的文件可以被连接(link)到其他文件名。所以在inode结构中有一个队列i_dentry,凡是代表着同一个文件的所有目录项都通过其dentry结构中的d_alias域挂入相应inode结构中的i_dentry队列。
在内核中有一个哈希表dentry_hashtable ,是一个list_head的指针数组。一旦在内存中建立起一个目录节点的dentry 结构,该dentry结构就通过其d_hash域链入哈希表中的某个队列中。
内核中还有一个队列dentry_unused,凡是已经没有用户(count域为0)使用的dentry结构就通过其d_lru域挂入这个队列。
Dentry结构中除了d_alias 、d_hash、d_lru三个队列外,还有d_vfsmnt、d_child及d_subdir三个队列。其中d_vfsmnt仅在该dentry为一个安装点时才使用。另外,当该目录节点有父目录时,则其dentry结构就通过d_child挂入其父节点的d_subdirs队列中,同时又通过指针d_parent指向其父目录的dentry结构,而它自己各个子目录的dentry结构则挂在其d_subdirs域指向的队列中。
从上面的叙述可以看出,一个文件系统中所有目录项结构或组织为一个哈希表,或组织为一颗树,或按照某种需要组织为一个链表,这将为文件访问和文件路径搜索奠定下良好的基础。
4.file
1)文件对象和file简介
文件对象表示进程已打开的文件,该对象file(不是物理文件)由相应的open()系统调用创建,有close()系统调用销毁,因为多个进程可以同时打开和操作一个文件,所以同一个文件也可能存在多个对应的文件对象。文件对象仅仅在进程观点上代表已打开文件,它反过来指向目录项对象(反过来指向索引节点),其实只有目录项对象才表示已打开的实际文件,虽然一个文件对应的文件对象不是是唯一的,但对应的索引节点和目录项对象无疑是唯一的,另外类似于目录项对象,文件对象实际上没有对应的磁盘数据。
一个文件对象是由一个文件结构体表示的,文件结构体代表一个打开的文件,系统中的每个打开的文件在内核空间都有一个关联的 struct file。它由内核在打开文件时创建,并传递给在文件上进行操作的任何函数。在文件的所有实例都关闭后,内核释放这个数据结构。
2)file的结构体
struct file { union { struct list_head fu_list; //文件对象链表指针linux/include/linux/list.h struct rcu_head fu_rcuhead; //RCU(Read-Copy Update)是Linux 2.6内核中新的锁机制 } f_u; struct path f_path; //包含dentry和mnt两个成员,用于确定文件路径 #define f_dentry f_path.dentry //f_path的成员之一,当前文件的dentry结构 #define f_vfsmnt f_path.mnt //表示当前文件所在文件系统的挂载根目录 const struct file_operations *f_op; //与该文件相关联的操作函数 atomic_t f_count; //文件的引用计数(有多少进程打开该文件) unsigned int f_flags; //对应于open时指定的flag mode_t f_mode; //读写模式:open的mod_t mode参数 off_t f_pos; //该文件在当前进程中的文件偏移量 struct fown_struct f_owner; //该结构的作用是通过信号进行I/O时间通知的数据。 unsigned int f_uid, f_gid; //文件所有者id,所有者组id struct file_ra_state f_ra; //在linux/include/linux/fs.h中定义,文件预读相关 unsigned long f_version; //记录文件的版本号,每次使用后都自动递增。 #ifdef CONFIG_SECURITY void *f_security; //用来描述安全措施或者是记录与安全有关的信息。 #endif /* needed for tty driver, and maybe others */ void *private_data; //可以用字段指向已分配的数据 #ifdef CONFIG_EPOLL /* Used by fs/eventpoll.c to link all the hooks to this file */ struct list_head f_ep_links; //文件的事件轮询等待者链表的头, spinlock_t f_ep_lock; f_ep_lock是保护f_ep_links链表的自旋锁。 #endif /* #ifdef CONFIG_EPOLL */ struct address_space *f_mapping; 文件地址空间的指针};
介绍完VFS的4大对象模型,对于file对象还有必要说明一下PCB(进程控制块)中的files_struct结构体
files_struct
1).用户打开文件表和files_struct简介
每个进程用一个files_struct结构来记录文件描述符的使用情况,这个files_struct结构称为用户打开文件表,它是进程的私有数据,
2)files_struct的结构体
struct files_struct { atomic_t count; /* 共享该表的进程数 */ rwlock_t file_lock; /* 保护该结构体的锁*/ int max_fds; /*当前文件对象的最大数*/ int max_fdset; /*当前文件描述符的最大数*/ int next_fd; /*已分配的文件描述符加1*/ struct file ** fd; /* 指向文件对象指针数组的指针 */ fd_set *close_on_exec; /*指向执行exec()时需要关闭的文件描述符*/ fd_set *open_fds; /*指向打开文件描述符的指针*/ fd_set close_on_exec_init; /* 执行exec()时关闭的初始文件*/ fd_set open_fds_init; /*文件描述符的初值集合*/ struct file * fd_array[32]; /* 文件对象指针的初始化数组*/};
下面给出一部分解释
fd域指向文件对象的指针数组。该数组的长度存放在max_fds域中。通常,fd域指向files_struct结构的fd_array域,该域包括32个文件对象指针。如果进程打开的文件数目多于32,内核就分配一个新的、更大的文件指针数组,并将其地址存放在fd域中;内核同时也更新max_fds域的值。
对于在fd数组中有入口地址的每个文件来说,数组的索引就是文件描述符(file descriptor)。通常,数组的第一个元素(索引为0)是进程的标准输入文件,数组的第二个元素(索引为1)是进程的标准输出文件,数组的第三个元素(索引为2)是进程的标准错误文件。请注意,借助于dup()、dup2()和 fcntl ) 系统调用,两个文件描述符就可以指向同一个打开的文件,也就是说,数组的两个元素可能指向同一个文件对象。当用户使用shell结构(如2>&1)将标准错误文件重定向到标准输出文件上时,用户总能看到这一点。
open_fds域包含open_fds_init域的地址,open_fds_init域表示当前已打开文件的文件描述符的位图。max_fdset域存放位图中的位数。由于数据结构fd_set有1024位,通常不需要扩大位图的大小。不过,如果确实必须的话,内核仍能动态增加位图的大小,这非常类似文件对象的数组的情形。
当开始使用一个文件对象时调用内核提供的fget()函数。这个函数接收文件描述符fd作为参数,返回在current->files->fd[fd]中的地址,即对应文件对象的地址,如果没有任何文件与fd对应,则返回NULL。在第一种情况下,fget()使文件对象引用计数器f_count的值增1。
-----------------------------
用户打开文件表files_structs是由进程描述符task_struct中的file域指向,所有与进程相关的信息如打开的文件及文件描述符都包含其中,又从前面可以看出,files_struct通过**file保持对文件对象file的访问,于此相似文件对象file的结构体内成员中包含目录项dentry,目录项dentry将文件名与inode相连,最终通过inode中的指针可以访问存储实际的数据的地方Data Area.
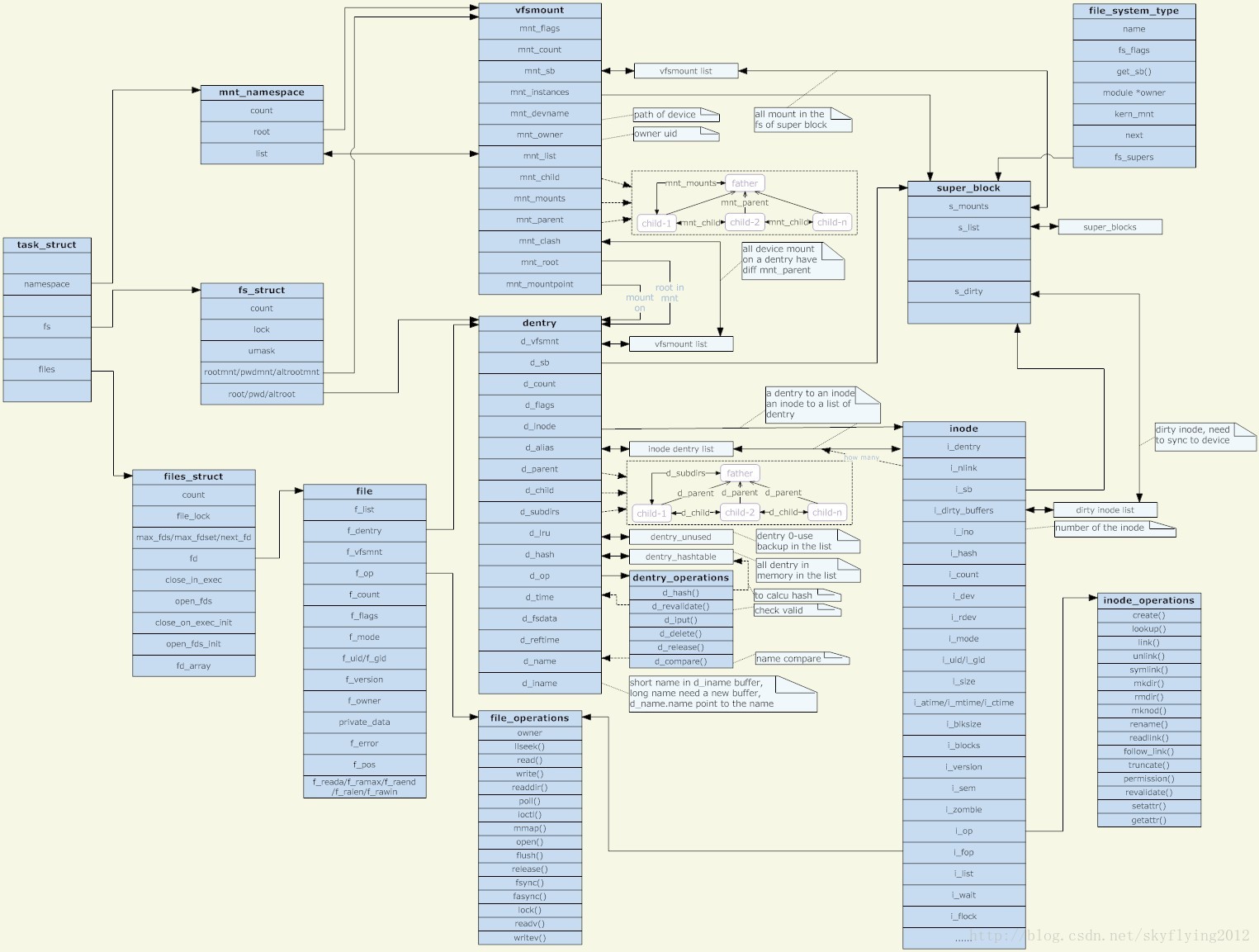
内核虚拟文件系统的整个结构关系图如下: