最近在回顾Disruptor的相关知识,觉得Disruptor在计算机底层的领域确实比一般人厉害不少,以前在写程序的时候,基本是从应用逻辑的角度考虑,觉得设计模式+少量算法+ 优美的代码=理想的结果,但看完Disruptor的设计后,觉得只考虑应用本身是有一定的局限性,还需要懂底层,硬件层面的东西,就像Disruptor一样,通过底层优化,让程序有质的飞跃。
下面就Disruptor提到的CPU缓存话题,做了一些尝试和研究,如Disruptor所说,CPU有缓存伪共享的问题,并且通过缓存行填充能完美的解决这个问题。
CPU缓存
CPU是机器的心脏,最终由它来执行所有运算和程序。主内存(RAM)是存放数据(包括代码行)的地方。CPU和主内存之间有好几层缓存,即使直接访问主内存也是非常慢的。如果你正在多次对一块数据做相同的运算,那么在执行运算的时候把它加载到离CPU很近的地方就有意义了(比如一个循环计数)。下面是CPU的缓存结构图:
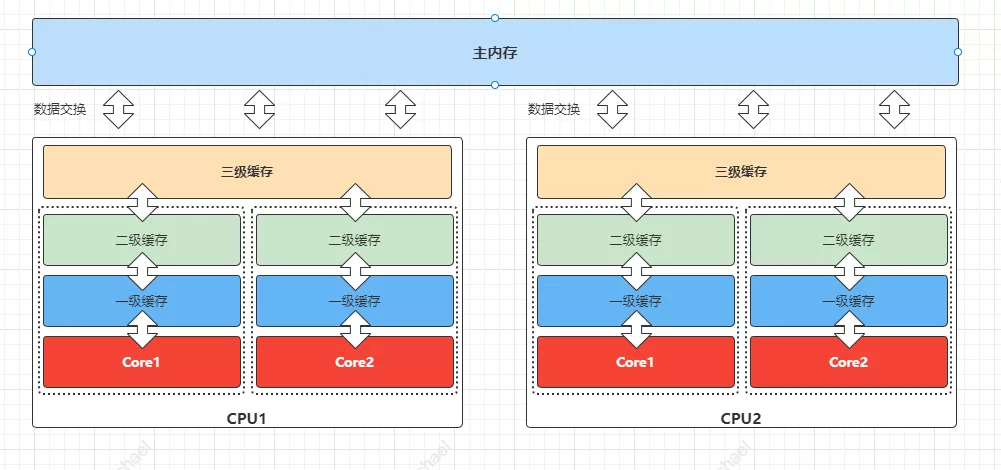
越靠近CPU的核缓存越快但是也越小,所以一级缓存很小但很快,并且紧靠着在使用它的CPU内核。二级缓存大一些,也慢一些,注意一级二级缓存只能被一个单独的CPU的单个核使用。三级缓存在现代多核机器中更普遍,仍然更大,更慢,但是被单个插槽上的所有CPU核共享。最后,你拥有一块主存,由全部插槽上的所有CPU核共享。当CPU执行运算的时候,它先去一级缓存查找所需的数据,再去二级缓存,然后是三级缓存,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在一级缓存中。
这是在网上找到的一份CPU缓存未命中时候的CPU时钟消耗一级大概的耗时:

CPU缓存行与伪共享
数据在缓存中不是以独立的项来存储,不是单独的变量,也不是单独的指针。缓存系统中是以缓存行(cache line)为单位存储,缓存行是2的整数幂个连续字节,一般为32-256个字节,最常见的缓存行大小是64个字节。下面是CPU缓存行的逻辑图:

CPU从主内存中加载数据的时候,不是只加载某一个变量的值,而是加载一个缓存行的值,例如一个Java的long类型是8字节,因此在一个缓存行中可以存8个long类型的变量。如果你访问一个long类型的数组,当数组中的一个值被加载到缓存中,它会额外加载另外7个。如果你数据结构中的项在内存中不是彼此相邻的,例如链表LinkedList结构,你将得不到缓存行加载所带来的优势,并且在这些数据结构中的每一个项都可能会出现缓存未命中,这是也是链表不适合遍历的原因之一。
但是,缓存行加载某一块内存数据,这个有好处也有坏处,缓存行不是单个数据,而是一组数据,如上图所示当2个线程同时运行在2个core上,同时加载了同一个缓存行,Core1修改X数据,Core2读Y数据,Core1修改后提交,Core2发现X数据有变化,缓存未命中,就会重新加载整个缓存行,但是Core2并不会用X数据,而是读Y数据,去重新加载整个缓存行的数据,无意中影响彼此的性能。如果两个独立的线程同时写两个不同的值会更糟,因为每次线程对缓存行进行写操作时,每个内核都要把另一个内核上的缓存块无效掉并重新读取里面的数据。你基本上是遇到两个线程之间的写冲突了,尽管它们写入的是不同的变量。每个线程都要去竞争缓存行的所有权来更新变量。如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。当核心2获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。这会来来回回的经过CPU三级缓存,大大影响了性能。如果互相竞争的核心位于不同的插槽,就要额外横跨插槽连接,问题可能更加严重,这就是CPU缓存伪共享。
Java处理缓存伪共享-缓存行填充
因为是硬件底层的逻辑,几乎所有程序在跑的时候都会遇到这个问题,那么java是如何处理这个问题呢?答案就是缓存行填充。
对于HotSpot JVM,所有对象都有两个字长的对象头。第一个字是由24位哈希码和8位标志位(如锁的状态或作为锁对象)组成的Mark Word。第二个字是对象所属类的引用。如果是数组对象还需要一个额外的字来存储数组的长度。每个对象的起始地址都对齐于8字节以提高性能。因此当封装对象的时候为了高效率,对象字段声明的顺序会被重排序成下列基于字节大小的顺序:
doubles (8) 和 longs (8)
ints (4) 和 floats (4)
shorts (2) 和 chars (2)
booleans (1) 和 bytes (1)
references (4/8)
<子类字段重复上述顺序>
通过对热点变量周围进行缓存行填充,来规避缓存伪共享带来的问题,对于缓存行大小是64字节或更少的处理器架构来说是这样的,有可能处理器的缓存行是128字节,那么使用64字节填充还是会存在伪共享问题,通过增加补全变量的个数来确保热点变量不会和其他东西同时存在于一个缓存行中。下面是Disruptor对ring buffer的序列号做的补全代码:
public long p1, p2, p3, p4, p5, p6, p7; // cache line padding
private volatile long cursor = INITIAL_CURSOR_VALUE;
public long p8, p9, p10, p11, p12, p13, p14; // cache line padding
当CPU缓存加载cursor变量的时候,会连带加载周边的7个long类型变量,但是这几个long类型变量不会有任何线程去修改它,因此不会出现缓存未命中问题,完美规避了缓存伪共享的问题。java培训
Java程序代码验证
官方也给了一个java的测试demo,那么下面针对各种不同的情景,做一下实验看看,是不是有缓存伪共享这个问题,测试代码如下:

下面针对各个测试场景,做一下简单的描述:
场景一:对Long变量进行写入,没有缓存行填充,没有volatile关键字。
场景二:对Long变量进行写入,有缓存行填充,没有volatile关键字。
场景三:对Long变量进行写入,没有缓存行填充,有volatile关键字。
场景四:对Long变量进行写入,有缓存行填充,有volatile关键字。
下面是针对各个场景的测试结果(每个场景测试3次,取平均值):
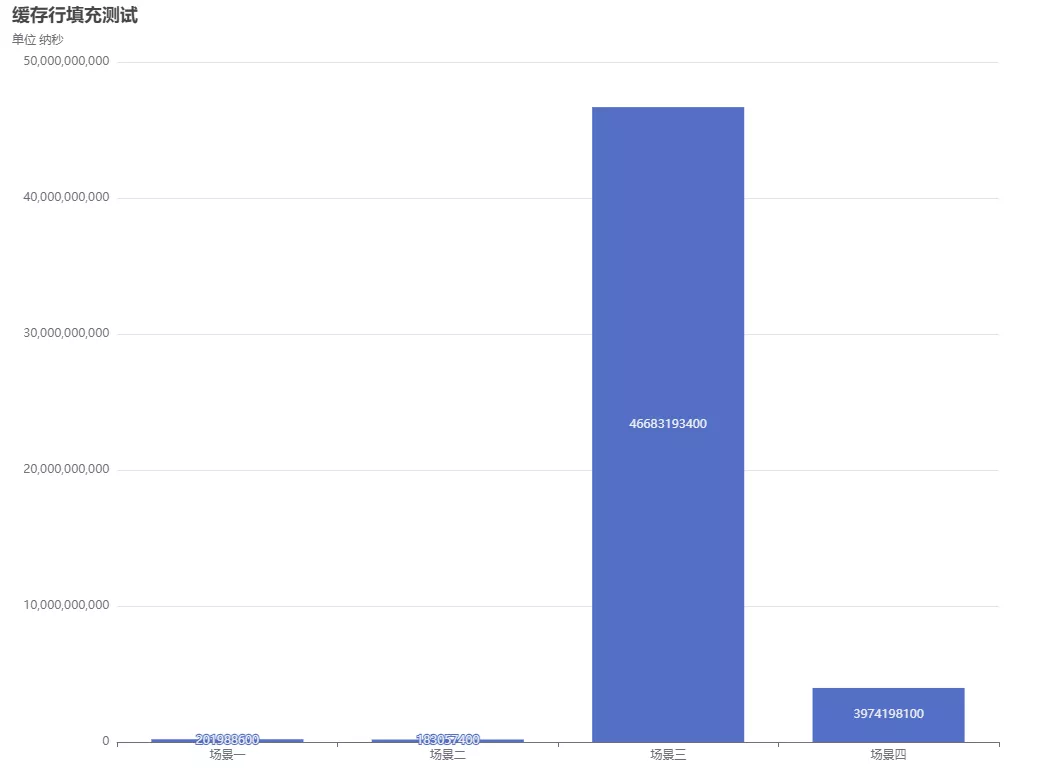
从测试结果来看,场景一和场景二差不多,有缓存行填充的稍微快那么一点点,区别不大,都是192276000纳秒左右。场景三和场景四有volatile关键字的就不一样了,这里可以看出volatile关键字对一个变量的读取和写入性能影响还是比较大,写入耗时是直接写入的200多倍,因此volatile关键字怎么用很关键,用到哪些地方也很关键,不要在代码里面随便加,不会用反而会影响程序运行效率。场景三有volatile关键字,但是没有进行缓存行填充,耗时是有缓存行填充的10几倍,这里就能看出缓存行填充的效果在用到了内存屏障的时候还是很明显。
CPU缓存伪共享的问题,确实打破了很多人对常规程序执行的理解,如何才能应用到工作中呢?有以下几点需要注意:
-
对volatile很熟悉,并且代码里面使用到了缓存屏障,需要看看能否用到这个缓存填充行。
-
清楚程序在某个时刻会有缓存伪共享问题,例如某几个代码在一起的变量会被多个线程同时使用并且有写入操作,需要用缓存填充行把这几个变量隔开。
-
能使用工具分析自己写的程序,看看有缓存填充行过后,是否真的能提升效率,例如JProfiler分析工具。
版权声明:本文为原创文章,转载请附上原文出处链接及本声明。下载相关视频学习资料到尚硅谷官方网站。
阅读(661) | 评论(0) | 转发(0) |
