Spark streaming 程序需要不断接收新数据,然后进行业务逻辑处理,而用于接受数据的就是Recever。显然Receiver的正常运行对应整个Spark Streaming应用程序至关重要,如果Receiver出现异常,后面的业务逻辑就无从谈起。Spark Streaming 是如何实现Receiver以保证其可靠性的,本文将结合Spark Streaming的Receiver源码实现详细解析Receiver的实现原理。
一、Receiver 实现策略思考
1、启动Receiver的时候,启动一个Job,这个Job里面有RDD的transformations操作和action的操作,这个Job只有一个partition.这个partition的特殊是里面只有一个成员,这个成员就是启动的Receiver。这样做的问题:
a) 如果有多个InputDStream,那就要启动多个Receiver,每个Receiver也就相当于分片partition,那我们启动Receiver的时候理想的情况下是在不同的机器上启动Receiver,但是Spark Core的角度来看就是应用程序,感觉不到Receiver的特殊性,所以就会按照正常的Job启动的方式来处理,极有可能在一个Executor上启动多个Receiver.这样的话就可能导致负载不均衡。 b) 有可能启动Receiver失败,只要集群存在Receiver就不应该失败。
c) 运行过程中,就默认的而言如果是一个partition的话,那启动的时候就是一个Task,但是此Task也很可能失败,因此以Task启动的Receiver也会挂掉。
2、由Spark Streaming 自己管理Receiver,负责Receiver的调度和容错和启动。这样做的好处:
a)由Spark Streaming 调度Receiver 可以充分考虑负责均衡,避免将多个Receiver调度到同一台机器上
b)Receiver 失败后可以自动重新启动,继续接受数据,从而使程序持续不断继续工作下去。
c)Receiver 重启不收Task重启次数的限制。
二、Spark Streaming的Receiver实现原理
2.1、和Receiver实现相关核心成员
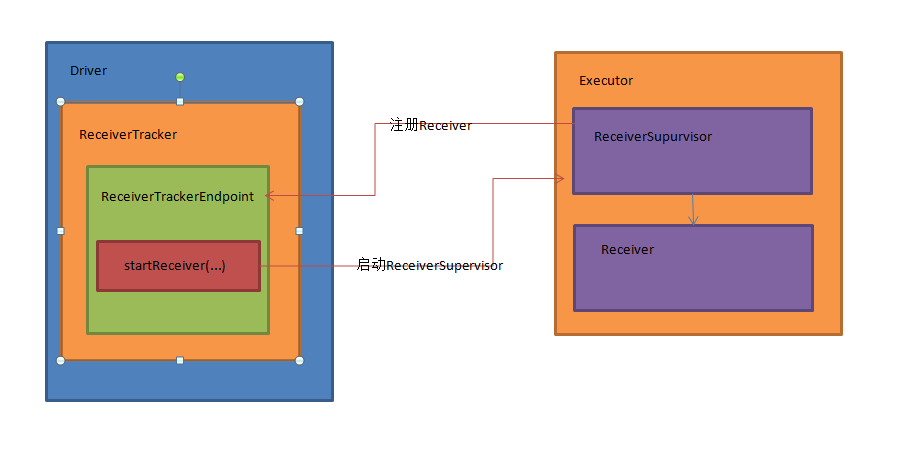
(1)ReceiverTracker
(2)ReceiverTrackerEndpoint
(3)ReceiverSuperVisor
(4)Receiver
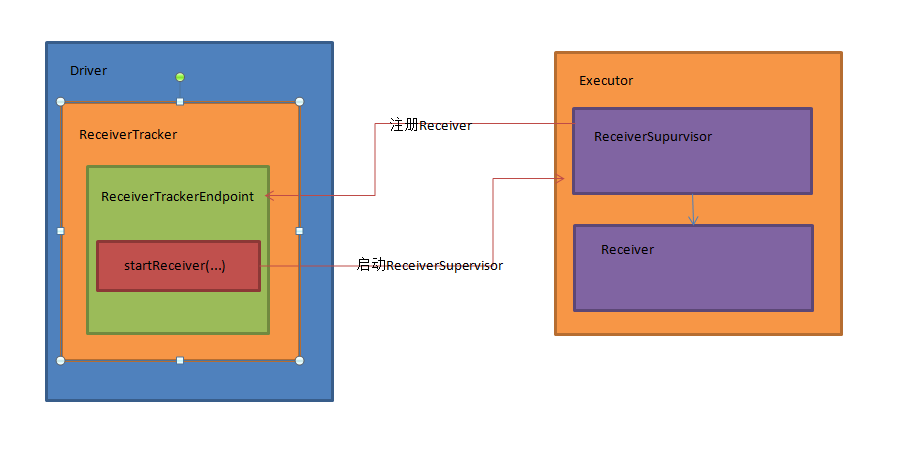
ReceiverTracker在Driver端,ReceiverSuperVisor和Receiver在Executor端,架构图如下:
2.2 Spark Streaming的Receiver实现源码解析
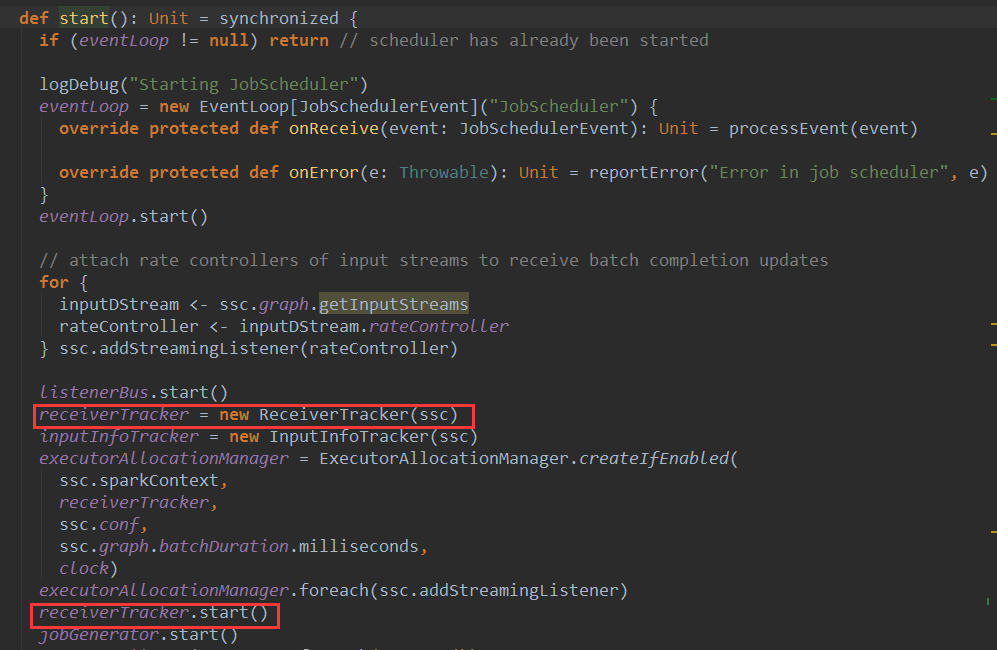
首先SparkStream启动时候会启动JobScheduler,在JobSceduler的start方法中,会实例化ReceiverTracker,并调用ReceiverTracker的start方法启动ReceiverTracker。
ReceiverTracker的start方法首先检查输入流是否为空,如果不为空会创建ReceiverTrackerEndpoint并注册给rpcEnv。然后调用launchReceivers方法启动Receiver。其中receiverInputStreams是注册到DStreamGraph中的ReceiverInputDStream。
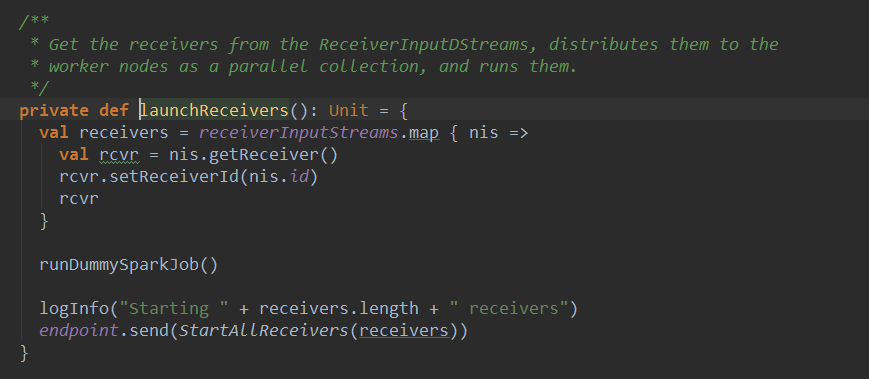
下面看一下launchReceiver方法:基于ReceiverInputDStream(是在Driver端)来获得具体的Receivers实例,然后再把他们分不到Worker节点上。一个ReceiverInputDStream只产生一个Receiver
首先从ReceiverInputDStream中获取Receiver,然后调用runDummySparkJob启动一个虚拟任务,我们在后面再分析这个虚拟任务,先看一下后面的核心代码:
endpoint.send(StartAllReceivers(receivers))
此处的endpoint就是刚才实例化的ReceiverTrackerEndpoint对象的引用,可以看到此处给endpoint发送了StartAllReceivers消息。
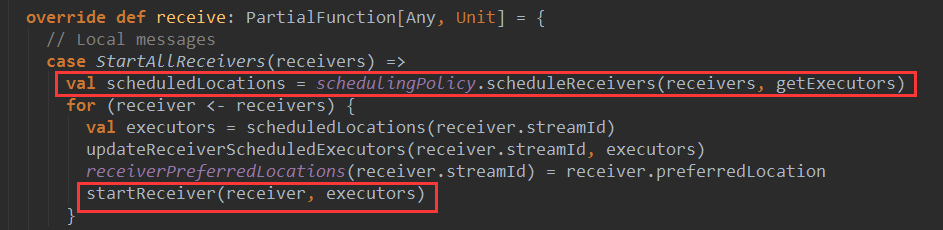
下面看下一ReceiverTrackerEndpoint收到StartAllReceivers消息后的处理逻辑:
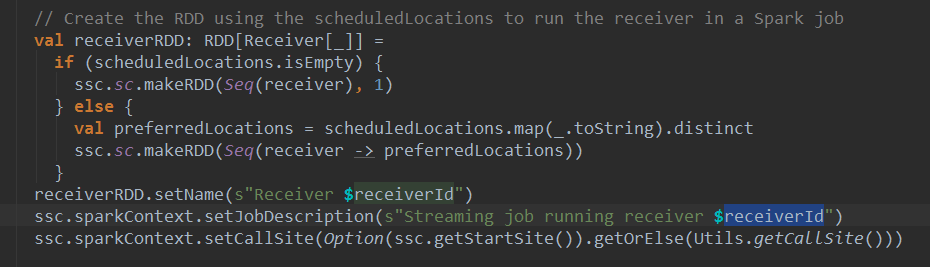
首先,根据一定的调度策略给传入receivers分配相应的executors,从这里可以看出,Receiver的调度并不是交给spark内核完成的,而是由Spark Streaming框架完成调度过程。这样做的目的就是为了避免Spark内核将Receiver当做普通的job而将多个Receiver调度到同一个节点上。
Spark Streaming的调度策略这里不做分析,接着看下面的代码,迭代所以的receiver ,对每个receiver调用 startReceiver方法在具体Executor上启动Receiver。
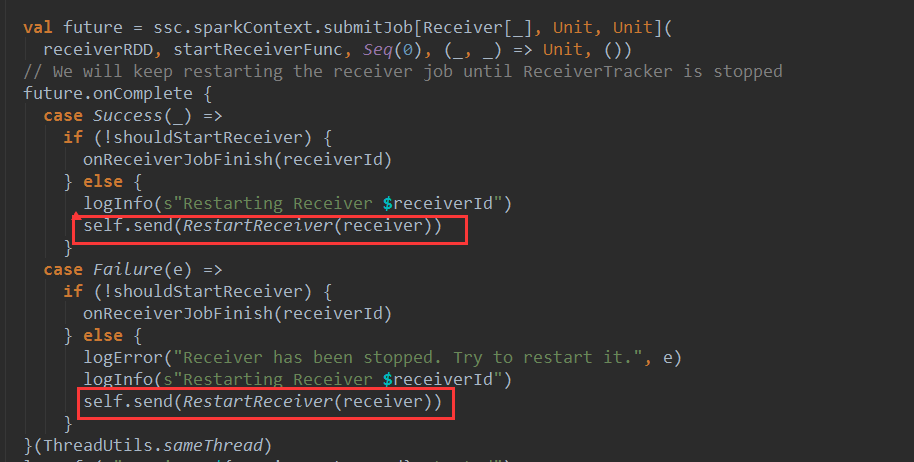
这个startReceiver比较复杂,我们一步步分析,先看最核心的一行代码:
可看到,Spark Streaming 为每个Receiver 启动了一个job,而不是由Action操作出发Job执行。
这里job的提交主要关注两个参数receiverRDD和startReceiverFunc。
receiverRDD的源码:
可以看到调用了SparkContext的makeRDD方法创建了RDD,该RDD只有一条数据,就是receiver对象
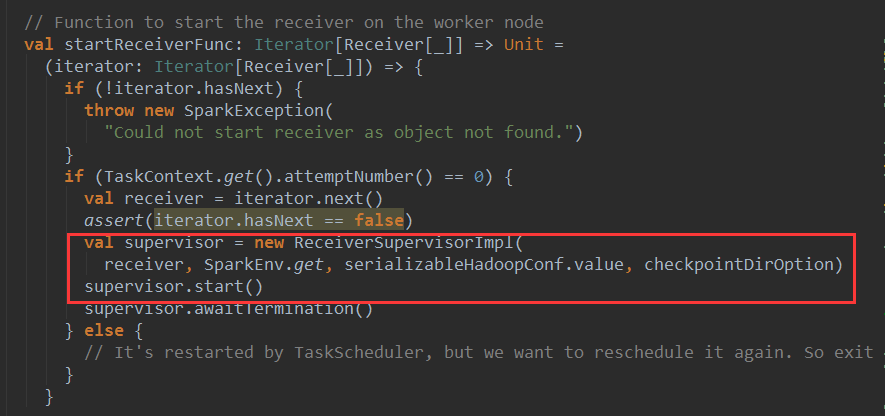
下面看一看startReceiverFunc的源码
startReceiverFunc 在worker节点上启动receiver,首先创建了一个ReceiverSupervisiorImpl 对象 supervisor,然后调用supervisor的start方法在该节点上启动supervisor:
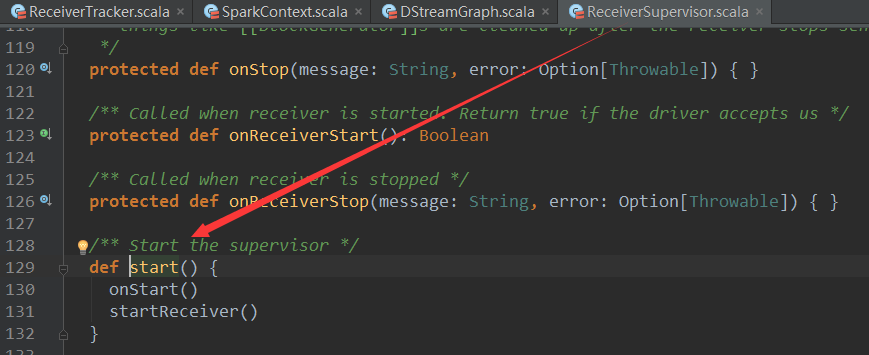
ReceiverSupervisiorImpl 是继承自ReceiverSupervisor,ReceiverSupervisor中调用了startReceiver方法:
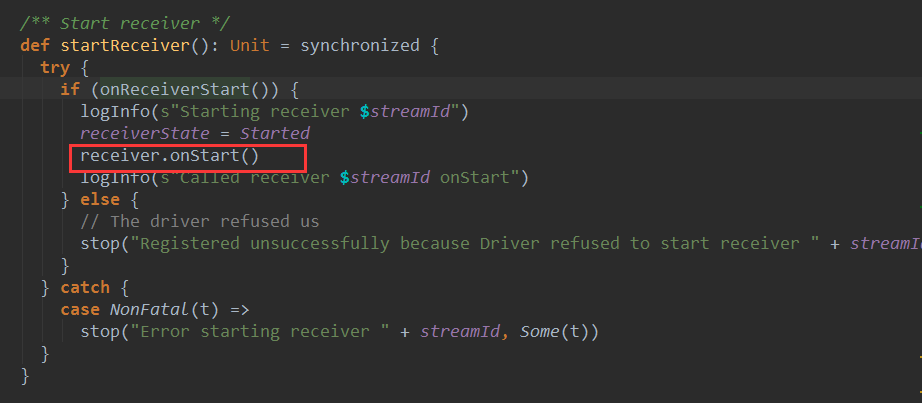
首先调用onReceiverStart方法,将Receiver注册给receiverTracker:
如果注册成功,调用了Receiver的onStart方法在Executor启动Receiver不断接受数据,并将接收的数据交给BlockManager管理,至此Receiver启动完成。
回到ReceiverTracker的startReceiver方法,如果Receiver对应的job完成,无论返回成功或失败,只要ReceiverTracker还没有停止就会发送RestartReceiver消息给ReceiverTrakerEndpoint,重启Receiver。从这里可以看出Receiver不会像普通的spark core 程序一样受到重试次数的限制而导致作业失败
最后,在看一下runDummyJob方法:
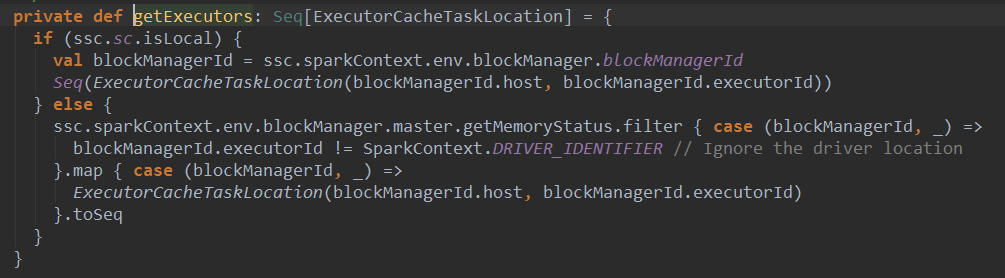
该方法运行了一个简单的wordcount程序,运行该程序的目的是确保所有slaves节点都被注册了,让receiver尽量分配到不同的work上运行,看一下getExecutors的源码 :
总结:Driver端的ReceiverTracker管理所有Executor上的Receiver任务,他有一个ReceiverTrakerEndpoint 消息通讯体,这个消息通讯体在startReceiver方法中提交Receiver的job在具体Executor上运行,并接受Executor端发送过来的消息(比如注册Receiver),在Executor端有一个ReceiverSupervisor专门管理Receiver,负责Receiver的注册启动与ReceiverTracker的信息交互。