君子务本,本立则道生。
分类: LINUX
2014-01-09 15:18:11
原文地址:Linux 系统调用 作者:ztguang
使用 Linux 系统调用的内核命令
作者:M. Tim Jones 转贴自:本站原创
Linux® 系统调用 —— 我们每天都在使用它们。不过您清楚系统调用是如何在用户空间和内核之间执行的吗?本文将探究 Linux 系统调用接口(SCI),学习如何添加新的系统调用(以及实现这种功能的其他方法),并介绍与 SCI 有关的一些工具。
系统调用就是用户空间应用程序和内核提供的服务之间的一个接口。由于服务是在内核中提供的,因此无法执行直接调用;相反,您必须使用一个进程来跨越用户空间与内核之间的界限。在特定架构中实现此功能的方法会有所不同。因此,本文将着眼于最通用的架构 —— i386。
在本文中,我将探究 Linux SCI,演示如何向 2.6.20 内核添加一个系统调用,然后从用户空间来使用这个函数。我们还将研究在进行系统调用开发时非常有用的一些函数,以及系统调用的其他选择。最后,我们将介绍 与系统调用有关的一些辅助机制,比如在某个进程中跟踪系统调用的使用情况。
SCI
Linux 中系统调用的实现会根据不同的架构而有所变化,而且即使在某种给定的体架构上也会不同。例如,早期的 x86 处理器使用了中断机制从用户空间迁移到内核空间中,不过新的 IA-32 处理器则提供了一些指令对这种转换进行优化(使用 sysenter 和 sy***it 指令)。由于存在大量的方法,最终结果也非常复杂,因此本文将着重于接口细节的表层讨论上。更详尽的内容请参看本文最后的 参考资料。
要对 Linux 的 SCI 进行改进,您不需要完全理解 SCI 的内部原理,因此我将使用一个简单的系统调用进程(请参看图 1)。每个系统调用都是通过一个单一的入口点多路传入内核。eax 寄存器用来标识应当调用的某个系统调用,这在 C 库中做了指定(来自用户空间应用程序的每个调用)。当加载了系统的 C 库调用索引和参数时,就会调用一个软件中断(0x80 中断),它将执行 system_call 函数(通过中断处理程序),这个函数会按照 eax 内容中的标识处理所有的系统调用。在经过几个简单测试之后,使用 system_call_table 和 eax 中包含的索引来执行真正的系统调用了。从系统调用中返回后,最终执行 syscall_exit,并调用 resume_userspace 返回用户空间。然后继续在 C 库中执行,它将返回到用户应用程序中。
SCI 的核心是系统调用多路分解表。这个表如图 2 所示,使用 eax 中提供的索引来确定要调用该表中的哪个系统调用(sys_call_table)。图中还给出了表内容的一些样例,以及这些内容的位置。(有关多路分解的更多内容,请参看侧栏 “系统调用多路分解”)
图 2. 系统调用表和各种链接
添加一个 Linux 系统调用
|
添加一个新系统调用主要是一些程序性的操作,但应该注意几件事情。本节将介绍几个系统调用的构造,从而展示它们的实现和用户空间应用程序对它们的使用。
向内核中添加新系统调用,需要执行 3 个基本步骤:
注意: 这个过程忽略了用户空间的需求,我将稍后介绍。
最常见的情况是,您会为自己的函数创建一个新文件。不过,为了简单起见,我将自己的新函数添加到现有的源文件中。清单 1 所示的前两个函数,是系统调用的简单示例。清单 2 提供了一个使用指针参数的稍微复杂的函数。
清单 1. 系统调用示例的简单内核函数
|
|
在清单 1 中,我们为进行 jiffies 监视提供了两个函数。(有关 jiffies 的更多信息,请参看侧栏 “Kernel jiffies”)。第一个函数会返回当前 jiffy,而第二个函数则返回当前值与所传递进来的值之间的差值。注意 asmlinkage 修饰符的使用。这个宏(在 linux/include/asm-i386/linkage.h 中定义)告诉编译器将传递栈中的所有函数参数。
清单 2. 系统调用示例的最后内核函数
|
|
|
清单 2 给出了第三个函数。这个函数使用了两个参数:一个 long 类型,以及一个指向被定义为 __user 的 long 的指针。__user 宏简单告诉编译器(通过 noderef)不应该解除这个指针的引用(因为在当前地址空间中它是没有意义的)。这个函数会计算这两个 jiffies 值之间的差值,然后通过一个用户空间指针将结果提供给用户。put_user 函数将结果值放入 presult 所指定的用户空间位置。如果在这个操作过程中出现错误,将立即返回,您也可以通知用户空间调用者。
对于步骤 2 来说,我对头文件进行了更新:在系统调用表中为这几个新函数安排空间。对于本例来说,我使用新系统调用号更新了 linux/include/asm/unistd.h 头文件。更新如清单 3 中的黑体所示。
清单 3. 更新 unistd.h 文件为新系统调用安排空间
|
|
#define __NR_getcpu 318
#define __NR_epoll_pwait 319
#define __NR_getjiffies 320
#define __NR_diffjiffies 321
#define __NR_pdiffjiffies 322
#define NR_syscalls 323
现在已经有了自己的内核系统调用,以及表示这些系统调用的编号。接下来需要做的是要在这些编号(表索引)和函数本身之间建立一种对等关系。这就是第 3 个步骤,更新系统调用表。如清单 4 所示,我将为这个新函数更新 linux/arch/i386/kernel/syscall_table.S 文件,它会填充清单 3 显示的特定索引。
清单 4. 使用新函数更新系统调用表
|
|
注意: 这个表的大小是由符号常量 NR_syscalls 定义的。
现在,我们已经完成了对内核的更新。接下来必须对内核重新进行编译,并在测试用户空间应用程序之前使引导使用的新映像变为可用。
对用户内存进行读写
Linux 内核提供了几个函数,可以用来将系统调用参数移动到用户空间中,或从中移出。方法包括一些基本类型的简单函数(例如 get_user 或 put_user)。要移动一块儿数据(如结构或数组),您可以使用另外一组函数: copy_from_user 和 copy_to_user。可以使用专门的调用移动以 null 结尾的字符串: strncpy_from_user 和 strlen_from_user。您也可以通过调用 access_ok 来测试用户空间指针是否有效。这些函数都是在 linux/include/asm/uaccess.h 中定义的。
您可以使用 access_ok 宏来验证给定操作的用户空间指针。这个函数有 3 个参数,分别是访问类型(VERIFY_READ 或 VERIFY_WRITE),指向用户空间内存块的指针,以及块的大小(单位为字节)。如果成功,这个函数就返回 0:
| int access_ok( type, address, size ); |
要在内核和用户空间移动一些简单类型(例如 int 或 long 类型),可以使用 get_user 和 put_user 轻松地实现。这两个宏都包含一个值以及一个指向变量的指针。get_user 函数将用户空间地址(ptr)指定的值移动到所指定的内核变量(var)中。 put_user 函数则将内核变量(var)指定的值移动到用户空间地址(ptr)。 如果成功,这两个函数都返回 0:
int get_user( var, ptr );
int put_user( var, ptr );
要移动更大的对象,例如结构或数组,您可以使用 copy_from_user 和 copy_to_user 函数。这些函数将在用户空间和内核之间移动完整的数据块。 copy_from_user 函数会将一块数据从用户空间移动到内核空间,copy_to_user 则会将一块数据从内核空间移动到用户空间:
unsigned long copy_from_user( void *to, const void __user *from, unsigned long n );
unsigned long copy_to_user( void *to, const void __user *from, unsigned long n );
最后,您可以使用 strncpy_from_user 函数将一个以 NULL 结尾的字符串从用户空间移动到内核空间中。在调用这个函数之前,您可以通过调用 strlen_user 宏来获得用户空间字符串的大小:
long strncpy_from_user( char *dst, const char __user *src, long count );
strlen_user( str );
这些函数为内核和用户空间之间的内存移动提供了基本功能。实际上还可以使用另外一些函数(例如减少执行检查数量的函数)。您可以在 uaccess.h 中找到这些函数。
使用系统调用
现在内核已经使用新系统调用完成更新了,接下来看一下从用户空间应用程序中使用这些系统调用需要执行的操作。使用新的内核系统调用有两种方法。第一种方法非常方便(但是在产品代码中您可能并不希望使用),第二种方法是传统方法,需要多做一些工作。
使用第一种方法,您可以通过 syscall 函数调用由其索引所标识的新函数。使用 syscall 函数,您可以通过指定它的调用索引和一组参数来调用系统调用。例如,清单 5 显示的简单应用程序就使用其索引调用了 sys_getjiffies。
清单 5. 使用 syscall 调用系统调用
#include
#include
#define __NR_getjiffies 320
int main()
{
long jiffies;
jiffies = syscall( __NR_getjiffies );
printf( "Current jiffies is %lx\n", jiffies );
return 0;
}
正如您所见,syscall 函数使用了系统调用表中使用的索引作为第一个参数。如果还有其他参数需要传递,可以加在调用索引之后。大部分系统调用都包括了一个 SYS_ 符号常量来指定自己到 __NR_ 索引的映射。例如,使用 syscall 调用 __NR_getpid 索引:
| syscall( SYS_getpid ) |
syscall 函数特定于架构,使用一种机制将控制权交给内核。其参数是基于 __NR 索引与 /usr/include/bits/syscall.h 提供的 SYS_ 符号之间的映射(在编译 libc 时定义)。永远都不要直接引用这个文件;而是要使用 /usr/include/sys/syscall.h 文件。
传统的方法要求我们创建函数调用,这些函数调用必须匹配内核中的系统调用索引(这样就可以调用正确的内核服务),而且参数也必须匹配。Linux 提供了一组宏来提供这种功能。_syscallN 宏是在 /usr/include/linux/unistd.h 中定义的,格式如下:
_syscall0( ret-type, func-name )
_syscall1( ret-type, func-name, arg1-type, arg1-name )
_syscall2( ret-type, func-name, arg1-type, arg1-name, arg2-type, arg2-name )
|
_syscall 宏最多可定义 6 个参数(不过此处只显示了 3 个)。
现在,让我们来看一下如何使用 _syscall 宏来使新系统调用对于用户空间可见。清单 6 显示的应用程序使用了 _syscall 宏定义的所有系统调用。
清单 6. 将 _syscall 宏 用于用户空间应用程序开发
#include
#include
#include
#define __NR_getjiffies 320
#define __NR_diffjiffies 321
#define __NR_pdiffjiffies 322
_syscall0( long, getjiffies );
_syscall1( long, diffjiffies, long, ujiffies );
_syscall2( long, pdiffjiffies, long, ujiffies, long*, presult );
int main()
{
long jifs, result;
int err;
jifs = getjiffies();
printf( "difference is %lx\n", diffjiffies(jifs) );
err = pdiffjiffies( jifs, &result );
if (!err) {
printf( "difference is %lx\n", result );
} else {
printf( "error\n" );
}
return 0;
}
注意 __NR 索引在这个应用程序中是必需的,因为 _syscall 宏使用了 func-name 来构造 __NR 索引(getjiffies -> __NR_getjiffies)。其结果是您可以使用它们的名字来调用内核函数,就像其他任何系统调用一样。
用户/内核交互的其他选择
系统调用是请求内核中服务的一种有效方法。使用这种方法的最大问题就是它是一个标准接口,很难将新的系统调用增加到内核中,因此可以通过其他方法来 实现类似服务。如果您无意将自己的系统调用加入公共的 Linux 内核中,那么系统调用就是将内核服务提供给用户空间的一种方便而且有效的方法。
让您的服务对用户空间可见的另外一种方法是通过 /proc 文件系统。/proc 文件系统是一个虚拟文件系统,您可以通过它来向用户提供一个目录和文件,然后通过文件系统接口(读、写等)在内核中为新服务提供一个接口。
使用 strace 跟踪系统调用
Linux 内核提供了一种非常有用的方法来跟踪某个进程所调用的系统调用(以及该进程所接收到的信号)。这个工具就是 strace,它可以在命令行中执行,使用希望跟踪的应用程序作为参数。例如,如果您希望了解在执行 date 命令时都执行了哪些系统调用,可以键入下面的命令:
| strace date |
结果会产生大量信息,显示在执行 date 命令过程中所执行的各个系统调用。您会看到加载共享库、映射内存,最后跟踪到的是在标准输出中生成日期信息:
...
write(1, "Fri Feb 9 23:06:41 MST 2007\n", 29Fri Feb 9 23:06:41 MST 2007) = 29
munmap(0xb747a000, 4096) = 0
exit_group(0) = ?
$
当当前系统调用请求具有一个名为 syscall_trace 的特定字段集(它导致 do_syscall_trace 函数的调用)时,将在内核中完成跟踪。您还可以看到跟踪调用是 ./linux/arch/i386/kernel/entry.S 中系统调用请求的一部分(请参看 syscall_trace_entry)。
结束语
系统调用是穿越用户空间和内核空间,请求内核空间服务的一种有效方法。不过对这种方法的控制也很严格,更简单的方式是增加一个新的 /proc 文件系统项来提供用户/内核间的交互。不过当速度因素非常重要时,系统调用则是使应用程序获得最佳性能的理想方法。请参看 参考资料 的内容进一步了解 SCI。
一、 什么是系统调用
在Linux的世界里,我们经常会遇到系统调用这一术语,所谓系统调用,就是内核提供的、功能十分强大的一系列的函数。这些系统调用是在内核中实现的,再
通过一定的方式把系统调用给用户,一般都通过门(gate)陷入(trap)实现。系统调用是用户程序和内核交互的接口。
二、 系统调用的作用
系统调用在Linux系统中发挥着巨大的作用,如果没有系统调用,那么应用程序就失去了内核的支持。
我们在编程时用到的很多函数,如fork、open等这些函数最终都是在系统调用里实现的,比如说我们有这样一个程序:
系统调用的主要任务是把进程从用户态切换到内核态。在具有保护机制的计算机系 统中,用户必须通过软件中断或陷阱,才能使进程从用户态切换为内核态。
在i386体系中,Linux的系统调用接口是通过调用软中断指令“int 0x80”使进程从用户态进入内核态的,这个过程也叫做“陷入”。当系统调用接口调用软中断指令“int 0x80”时,这个指令会发生一个中断向量码为128的中断请求,并在中断响应过程中将进程由用户态切换为内核态。
因为Linux只允许系统调用接口使用128这一个软中断向量,这也就意味着所有的系统调用接口必 须共享这一个中断通道,并在同一个中断服务例程中调用不同的内核服务例程,所以,系统调用接口除了要引发“int 0x80”软中断之外,为了进人内核后能调用不同的内核服务例程,还要提供识别内核服务例程的参数,这个参数叫做“系统调用号”。也就是说,所有可为进程 提供服务的内核服务例程都应具有一个唯一的系统调用号。当然,系统调用接口还应为内核服务例程准各必要的参数。
综上所述,系统调用接口需要完成以下几个任务:
●用软中断指令“int 0x80”发生一个中断向量码为128的中断请求,以使进程进入内核态。
●要保护用户态的现场,即把的用户态运行环境保护到进程的内核堆栈。
●为内核服务例程准备参数,并定义返回值的存储位置。
●跳转到系统调用例程。
●系统调用例程结束后返回。
系统调用例程是系统提供的一个通用的汇编语言程序.其实它是一个中断向量为128的中断服务程序,其入口为system_call。它应完成的任务有:
●接受系统调用接口的参数。
●根据系统调用号,转向对应的内核服务例程,并将相关参数传遴给内核服务例程。
●在内核服务例程结束后,自中断返田到系统凋甩接口.
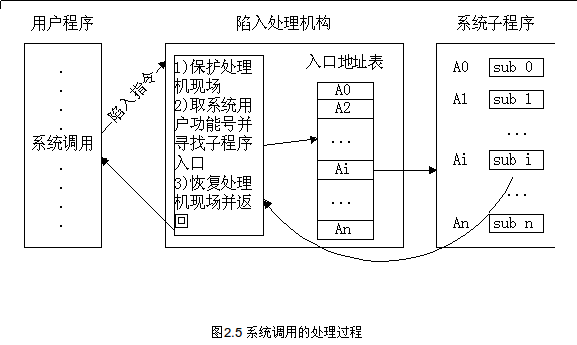
系统调用的过程如图所示。
从图中可以看到,系统调用接口是用高级语言来编写的,而通过调用中断指令陷入内核后的系统调用例程(即图中的系统调用处理程序)则是用汇编语言编写的。
为了通过系统调用号来调用不同的内核服务例程,系统必须维护一个系统调用表,这个表实质上就是系统
调用号与内核服务函数的对照表。Linux是用数组sys_call_tabl来作为这个表的,在这个表的每个表项中存放着对应内核服务例程的指针,而该
表项的下标就是该内核服务例程的系统调用号。Linux规定,在体系中,系统调用号由处理器的寄存器eax来传递。
图 系统调用的处理过程
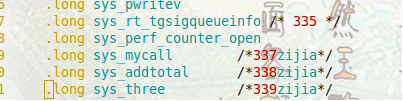
系统调用表Sys_call_table的部分内容列举如下:
欢迎转载,信息来自维库市场网()
所以,如果希望改变一个系统调用的函数,需要做的是编写一个自己的函数,然后改变sys_call_table中的指针指向该函数,最后再使用 cleanup_module将系统调用表恢复到原来的状态。我们现在向内核中添加的三个系统调用就是属于向内核中添加新的函数,且这些函数是可以直接操 作系统内核的。下面是系统调用的基本处理过程:
系统实现:
这里以具体的例子来说明如何向系统中添加新的系统调用。具体实现所用的文件等可能与上面所述有点不一致,但原理是相同的。