分类: 系统运维
2011-04-28 16:08:06
一、编程与调优难
2009年,北京大学信息学院的陈一峯教授在一套由16个节点组成GPU集群上成功进行了三维大规模傅立叶(3D FFT)变换数学库的研究。与另外一套同期购置的64节点CPU集群相比,GPU集群的成本只有40%,但却实现了3倍的FFT性能,在国内外同行中引发关注。

虽然效果不错,但在专门研究并行语言的陈一峯看来,实现过程却并非易事。他分析道,在GPU系统上高效实现3D FFT,主要存在三大“难点”:一是算法难,二是编程难,三是几乎不可能实现的程序可移植性。
他展示了一段代码,这段500多行的代码穿插使用了CUDA、Pthread、MPI、Infiniband/verbs四种编程工具。“要写出这段代码,不仅要求学会这四种编程工具,还要在一个程序中实现联合编译,其难度可想而知。”

不过,中科院软件所高级工程师姚继峰表达了另一个有意思的观点:“目前在8核、16核的上写高性能并行代码同样不容易,需要同时用到MPI和OpenMP,与其折腾这个,还不如去折腾GPU编程。”毕竟,有了GPU加速,就能够带来数倍、十倍甚至百倍的效率提升,加上GPU集群在性能功耗比、占地面积、成本等方面的优势,确实值得应用单位和开发人员放手一搏。
姚继峰认为,2007年CUDA(Compute Unified Device Architecture)开发平台的出现其实已经大大降低了GPU的编程难度,但问题是性能需要进行调优,而调优非常困难——仅GPU本身优化就得考虑寄存器使用、共享、访问、L1/L2缓存、线程数、数据传输等多方面因素,而且GPGPU集群(GPU的通用计算)需要与GPU协同工作,因此还得考虑CPU与GPU间任务分配与协同,以及多GPU负载均衡,软件在不同平台间移植等棘手问题。

为此,早在2008年,中科院软件所研究员、中国高性能计算机TOP100排行榜创始人之一张云泉博士就组建了相应团队,进行了《基于NVIDIA Fermi GPU的Linpack性能优化》、《混合精度的HPL软件包实现与优化》、《基于OpenCL的SpMV自适应优化》、《FFTH的GPU优化》、《基于AMD/ATI GPU的Linpack性能优化》等一系列性能调优研究。
二、软件移植性差
在陈一峰看来,GPU编程最大的问题还在于几乎不可能实现的程序可移植性,“我们这段代码只是为这台16节点的机器编写,如果要跑在另外一台机器上面,几乎要重写程序。在标准集群上我们有MKL TTF和FFTW,但在GPU上很难,问题非常复杂。”
确实如此,用户一般都不希望把代码绑定在某一套或某一家厂商的硬件平台之上,而是希望一次编写的软件包可以自适应多种GPU,适应不同时期,不同架构的硬件平台。软件不可移植意味着用户针对某个GPU平台编写的程序不能平滑地运行在其他GPU或CPU硬件平台上,用户在软件方面的投资就无法得到延续与保护。另外,从商业软件来看,传统高性能计算领域的很多软件都是为X86集群编写的,如何把它们移植到GPU平台上并保持高效率,也是用户最关心的问题之一。

其实,Nvidia早已经注意到了这一问题。Nvidia中国PSG销售经理谢强表示,为了支持其他CPU、GPU硬件平台,CUDA C/C++也开始提供多种调优工具,让开发人员将在CUDA平台上写的程序进行转换,从而运行在多核CPU和AMD的GPU上面。尽管这还无法一步到位地解决所有程序在异构平台之间平滑移植的挑战,但至少让用户看到了一线曙光。
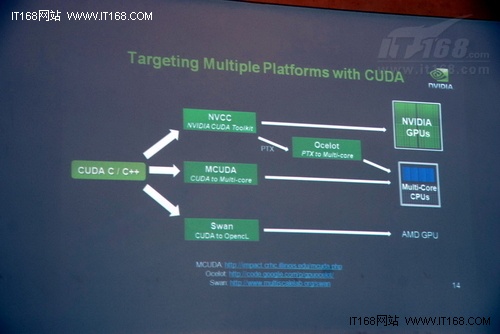
三、生态系统尚待完善
针对GPU的软件开发,目前可选的工具主要有CUDA C、OpenCL、Intel Ct、微软DirectCompute等。相对而言,CUDA是其中发展最为成熟的,CUDA C、OpenCL、DirectCompute都能融合在CUDA的架构上,但整体的开发环境还有待完善,至少与CPU相比,Debug、Profiling、TuningBUG等工具还要差一些。另外,现在能够进行GPU编程与开发的人才很缺,大多仅集中在科研院所、高校及极少数企业中。
谢强在会上专门做了《GPU高效能计算及生态系统》的演讲,他谈到,Nvidia一直在打造围绕GPU并行计算的开发人员生态系统,包括多种数学库、调优工具、GPU编译器、并行化编译工具、各种工具包、CUDA咨询与培训以及众多的GPU计算解决方案。这个生态系统正在不断扩大,CUDA的魅力正是在于提供了更完整的系列工具。比如,在大家普遍关心的编程工具方面,CUDA已经可以支持C/C++、Fortrain、OpenCL、Java、Python、DirectCompute等。在数学库方面,除MATLAB、Mathematica之外,更多的厂家已经开始把核心数学库移植到CUDA上来,开发程序员面对的是一个完善的开发环境和工具包,可以做各种应用的开发与调优。

从应用软件来看,来自石油天然气、生命科学、视频渲染、金融分析、CAE、EDA等领域的专业公司正在用CUDA开发程序或进行移植。“生命科学是目前CUDA应用最完善的领域。”此外,Nvidia也在计划在全球推出CUDA认证,目前全球已经有350所学校开通了CUDA课程,在国内,北大、清华、中科院将提供CUDA培训与认证服务。
总之,一个完整的GPU通用计算(GPGPU)环境既包括硬件设备,也包括程序开发和运行环境如编译器、调试器、运行时库等,以及其它各种性能调优与任务管理工具。跟普通的多核CPU相比,集成数百内核的GPU在并行计算方面的硬件优势已经得到普遍认可——成本低、功耗低、体积小、性能高,但仅有硬件是远远不夠的,软件应用更加关键。
