分类: IT业界
2011-04-28 10:33:00
但GPU是最好的高性能计算加速器吗?从历史看,是;放眼未来,则未必。
中国科学院过程工程研究所是国内GPGPU应用较早的单位之一。早在2008年2月,过程所就购置了100Tflops的+GPU集群系统,经过不断升级,其规模已经突破千万亿次每秒,其Mole-8.5系统在最新全球TOP500高性能计算机排行榜中名列第19位。

在6月7日由中国软件行业协会主办的“2010年中国高效能计算应用高峰论坛”上,中国科学院过程工程研究所研究员、超级计算系统项目负责人葛蔚介绍了在GPU超级计算系统进行多尺度离散模拟的项目情况。在演讲中,他提出,“虽然目前来看,GPU计算是一种新兴的技术,但从长远来看,GPU还不是多尺度模拟最佳的选择。”
他分析说,GPGPU并行计算是从传统的图形处理领域“借用”过来的,过去所有尺度都是用来模拟,目前进行多尺度分层并行之后,宏尺度和介尺度的模拟在进行,但微尺度模拟已经开始使用GPU,效率大大提升。但问题是,对于介观来说,应该有更合适的一种处理器,“我们不知道叫什么,就叫‘XPU’吧,但它不是,也不会是GPU。”
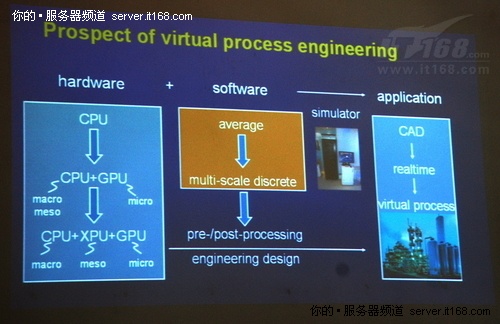
对于这个“XPU”是什么,NVIDIA与英特尔给出的答案显然不一样。
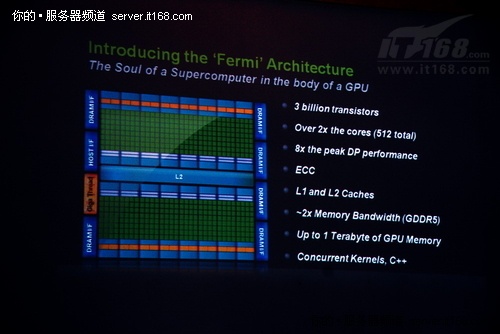
NVIDIA目前推荐给用户的是其最新专门为高性能计算优化的新一代处理器架构:Fermi。虽然脱胎于传统的GPU,但跟上一代产品相比,基于Fermi架构的Tesla处理器有了“革命性”的改变:拥有30亿颗晶体管,512个计算内核,双精度性能提升8倍,带有ECC校验功能,增加了L1和L2两级缓存,带宽提高两倍,理论上支持1TB GPU。随着Fermi的推出,过去GPU在硬件层面的许多问题已经得到解决或缓解,如缺少ECC检验,双精度性能低都已得到解决,GPU也在不断增大,但总线和带宽仍然是瓶颈。可见,Fermi跟传统的GPU已经有了很大的不同,增加了一些过去只有才有的功能特性,如缓存结构、ECC校验等,但其根本仍然没有摆脱GPU的范畴。
英特尔过去也试图向用户提供自己的GPU产品Larrabee,但现在它更喜欢向用户推介另外一种选择:X86集成众核处理器。就象是半路杀出个“程咬金”,它不是普通的,也不是GPU。
在这次论坛上,英特尔高性能计算专家何万青博士介绍了这一新产品:英特尔集成众核(MIC)架构。其实,这一架构是在5月底SC2010(超级计算大会)上正式对外宣布的。据了解,MIC架构衍生自几个英特尔项目(包括Larrabee GPU)和英特尔实验室的研究项目,如48核单芯片云计算机(SCC)。基于MIC架构的首款产品(研发代号:Knights Corner)将拥有50个计算内核,主要面向勘探、科学研究以及金融或气象模拟等高性能计算领域,将采用22纳米制程工艺生产,预计在2012年推向市场。不过,目前英特尔已经开始向少数合作伙伴提供配置为“32核、1.2GHz、每核4线程共128线程、8MB共享一致性缓存”的工程样品(代号:Knights Ferry),以及相应的SDK和API。

何万青表示,在英特尔看来,高性能计算领域85%以上的应用其实都可以通过X86多核通用来实现高效运行,只有少数一些SIMD单指令多数据或对大规模数据进行简单处理的应用才适合用更强大的众核来高度并行。

虽然都是众核,但MIC跟GPU最大的不同在于,MIC基于标准的X86架构,其最大的好处就是软件开发平台统一,毕竟现在高性能计算领域绝大多数软件都是在X86平台上开发出来的。“我们让生物专家、化学专家们把精力放在自己的专业上,而不是去学新的编程模式,同时用户在软件开发方面的投资能够得到保护。”
而软件编程难、调优难、可移植性差正是GPU当前的软肋,英特尔正试图用MIC架构来拿住对手。据何万青介绍,英特尔在高性能计算市场上的一个最大决策就是不断进行软件投资,在保持一致性的基础上提供丰富的工具,以在不同级别不断提高指令、数据、线程、进程、任务的并行效率,优化应用。
当然,NVIDIA并没有闲着,它正在围绕GPU并行计算不断扩大开发人员的生态系统,包括多种数学库、调优工具、GPU编译器、并行化编译工具、各种工具包、CUDA咨询与培训以及众多的GPGPU计算解决方案。
可见,NVIDIA和英特尔面前的路都不平坦。但至少在2012年MIC产品正式面市之前,高性能计算用户可选的最好加速器相信仍然是让人又爱又恨的GPU。而且,英特尔得保证MIC不会象之前的Larrabee那样频繁跳票,并且也需要保证MIC在硬件和软件两个层面确实能让用户体验到独特价值。
