雄关漫道真如铁,而今迈步从头越。
全部博文(348)
分类: IT职场
2020-03-07 16:40:44
经过超过半年的研发,蚂蚁金服在今年完成了 Kubernetes 的全面落地,并使得核心链路100% 运行在 Kubernetes。到今年双十一,蚂蚁金服内部通过 Kubernetes 管理了数以万计的机器以及数十万的业务实例,超过90%的业务已经平稳运行在 Kubernetes 上。整个技术切换过程平稳透明,为云原生的资源基础设施演进迈好了关键的一步。
本文主要介绍 Kubernetes 在蚂蚁金服的使用情况,双十一大促对 Kubernetes 带来史无前例的挑战以及我们的最佳实践。希望通过分享这些我们在实践过程中的思考,让大家在应用 Kubernetes 时能够更加轻松自如。
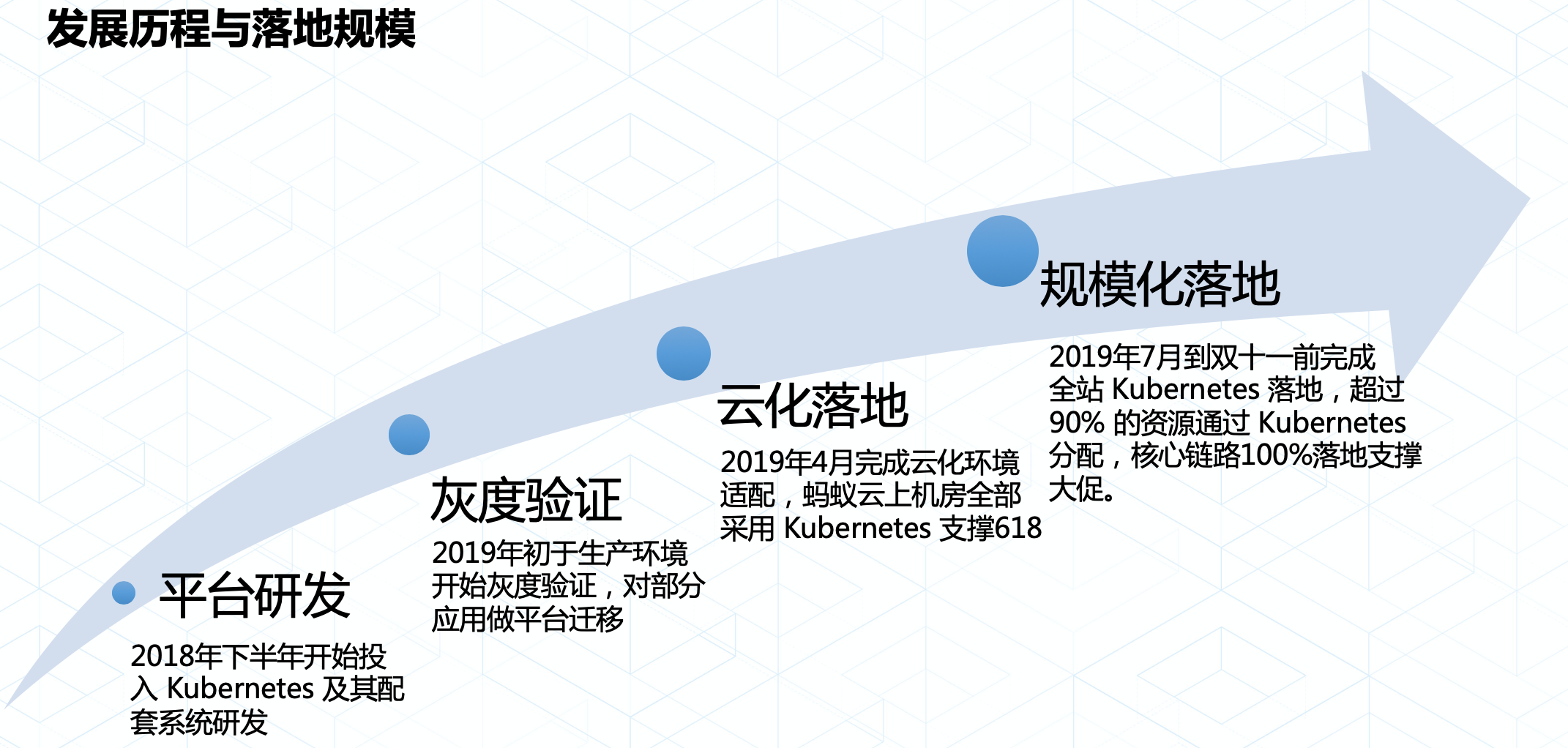 Kubernetes 在蚂蚁金服落地主要经历了四个阶段:
Kubernetes 在蚂蚁金服落地主要经历了四个阶段:
Kubernetes 承载了蚂蚁金服在云原生时代对资源调度的技术目标:统一资源调度。通过统一资源调度,可以有效提升资源利用率,极大的节省资源成本。要做到统一调度,关键在于从资源层面将各个二层平台的调度能力下沉,让资源在 Kubernetes 统一分配。
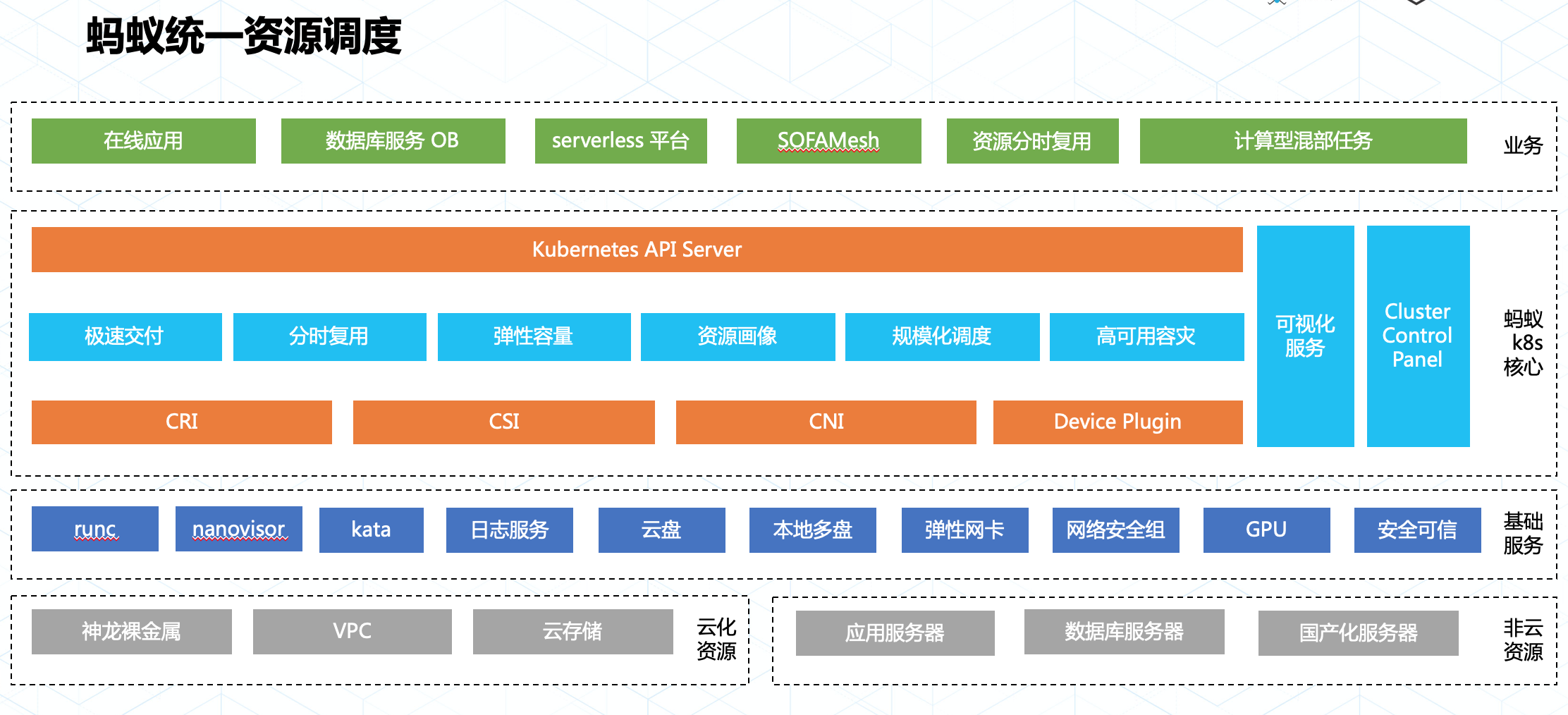
蚂蚁金服在落地 Kubernetes 实现统一调度目标时遵循了标准化的扩展方式:
得益于持续的标准化工作,我们在落地 Kubernetes 的大半年内应用了多项技术,包含安全容器,统一日志,GPU 精细调度,网络安全隔离及安全可信计算等,并通过 Kubernetes 统一使用和管理这些资源服务了大量在线业务以及计算任务型业务。
下面我们通过以下几种场景介绍蚂蚁金服内部是如何使用 Kubernetes,以及在此过程中我们面对的挑战和实践之路。
在大促过程中,不同业务域的洪峰流量通常都是在不同时间段来临,而应对这些不同时间到来的业务流量往往都需要大量的额外计算资源做保障。在以往的几次活动中,我们尝试了通过应用快速腾挪的方式来做到资源上的分时复用,但是服务实例上下线需要预热,腾挪耗时不可控,大规模调度的稳定性等因素都影响了最终腾挪方案的实践效果。
今年双十一我们采用了资源共享调度加精细化切流的技术以达到资源分时利用的目标,为了达到资源充分利用和极速切换的目标,我们在以下方面做了增强:
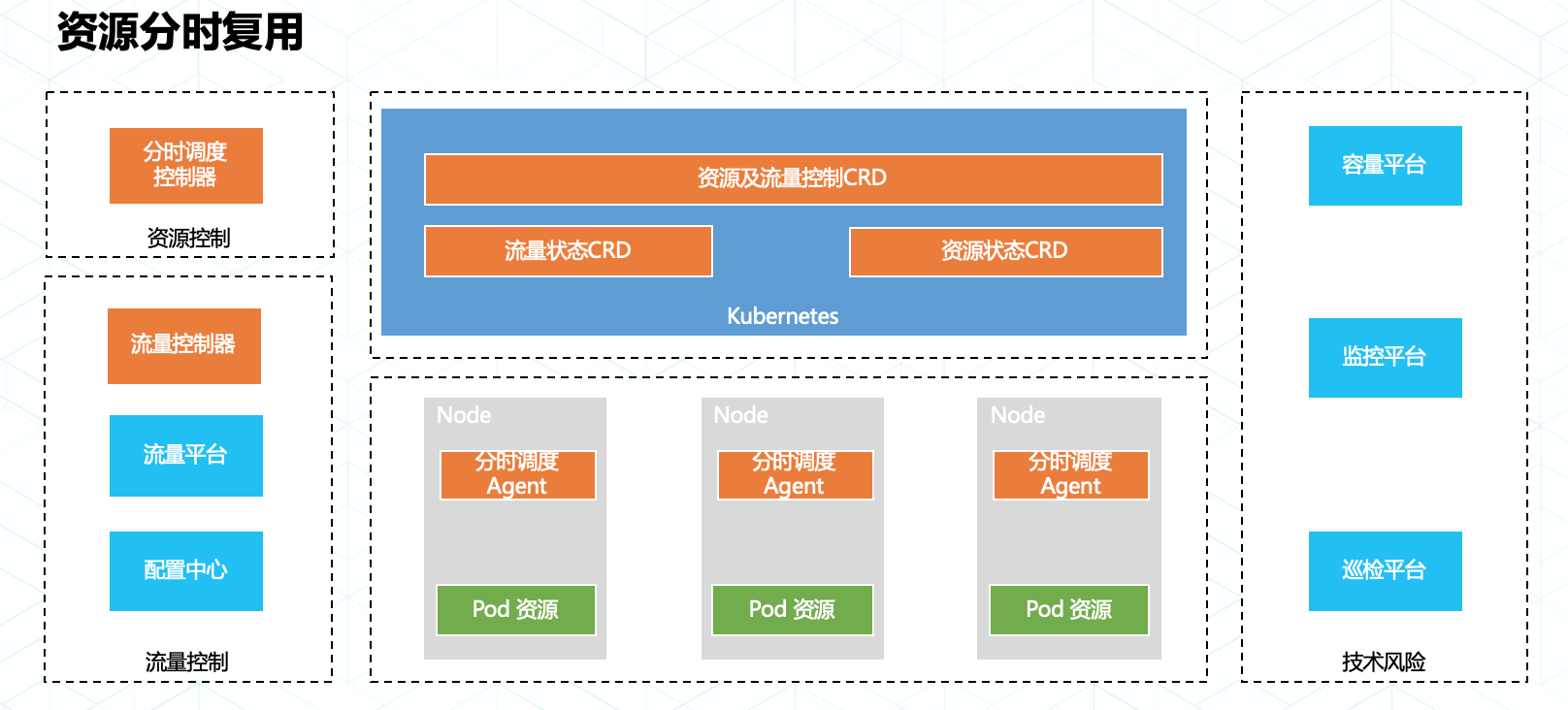
整套平台和技术最终实现了令人激动的成果:蚂蚁金服内部不同业务链路数以万计的实例实现了最大程度的资源共享,这些共享资源的实例可分钟级完成平滑切换。这种技术能力也突破了当下资源水平伸缩能力的效率限制,为资源的分时复用打开了想象空间。
Kubernetes 社区的落地案例中,我们往往看到的都是各种各样的在线业务,计算型业务往往通过“圈地”式的资源申请和独立的二层调度跑在 Kuberentes 集群中。但是在蚂蚁内部我们从决定使用 Kubernetes 的第一天起,就将 Kubernetes 融合计算型业务实现资源的统一调度作为我们的目标。
在蚂蚁金服内部我们持续的使用 Kubernetes 支持各类计算业务,例如各类AI 训练任务框架,批处理任务和流式计算等。他们都有一个共同的特点:资源按需申请,即用即走。
我们通过 Operator 模型适配计算型任务,让任务在真正执行时才会调用 Kubernetes API 申请 Pod 等资源,并在任务退出时删除 Pod 释放资源。同时我们在调度引擎中引入了动态资源调度能力和任务画像系统,这为在线和计算的不同等级业务提供了分级资源保障能力,使在线业务不受影响的情况下资源被最大化的利用。
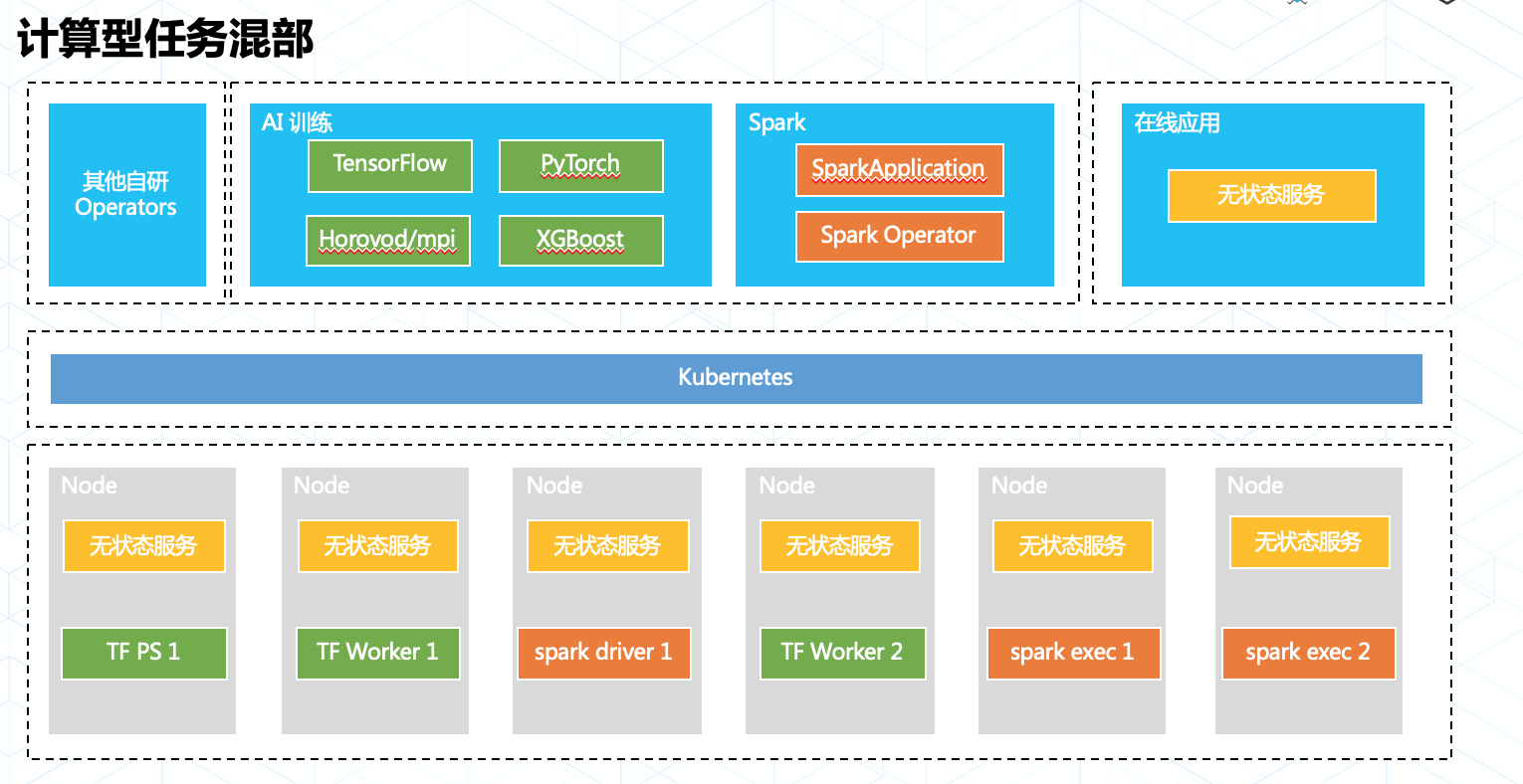
今年双十一除了洪峰时间段(00:00~02:00),蚂蚁金服 Kubernetes 上运行的任务均未做降级,每分钟仍有数以百计的计算任务在 Kubernetes 上申请和释放。未来蚂蚁金服内部将会持续推动业务调度融合,将 Kubernetes 打造成为资源调度的航空母舰。
蚂蚁金服是目前少数运行了全球最大规模的 Kubernetes 集群的公司之一,单集群机器规模过万,Pods 数量数十万。随着类似计算型任务混部和资源分时复用这类业务的落地,资源的动态使用以及业务自动化运维都对 Kubernetes 的稳定性和性能带来的巨大的挑战。
首先需要面对的挑战是调度性能,社区的调度器在5k规模测试中调度性能只有1~2 pods/s,这显然无法满足蚂蚁金服的调度性能需求。

针对同类业务的资源需求往往相同的特点,我们自研了批量调度功能,再加上例如局部的filters性能优化等工作,最终达到了百倍的调度性能提升!
在解决了调度性能问题后,我们发现规模化场景下 APIServer 逐渐成为了影响 Kubernetes 可用性的关键组件,CRD+Operator 的灵活扩展能力更是对集群造成巨大的压力。业务方有100种方法可以玩垮生产集群,让人防不胜防。
造成这种现象一方面是由于社区今年以前在规模化上的投入较少 APIServer 能力较弱,另一方面也是由 Operator 模式的灵活性决定。开发者在收益于 Operator 高灵活度的同时,往往为集群管理者带来业务不受控制的风险。即使对 Kubernetes 有一定熟悉程度的开发者,也很难保障自己写出的 Operator 在生产中不会引爆大规模的集群。

面对这种“核按钮”不在集群管理员手上的情况,蚂蚁内部通过两方面入手解决规模化带来的问题:
2.我们已经在 Kubernetes 实施了一系列的优化,包含多维度流量控制,WatchCache 处理全量 List 请求,controller 自动化解决更新冲突,以及 APIServer 加入自定义索引等。
通过规范和优化,我们从 client 到 server 对 API 负载做了整体链路的优化,让资源交付能力在落地的大半年内提升了6倍,集群每周可用率达到了3个9,让 Kubernetes 平稳顺滑的支撑了双十一的大促。
近几年大促蚂蚁金服都会充分利用云化资源,通过快速弹性建站的方式将全站业务做“临时”扩容,并在大促后回收站点释放资源。这样的弹性建站方式为蚂蚁节省了大量的资源开支。
Kubernetes 提供了强大的编排能力,但集群自身的管理能力还比较薄弱。蚂蚁金服从 0 开始,基于 Kubernetes on Kubernetes 和面向终态的设计思路,开发了一套管理系统来负责蚂蚁几十个生产集群的管理,提供面向大促的快速弹性建站功能。
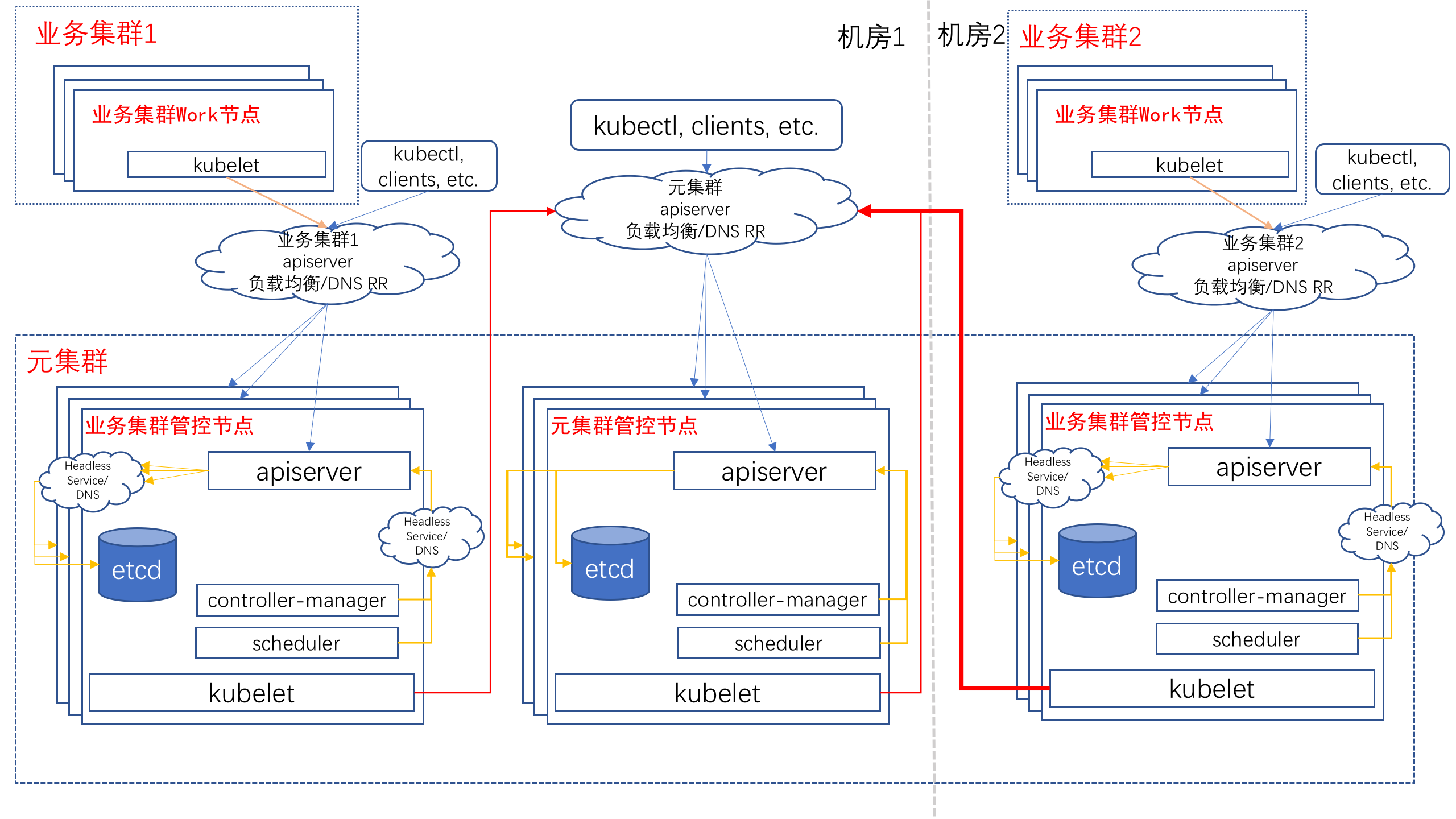
通过这种方式我们可以自动化的完成站点搭建,3小时内交付可立即使用的包含数千个 Nodes 的 Kubernetes 集群。今年双十一我们在一天内交付了全部弹性云化集群,随着技术的不断提升和磨练,我们期望未来能够按天交付符合业务引流标准的集群,让蚂蚁金服的站点随时随地可弹。
云原生时代已经到来,蚂蚁金服内部已经通过 Kubernetes 迈出了云原生基础设施建设的第一步。虽然当前在实践中仍然有许多挑战在等着我们去应对,但相信随着我们在技术上持续的投入,这些问题会一一得到解决。
当前我们面对的一大挑战是多租户带来的不确定性。蚂蚁金服内部不可能为每个业务部门都维护一套Kubernetes集群,而单个 Kubernetes 集群的多租户能力十分薄弱,这体现在以下两个维度:

未来我们会在核心能力如 Priority and Fairness for API Server Requests 以及 Virtual Cluster 上持续的做技术投入和应用,有效保障租户的服务能力保障和隔离。
除了资源调度,Kubernetes 下一阶段的重要场景就是自动化运维。这涉及到应用资源全生命周期的面向终态自行维护,包含但不限于资源自动交付及故障自愈等场景。
随着自动化程度的不断提升,如何有效控制自动化带来的风险,让自动化运维能够真正提升效率而不是任何时刻都需要承担删库跑路的风险是接下来的一个重要难题。
蚂蚁金服在落地 Kubernetes 的过程中经历过类似的情况:从初期高度自动化带来无限的兴奋,到遭遇缺陷不受控制最终爆炸引发故障后的无比沮丧,这些都说明了在 Kubernetes 上做自动化运维仍有很长的路要走。
为此我们接下来和阿里集团兄弟部门一起推动 Operator 的标准化工作。从接入标准,Operator 框架,灰度能力建设和控制治理上入手,让 Kubernetes 上的自动化运维变的更加可视可控。
今年我们实现了 Kubernetes 由 0-1 的落地,经受了双十一双大促真实场景的考验。但云原生的基础设施建设仍是刚刚起步,接下来我们将在弹性资源交付,集群规模化服务以及技术风险与自动化运维上持续发力,以技术支撑和推动业务服务完成云原生的落地。
最后,也欢迎志同道合的伙伴加入我们,一起参与建设云原生场景下的基础设施!可点击【金融级分布式架构】公众号【加入我们】-【超多岗位】 tab 获取职位信息。
曹寅,蚂蚁金服 Kubernetes 落地负责人,2015年加入蚂蚁金服,主要从事容器技术及平台研发相关工作,2018年开始负责蚂蚁Kubernetes的研发落地。 曾在阿里云弹性计算工作四年
