分类: LINUX
2012-07-05 16:38:28
案例应用:红帽企业群集和存储管理之
mysql服务器的HA集群之corosync+drbd+pacemaker实现-下篇
上篇地址:
http://blog.chinaunix.net/space.php?uid=25472972&do=blog&id=3264461
接上篇!!!
5.1 配置群集的工作属性
[root@node1 ~]# crm configure property stonith-enabled=false
[root@node2 ~]# crm configure property stonith-enabled=false
[root@node1 ~]# crm configure property no-quorum-policy=ignore
[root@node2 ~]# crm configure property no-quorum-policy=ignore
INFINITY:如果不是因节点不适合运行资源(节点关机、节点待机、达到migration-threshold 或配置更改)而强制资源转移,资源总是留在当前位置。此选项的作用几乎等同于完全禁用自动故障回复;
[root@node1 ~]# crm configure rsc_defaults resource-stickiness=100
[root@node2 ~]# crm configure rsc_defaults resource-stickiness=100
5.2 定义群集服务及资源
5.2.1 改变drbd的状态
0:mysql Connected Primary/Secondary UpToDate/UpToDate C r----
0:mysql Connected Secondary/Secondary UpToDate/UpToDate C r----
0:mysql Connected Secondary/Secondary UpToDate/UpToDate C r----
0:mysql Connected Primary/Secondary UpToDate/UpToDate C r----
5.2.2 配置drbd为群集资源
property $id="cib-bootstrap-options" \
dc-version="1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f" \
cluster-infrastructure="openais" \
expected-quorum-votes="2" \
stonith-enabled="false" \
2、将已经配置好的DRBD设备/dev/drbd0定义为集群服务;
[root@node1 ~]# ssh node2 'chkconfig drbd off'
3、配置drbd为集群资源:
drbd
4、查看drbd的资源代理的相关信息:
as a master/slave resource. DRBD is a shared-nothing replicated storage
Parameters (* denotes required, [] the default):
The name of the drbd resource from the drbd.conf file.
drbdconf (string, [/etc/drbd.conf]): Path to drbd.conf
Full path to the drbd.conf file.
start timeout=240
promote timeout=90
demote timeout=90
notify timeout=90
stop timeout=100
monitor_Slave interval=20 timeout=20 start-delay=1m
monitor_Master interval=10 timeout=20 start-delay=1m
5、drbd需要同时运行在两个节点上,但只能有一个节点(primary/secondary模型)是Master,而另一个节点为Slave;因此,它是一种比较特殊的集群资源,其资源类型为多状态(Multi-state)clone类型,即主机节点有Master和Slave之分,且要求服务刚启动时两个节点都处于slave状态。
crm(live)configure# primitive mysqldrbd ocf:heartbeat:drbd params drbd_resource="mysql" op monitor role="Master" interval="30s" op monitor role="Slave" interval="31s" op start timeout="240s" op stop timeout="100s"
crm(live)configure# ms MS_mysqldrbd mysqldrbd meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify="true"
params drbd_resource="mysql" \
op monitor interval="30s" role="Master" \
op monitor interval="31s" role="Slave" \
op start interval="0" timeout="240s" \
op stop interval="0" timeout="100s"
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true"
确定无误后,提交:
6、查看当前集群运行状态:
Current DC: node1.junjie.com - partition with quorum
Masters: [ node1.junjie.com ]
Slaves: [ node2.junjie.com ]
Primary/Secondary
0:mysql Connected Primary/Secondary UpToDate/UpToDate C r----
crm(live)configure# primitive MysqlFS ocf:heartbeat:Filesystem params device="/dev/drbd0" directory="/mnt/mysqldata" fstype="ext3" op start timeout=60s op stop timeout=60s
params device="/dev/drbd0" directory="/mnt/mysqldata" fstype="ext3" \
op start interval="0" timeout="60s" \
op stop interval="0" timeout="60s"
7、mysql资源的定义(node1上操作)
[root@node1 ~]# crm configure primitive myip ocf:heartbeat:IPaddr params ip=192.168.101.88
[root@node1 ~]# crm configure primitive mysqlserver lsb:mysqld
Current DC: node1.junjie.com - partition with quorum
Masters: [ node1.junjie.com ]
Slaves: [ node2.junjie.com ]
8、配置资源的各种约束:
1)Resource Location(资源位置):定义资源可以、不可以或尽可能在哪些节点上运行
2)Resource Collocation(资源排列):排列约束用以定义集群资源可以或不可以在某个节点上同时运行
3)Resource Order(资源顺序):顺序约束定义集群资源在节点上启动的顺序。
1)任何值 + 无穷大 = 无穷大
2)任何值 - 无穷大 = -无穷大
3)无穷大 - 无穷大 = -无穷大
crm(live)configure# colocation MysqlFS_with_mysqldrbd inf: MysqlFS MS_mysqldrbd:Master myip mysqlserver
crm(live)configure# order MysqlFS_after_mysqldrbd inf: MS_mysqldrbd:promote MysqlFS:start
crm(live)configure# order myip_after_MysqlFS mandatory: MysqlFS myip
crm(live)configure# order mysqlserver_after_myip mandatory: myip mysqlserver
colocation MysqlFS_with_mysqldrbd inf: MysqlFS MS_mysqldrbd:Master myip mysqlserver
order MysqlFS_after_mysqldrbd inf: MS_mysqldrbd:promote MysqlFS:start
order mysqlserver_after_myip inf: myip mysqlserver
9.查看配置信息和状态,并测试:
params device="/dev/drbd0" directory="/mnt/mysqldata" fstype="ext3" \
op start interval="0" timeout="60s" \
op stop interval="0" timeout="60s"
params ip="192.168.101.88"
params drbd_resource="mysql" \
op monitor interval="30s" role="Master" \
op monitor interval="31s" role="Slave" \
op start interval="0" timeout="240s" \
op stop interval="0" timeout="100s"
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true"
colocation MysqlFS_with_mysqldrbd inf: MysqlFS MS_mysqldrbd:Master myip mysqlserver
order MysqlFS_after_mysqldrbd inf: MS_mysqldrbd:promote MysqlFS:start
order mysqlserver_after_myip inf: myip mysqlserver
property $id="cib-bootstrap-options" \
dc-version="1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f" \
cluster-infrastructure="openais" \
expected-quorum-votes="2" \
stonith-enabled="false" \
Current DC: node1.junjie.com - partition with quorum
Version: 1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
Masters: [ node1.junjie.com ]
Slaves: [ node2.junjie.com ]
可见,服务现在在node1上正常运行:
在node1上的操作,查看群集的运行状态:
/dev/drbd0 on /mnt/mysqldata type ext3 (rw)
drwxr-xr-x 5 mysql mysql 4096 Feb 8 00:05 data
-rw-r--r-- 1 root root 4 Feb 7 21:28 f1
-rw-r--r-- 1 root root 0 Feb 7 21:28 f2
drwx------ 2 root root 16384 Feb 7 21:26 lost+found
eth0:0 Link encap:Ethernet HWaddr 00:0C:29:AE:83:D1
inet addr:192.168.101.88 Bcast:192.168.101.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:67 Base address:0x2000
在node2上的操作,查看群集的运行状态:
eth0:0 Link encap:Ethernet HWaddr 00:0C:29:D1:D4:32
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:67 Base address:0x2000
10.继续测试群集:
Current DC: node1.junjie.com - partition with quorum
Version: 1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
Node node1.junjie.com: standby
Stopped: [ mysqldrbd:0 ]
在node2上的操作,查看群集的运行状态:
可见我们的资源已经都切换到了node2上:
/dev/drbd0 on /mnt/mysqldata type ext3 (rw)
drwxr-xr-x 5 mysql mysql 4096 Feb 8 00:16 data
-rw-r--r-- 1 root root 4 Feb 7 21:28 f1
-rw-r--r-- 1 root root 0 Feb 7 21:28 f2
drwx------ 2 root root 16384 Feb 7 21:26 lost+found
eth0:0 Link encap:Ethernet HWaddr 00:0C:29:D1:D4:32
inet addr:192.168.101.88 Bcast:192.168.101.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:67 Base address:0x2000
mysql> grant all on *.* to user1@'192.168.%.%' identified by '123456';
客户端访问测试
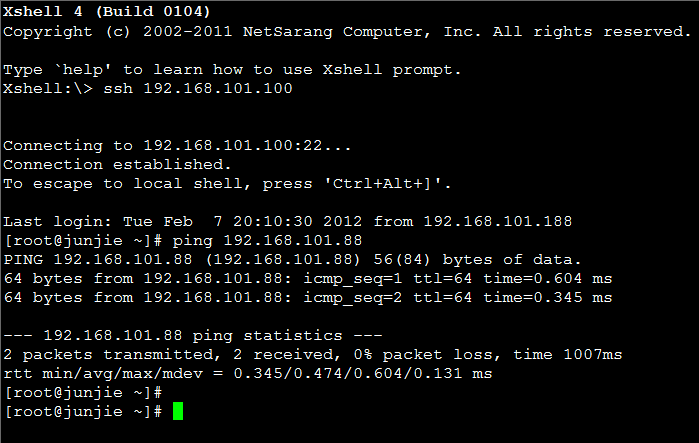
192.168.101.100客户Ping测试192.168.101.88
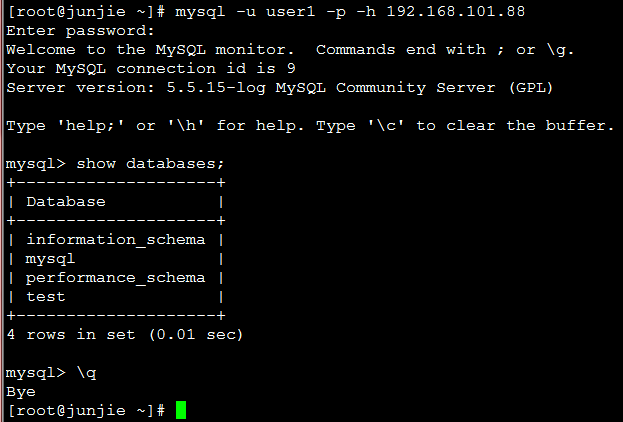
192.168.101.100客户访问mysql数据库192.168.101.88(成功访问)
至此:使用corosync+drbd+pacemaker实现mysql服务器的高可用集群成功完成!.
《完》
--xjzhujunjie
--2012/06/03
上篇地址:
http://blog.chinaunix.net/space.php?uid=25472972&do=blog&id=3264461
接上篇!!!
