对于只是实现简单功能的c语言程序,不用考虑代码reorder问题。
现在才发现原来在编译程序的时候,通过gcc -O0来避免编译时,编译器将不会对指令重排。但是
这样仍然无法避免在运行的时候CPU对指令进行重排。所以使用内存屏障是非常重要的,也是无法避免的。
这里我有一个疑问,是否在java中也会遇到指令重排的问题呢?
上面是对指令重排问题的一点探讨,下面对CPU cache进行分析。
下面的这个链接里面 讲述了如何用c语言观察CPU 的cache行为:对于**的阻拦,最好的方法就是通过在线代理服务器的方式访问入口
第一个程序
-
int[] arr = new int[64 * 1024 * 1024];
-
-
// Loop 1
-
for (int i = 0; i < arr.Length; i++) arr[i] *= 3;
-
-
// Loop 2
-
for (int i = 0; i < arr.Length; i += 16) arr[i] *= 3;
Loop1与Loop2的执行时间是几乎相同的,CPU取内存中的数据都是以Cache Liine的方式取,大小为64Byte。由于顺序访问,访问到同一cache line的速度非常快,几乎可以忽略不计,所以上面的两个Loop的执行时间大体相同。
第二个程序
-
for (int i = 0; i < arr.Length; i += K) arr[i] *= 3;
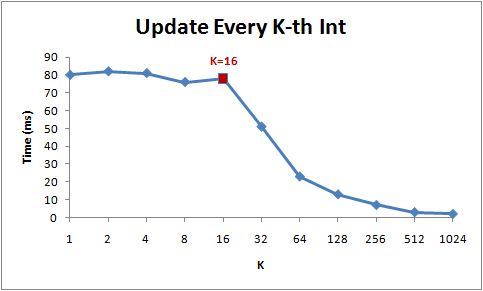
前面一段访问时间都是大体相同,因为都在一个cacheline里面,而后由于k的增大,循环次数明显变少,所以时间会越来越小。
程序三
-
int steps = 64 * 1024 * 1024; // Arbitrary number of steps
-
int lengthMod = arr.Length - 1;
-
for (int i = 0; i < steps; i++)
-
{
-
arr[(i * 16) & lengthMod]++; // (x & lengthMod) is equal to (x % arr.Length) }
这里面,L1 cache的大小为32KB,L2的大小为4M,所以可以看到当数组的大小逐渐增加时,每个元素的平均访问时间会越来越大,因为L1Cache不住就会访问L2Cache,以此类推。
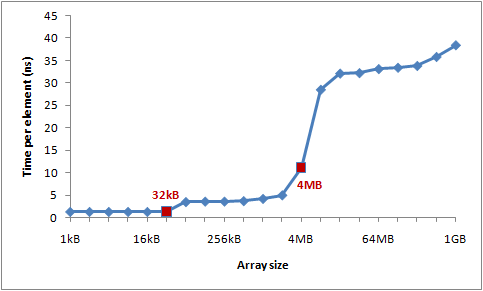
程序四:
private static int[] s_counter = new int[1024]; private void UpdateCounter(int position)
{ for (int j = 0; j < 100000000; j++)
{
s_counter[position] = s_counter[position] + 3;
}
}
程序四是为测试Cache的一致性而设计的,当CacheLine里面的某一个元素被修改了,那么对应内存地址的整行cache-line就会失效。
对于多核而言,其他的core里面的数据也会失效。这样会降低cache的失效率。作者测试参数为0,1,2,3为参数的时候,运行四个不同的线程进行测试,发现花费了4.3s。如果参数为16,32,48,测试的结果为0.28s。
因为后面的测试,这些数据都不是在同一个cache line里面的,所以不会造成cache miss而导致的多个核心之间会相互影响。
阅读(6559) | 评论(3) | 转发(2) |
