我是zoro
分类: SQLite/嵌入式数据库
2011-02-15 09:42:29
写在前面:个人认为pager层是SQLite实现最为核心的模块,它具有四大功能:I/O,页面缓存,并发控制和日志恢复。而这些功能不仅是上层Btree的基础,而且对系统的性能和健壮性有关至关重要的影响。其中并发控制和日志恢复是事务处理实现的基础。SQLite并发控制的机制非常简单——封锁机制;别外,它的查询优化机制也非常简单——基于索引。这一切使得整个SQLite的实现变得简单,SQLite变得很小,运行速度也非常快,所以,特别适合嵌入式设备。好了,接下来讨论事务的剩余部分。
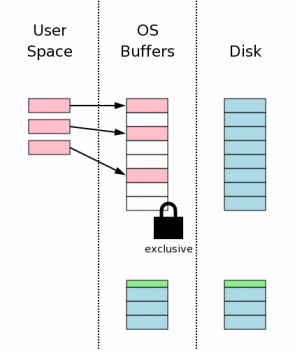
6、修改位于用户进程空间的页面(Changing Database Pages In User Space)
页面的原始数据写入日志之后,就可以修改页面了——位于用户进程空间。每个数据库连接都有自己私有的空间,所以页面的变化只对该连接可见,而对其它连接的数据仍然是磁盘缓存中的数据。从这里可以明白一件事:一个进程在修改页面数据的同时,其它进程可以继续进行读操作。图中的红色表示修改的页面。
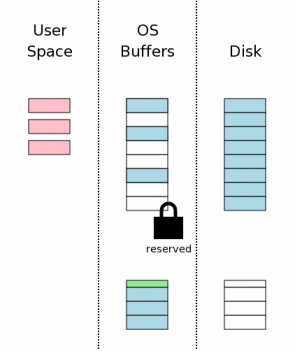
7、日志文件刷入磁盘(Flushing The Rollback Journal File To Mass Storage)
接下来把日志文件的内容刷入磁盘,这对于数据库从意外中恢复来说是至关重要的一步。而且这通常也是一个耗时的操作,因为磁盘I/O速度很慢。
这个步骤不只把日志文件刷入磁盘那么简单,它的实现实际上分成两步:首先把日志文件的内容刷入磁盘(即页面数据);然后把日志文件中页面的数目写入日志文件头,再把header刷入磁盘(这一过程在代码中清晰可见)。
代码如下:
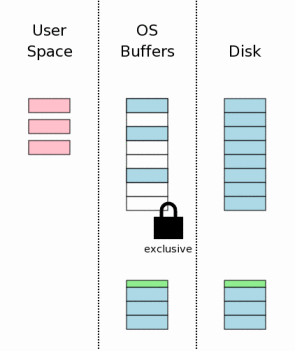
8、获取排斥锁(Obtaining An Exclusive Lock)
在对数据库文件进行修改之前(注:这里不是内存中的页面),我们必须得到数据库文件的排斥锁(Exclusive Lock)。得到排斥锁的过程可分为两步:首先得到Pending lock;然后Pending lock升级到exclusive lock。
Pending lock允许其它已经存在的Shared lock继续读数据库文件,但是不允许产生新的shared lock,这样做目的是为了防止写操作发生饿死情况。一旦所有的shared lock完成操作,则pending lock升级到exclusive lock。
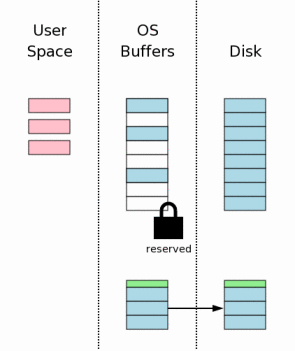
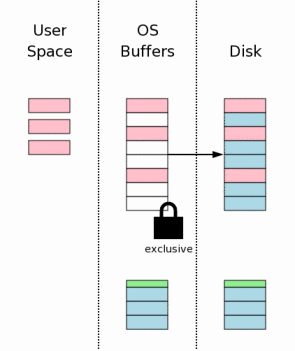
9、修改的页面写入文件(Writing Changes To The Database File)
一旦得到exclusive lock,其它的进程就不能进行读操作,此时就可以把修改的页面写回数据库文件,但是通常OS都把结果暂时保存到磁盘缓存中,直到某个时刻才会真正把结果写入磁盘。
以上两步的实现代码:
10、修改结果刷入存储设备(Flushing Changes To Mass Storage)
为了保证修改结果真正写入磁盘,这一步必不要少。对于数据库存的完整性,这一步也是关键的一步。由于要进行实际的I/O操作,所以和第7步一样,将花费较多的时间。
最后来看看这几步是如何实现的:
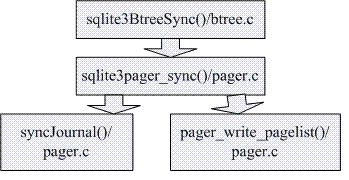
其实以上以上几步是在函数sqlite3BtreeSync()---btree.c中调用的(而关于该函数的调用后面再讲)。
代码如下:
下图可以进一步解释该过程:
转自:
