分类:
2012-06-05 14:17:11
下面将一步一步演示如何部署一个5节点的集群,并测试一下MapReduce分布式处理的强大功能。
1、应用场景
接下来我们将实际部署一个5节点的集群,并采用MapReduce计算出2个namelist文件中各个名字出现的次数,程序架构设计如下所示。
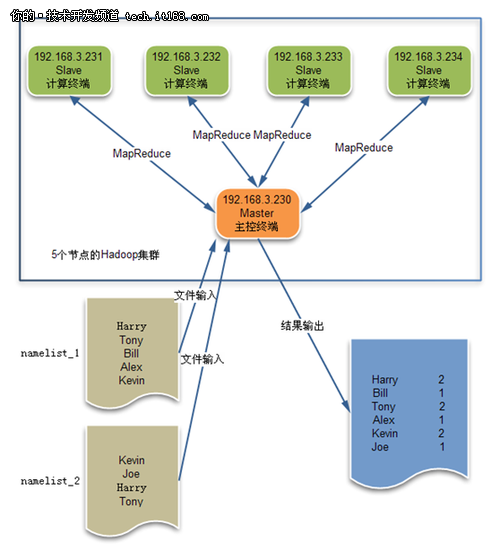
其中NameNode主节点和DataNode从节点的分布情况如下:
|
NameNode主节点 |
DataNode从节点 |
|
192.168.3.230 |
192.168.3.231 192.168.3.232 192.168.3.233 192.168.3.234 |
2、准备集群环境
1)配置ssh无密码登录机器
在 Hadoop 分布式环境中,NameNode主节点需要通过 SSH 来启动和停止DataNode从节点上的各类进程。我们需要保证环境中的各台机器均可以通过SSH 登录访问,并且 Name Node 用 SSH 登录 Data Node 时,不需要输入密码,这样 Name Node 才能在后台自如地控制其它结点。可以将各台机器上的 SSH 配置为使用无密码公钥认证方式来实现。
现在流行的各类 Linux 发行版一般都安装了 SSH 协议的开源实现 OpenSSH, 并且已经启动了 SSH 服务, 即这些机器缺省应该就是支持 SSH 登录的。如果你的机器缺省不支持 SSH, 请下载安装 OpenSSH,以下是配置 SSH 的无密码公钥认证的过程。
首先,在NameNode主节点机器上执行命令,具体如下面的代码所示:
|
[root@localhost hadoop-0.20.203.0]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa Generating public/private dsa key pair. Your identification has been saved in /root/.ssh/id_dsa. Your public key has been saved in /root/.ssh/id_dsa.pub. The key fingerprint is: 09:1b:94:6a:98:35:3c:0b:d6:3f:b1:a5:30:4b:ce:14 root@localhost.localdomain [root@localhost hadoop-0.20.203.0]# |
然后,在NameNode主节点机器上将生成的公钥文件放到/tmp目录下,具体操作如下所示:
|
[root@localhost hadoop-0.20.203.0]# cp ~/.ssh/id_dsa.pub /tmp [root@localhost hadoop-0.20.203.0]# |
其次,将这个NameNode主节点的公钥文件放到4台DataNode从节点机器的/tmp目录下。
最后,我们在NameNode主节点和DataNode从节点机器上同时执行下面的命令:
|
[root@localhost tmp]# cat /tmp/id_dsa.pub >> ~/.ssh/authorized_keys [root@localhost tmp]# |
以上都做完了以后,我们就可以用SSH无密码的方式来登录这5台的机器了,可以用如下的方法进行一下简单测试:
|
[root@localhost tmp]# ssh 192.168.3.230 [root@localhost tmp]# ssh 192.168.3.231 [root@localhost tmp]# ssh 192.168.3.232 [root@localhost tmp]# ssh 192.168.3.233 [root@localhost tmp]# ssh 192.168.3.234 |
2)安装必须的软件
Hadoop的NameNode主节点,是通过Java程序来跟各DataNode从节点进行通信,并控制它们的,所以我们除了要安装Hadoop的二进制版本之外,我们还需要安装一个JDK来确保Hadoop运行环境的稳定。
首先,我们需要下载Hadoop和Java的安装程序。推荐大家去官网下载,具体怎么样下载不是本文的重点,请大家自行解决。
其次,下载之后我们在NameNode主节点上解压并安装JDK和Hadoop软件,具体操作如下代码所示:
|
[root@localhost opt]# ll total 152068 -rw-r--r-- 1 root root 60569605 Aug 15 10:13 hadoop-0.20.203.0rc1.tar.gz -rw-r--r-- 1 root root 94971634 Aug 15 10:28 jdk-7-linux-x64.tar.gz [root@localhost opt]# |
|
[root@localhost opt]# tar zxf jdk-7-linux-x64.tar.gz [root@localhost opt]# tar zxf hadoop-0.20.203.0rc1.tar.gz [root@localhost opt]# ll total 152084 drwxr-xr-x 12 root root 4096 May 4 14:30 hadoop-0.20.203.0 -rw-r--r-- 1 root root 60569605 Aug 15 10:13 hadoop-0.20.203.0rc1.tar.gz drwxr-xr-x 10 500 500 4096 Jun 27 16:51 jdk1.7.0 -rw-r--r-- 1 root root 94971634 Aug 15 10:28 jdk-7-linux-x64.tar.gz [root@localhost opt]# |
之后, 我们在NameNode主节点和DataNode从节点上将java加入到PATH中,只需要在/etc/profile中添加export PATH=/opt/jdk1.7.0/bin:$PATH即可,/opt/jdk1.7.0/bin是Java程序集的路径。
最后,在NameNode主节点和DataNode从节点的机器上,执行”su –“ 刷新一下用户的环境变量,具体如下:
|
[root@test1 ~]# su - [root@test1 ~]# |
以上工作都完后,说明我们的准备工作都已经完成了,接下来我们将进行到实际的配置集群的阶段了。
3、配置集群
我们用变量$HADOOP_HOME代表Hadoop的主目录,它的值为: $HADOOP_HOME=/opt/hadoop-0.20.203.0。
1)将Java添加到Hadoop运行环境
首先,在NameNode主节点,编辑$HADOOP_HOM /conf/hadoop-env.sh文件,将Java加入到Hadoop的运行环境中,具体如下:
|
# The java implementation to use. Required. # export JAVA_HOME=/usr/lib/j2sdk1.5-sun export JAVA_HOME=/opt/jdk1.7.0 |
2)配置NameNode主节点信息
其次,在NameNode主节点上,编辑$HADOOP_HOM /conf/core-site.xml文件,添加NameNode主节点的IP和监听端口的相关信息。
|
[root@localhost hadoop-0.20.203.0]# cat conf/core-site.xml
[root@localhost hadoop-0.20.203.0]# |
3)配置数据冗余数量
再次,在NameNode主节点上,编辑$HADOOP_HOM /conf/hdfs-site.xml文件,配置数据冗余的数据的备份数量。
|
[root@localhost hadoop-0.20.203.0]# cat conf/hdfs-site.xml
[root@localhost hadoop-0.20.203.0]# |
4)配置jobtracker信息
然后,在NameNode主节点上,编辑$HADOOP_HOM /conf/mapred-site.xml文件,配置NameNode主节点上的jobtracker服务的端口。
|
[root@localhost hadoop-0.20.203.0]# cat conf/mapred-site.xml
[root@localhost hadoop-0.20.203.0]# |
5)配置master信息
接下来,在NameNode主节点上,编辑$HADOOP_HOM /conf/masters文件,配置主节点的IP信息。
|
[root@localhost hadoop-0.20.203.0]# cat conf/masters 192.168.3.230 [root@localhost hadoop-0.20.203.0]# |
6)配置slave信息
最后,在NameNode主节点上,编辑$HADOOP_HOM /conf/slave文件,配置从节点的IP信息,这个从节点可以有一个,也可以有多个,对于本例有4个slave。
|
[root@localhost hadoop-0.20.203.0]# cat conf/slaves 192.168.3.231 192.168.3.232 192.168.3.233 192.168.3.234 [root@localhost hadoop-0.20.203.0]# |
7)分发Hadoop配置信息
以上操作都做完以后,我们在NameNode主节点上,将JDK和Hadoop软件分发到各DataNode从节点上,并保持安装路径与NameNode主节点相同,就像下面代码演示的一样:
|
scp -r jdk1.7.0 hadoop-0.20.203.0 192.168.3.231:/opt/ scp -r jdk1.7.0 hadoop-0.20.203.0 192.168.3.232:/opt/ scp -r jdk1.7.0 hadoop-0.20.203.0 192.168.3.233:/opt/ scp -r jdk1.7.0 hadoop-0.20.203.0 192.168.3.234:/opt/ |
8)格式化分布式文件系统
跟Windows和Linux一样,要想使用HDFS也需要事先格式化,否则文件系统是不可用的,具体方法见下面的代码:
|
[root@localhost hadoop-0.20.203.0]# bin/hadoop namenode -format 11/08/16 02:38:40 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost.localdomain/127.0.0.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 0.20.203.0 …… 11/08/16 02:38:40 INFO util.GSet: VM type = 64-bit 11/08/16 02:38:40 INFO namenode.NameNode: Caching file names occuring more than 10 times 11/08/16 02:38:41 INFO common.Storage: Image file of size 110 saved in 0 seconds. 11/08/16 02:38:41 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted. 11/08/16 02:38:41 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost.localdomain/127.0.0.1 ************************************************************/ [root@localhost hadoop-0.20.203.0]# |
9)启动Hadoop集群
只需要在NameNode主节点上执行下面的start-all.sh命令即可,同时Master节点可以通过ssh登录到各slave节点去启动其它相关进程。
|
[root@localhost hadoop-0.20.203.0]# bin/start-all.sh starting namenode, logging to /opt/hadoop-0.20.203.0/bin/../logs/hadoop-root-namenode-localhost.localdomain.out 192.168.3.232: starting datanode, logging to /opt/hadoop-0.20.203.0/bin/../logs/hadoop-root-datanode-localhost.localdomain.out 192.168.3.233: starting datanode, logging to …… /opt/hadoop-0.20.203.0/bin/../logs/hadoop-root-jobtracker-localhost.localdomain.out 192.168.3.233: starting tasktracker, logging to …… [root@localhost hadoop-0.20.203.0]# |
10)查看Master和slave进程状态
在NameNode主节点上,查看Java进程情况:
|
[root@localhost hadoop-0.20.203.0]# jps 867 SecondaryNameNode 735 NameNode 1054 Jps 946 JobTracker [root@localhost hadoop-0.20.203.0]# |
在4台DataNode从节点上,查看Java进程情况:
|
[root@localhost opt]# jps 30012 TaskTracker 29923 DataNode 30068 Jps [root@localhost opt]# |
各节点上进程都在的话,说明集群部署成功。
4、常见异常的处理
这部分将讲解Hadoop集群配置中最容易犯的错误及解决方案,希望可以让大家尽快的解决问题。
1) Unrecognized option: -jvm
异常现象:
|
[root@localhost hadoop-0.20.203.0]# bin/start-all.sh ……. 192.168.3.232: Unrecognized option: -jvm 192.168.3.232: Error: Could not create the Java Virtual Machine. 192.168.3.232: Error: A fatal exception has occurred. Program will exit. ……. |
解决方案:
需要修改$HADOOP_HOM /bin/hadoop,注释掉这2行:
|
if [[ $EUID -eq 0 ]]; then # HADOOP_OPTS="$HADOOP_OPTS -jvm server $HADOOP_DATANODE_OPTS" # else HADOOP_OPTS="$HADOOP_OPTS -server $HADOOP_DATANODE_OPTS" fi |
2) Shuffle Error: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out.
异常现象:
|
11/08/16 03:37:41 INFO mapred.JobClient: map 100% reduce 0% 11/08/16 03:37:58 INFO mapred.JobClient: Task Id : attempt_201108160249_0001_r_000000_0, Status : FAILED Shuffle Error: Exceeded MAX_FAILED_UNIQUE_FETCHES; bailing-out. 11/08/16 03:37:58 WARN mapred.JobClient: Error reading task outputConnection refused 11/08/16 03:37:58 WARN mapred.JobClient: Error reading task outputConnection refused 11/08/16 03:38:08 INFO mapred.JobClient: map 100% reduce 16% |
解决方案:
需要修改2个文件:
|
vi /etc/security/limits.conf 加上: * soft nofile 102400 * hard nofile 409600
vi /etc/pam.d/login 加上: session required /lib/security/pam_limits.so |
