转自:
Linux内核中有很多种链表,如果对每一种链表都使用单独的数据结构去表示,那么需要对每个链表实现一组原语操作,包括初始化、插入、删除
等。于是,Linux内核定义了一个很有趣的数据结构:
struct list_head {
struct list_head *next, *prev;
};
乍一看这定义,似乎很普通,但妙就妙在普通上。
通常我们的做法总是将数据嵌入到链表的节点中,类似下面的定义方法:
struct list_node {
data_type data;
list_node *next, *prev;
}
示意图如下:

但是,这里正好相反,将链表节点嵌入到数据结构中:
struct data_type {
data;
list_head;
}
示意图如下(其中增加了一个哑元):
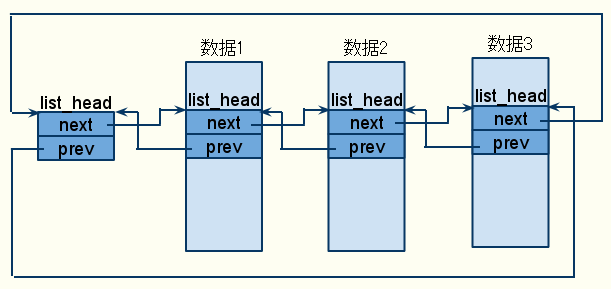
在这种链表中,所有的链表基本操作都是针对list_head数据结构进行,而不是针对包含list_head的数据结构,所以无论什么数据,链表操作
都得到了统一。那么,现在碰到一个问题,因为所有链表操作涉及到的指针都是指向list_head数据结构的,而不是包含的数据结构,那么怎样从
list_head的地址得到包含其的数据结构的地址呢?我们来看linux内核中的(p,t,m)这个宏:
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
跟踪到宏:
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type,member) );})
这里面offsetof不需要跟踪,我们也能理解这个宏的意思了。先简单对宏的三个参数说明一下。ptr是指向list_head数据结构的指
针,type是容器数据结构的类型,member是list_head在type中的名字。直接看下面的示例代码:
struct data{
xxx;
list_head list1;
list_head list2;
xxx;
};
struct data vardat = {初始化};
list_head *p = &vardat.list1;
list_head *q = &vardat.list2;
list_entry(p, struct data, list1) == &vardat;
list_entry(q, struct data, list2) == &vardat;
从上面这个例子可以看出,vardat可以同时挂到两个(或更多)链表上,其中list1是第一个链表上的一个节点,list2是第二个链表上的节点,
从&list1和&list2都可以得到vardat,上面提出的问题也就解决了。
前面跳过了这个宏,相信有不少读者对这个宏也会感兴趣,那么我们现在来看看这个宏是怎么
实现的。跟踪这个宏会发现有两种定义,一种是__compiler_offsetof(a,b),继续跟踪得到
__builtin_offsetof(a,b),这就不看了;我们看另一种定义:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
看过之后恍然大悟,原来这么简单,把一个TYPE类型的指向0的指针,其MEMBER自然就是offset,妙哉!
小结一下这种链表的优点:(1)所有链表基本操作都是基于list_head指针的,因此添加类型时,不需要重复写链表基本操
作函数(2)一个container数据结构可以含有多个list_head成员,这样就可以同时挂到多个不同的链表中,例如
linux内核中会将进程数据结构()同时挂到任务链表、优先级链表等多个链表上,下面会有更多说明。
来看看linux内核中提供的链表基本操作(不做说明的数据类型都是list_head *):
list_add(new, head); //将new插入到head元素后面
list_add_tail(new, head); //额,跟上面的区别就不用解释了,不过这里的head是真正的链表头
list_del(entry); //删除entry节点
list_empty(head); //检查是否为空链表
list_entry(ptr, type, member); //前面解释过了
list_for_each(pos, head); //遍历列表,每次循环是通过pos返回节点list_head指针
//下面这个最有用!
list_for_each_entry(pos, head, member); //同上,但通过pos返回的是container数据结构的地址。
慢!发现一个问题了,list_entry中需要type,为啥list_for_each_entry不需要呢?简单,pos是你给的一个
container数据结构的指针,在宏的实现中,用typeof(*pos)就得到type了!
我们来看看linux中的task_struct这个数据结构,它存放的是进程信息,只看跟链表有关的内容:
struct task_struct {
//xxxxxxx
struct hlist_head preempt_notifiers;
struct list_head rcu_node_entry;
struct list_head tasks;
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct list_head ptraced;
struct list_head ptrace_entry;
struct list_head thread_group;
//还有好多list,不抄了……
}
其中tasks是所有进程组成的链表,因此要遍历所有进程,可以用这个宏:
#define for_each_process(p) \
for (p = &init_task ; (p = next_task(p)) != &init_task ; )
#define next_task(p) \
list_entry((p)->tasks.next, struct task_struct, tasks)
这样的代码是不是很酷呢?!
阅读(1876) | 评论(0) | 转发(1) |
