无聊之人--除了技术,还是技术,你懂得
分类: DB2/Informix
2015-04-26 21:38:39
Whenever an Insert, Update or Delete statement is successfully executed, DB2 writes two types of log records, Undo Record and Redo Record.
For the sake of simplicity log records such as Begin UR, End UR, Two Phase Commit etc. have been omitted from discussion.
Undo records are used by DB2 to rollback any changes if the application wishes to rollback or if there is an abnormal termination of the thread.
The redo records are used for forward recovery.
COMMIT :
For example, Let us assume that a SQL updates 100 rows of a table that belong to 10 pages in the table space. To perform these updates DB2 has to read these 10 pages from the disk to the buffer pool and the data changes are made in the buffer pool. Even if a COMMIT is issued after the update there is no guarantee that the updated data buffers will be written to disk. The only thing DB2 does at commit is to write the Undo and Redo Records from the log buffer to the active log data set which resides on disk.
In case DB2 terminates abnormally after the COMMIT was issued but before the data buffers were written to the table space, we end up with a situation where we think the data is committed but in reality this data has not been externalized to DASD.
To resolve this problem, when DB2 is brought up the next time DB2 reads the Redo records from the Active Log Data Set and even the archive log data sets and uses the Redo Records to essentially re-do all the work it did but crashed before it could move it to disk. Redo Records are also used while Recovering a table spaces.
Let us look at how the Log buffers (OUTBUFF) are written to and how the log buffers are written. The Active Log Data Set is a VSAM dataset, therefore the basic unit of I/O to it is in (blocks) Control Intervals (CI) . The point that is stressed here is that DB2 does not write to the Active Log Data Set Log record by Log record. Instead DB2 writes CI at a time .
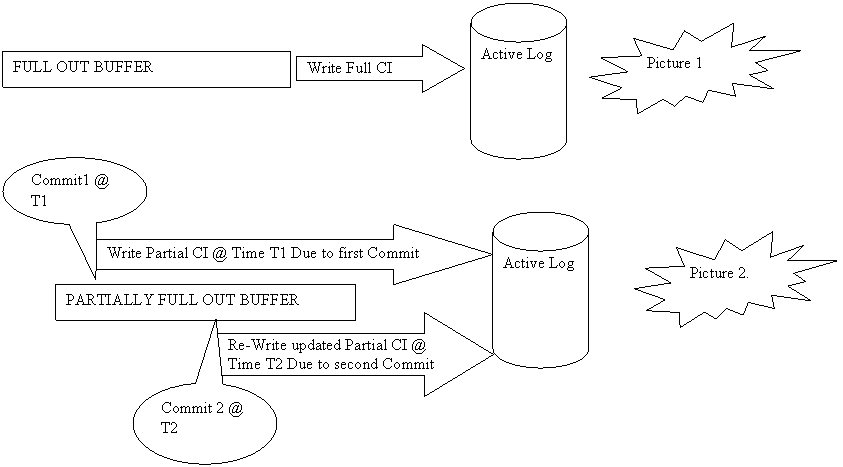
Let us first consider a simple situation. When SQL statements that modify data are being executed, log records will be written to the OUTBUFF. When the OUTBUFF becomes full, DB2 will write it to one CI in the Active Log Data Set. Follow Picture 1.
Next, let us assume that the OUTBUFF is not full and when it 10 % full, at time T1, PROGA ( some arbitrary program) issues a COMMIT. Even though the OUTBUFF is not full, DB2 will write the available log records as one CI to the Active Log Data Set. Obviously only 10% of the CI 's space will be used.
Assume at time T2 when the OUTBUFF is 50% full an other commit is issued by either the same program PROGA or an other program PROGX, and there are many other log records that have been accumulated in the OUTBUFF that might belong to other units of work other than the one issuing the commit. At this point an other write will be done to the Active Log Data Set. However the CI being written at T2 will not be a new CI but the updated version of the CI that was written at T1. The CI written at T2 will have the log records that were written at T1 plus the new log records that have been accumulated till T2 .
The point that is stressed here is that every time a commit is issued a CI is written to the Active Log Data Set but it is not necessarily a new CI. FollowPicture 2.
There is no guarantee of any other data being externalized at COMMIT other than the log buffers.
CHECK POINT:
Checkpoint on the other hand is a system wide event. A check point can be triggered by a Coordinator like IMS/DC or CICS or by DB2's LOGLOAD or by stopping DB2 etc..
When a checkpoint is issued the OUTBUFF is written to the Active Log Data Set as a full and non updatable CI. The data buffers are requested to prepare for writing the updated pages to the ( table spaces or indexes ) DASD. After the checkpoint is taken the Boot Strap Data Sets are updated with the Checkpoint Start and End RBAs.
Checkpoint does not ensure that the data buffers are externalized.The only constraint is that the data buffers have to write the updated pages before the next two check points. ( Note: for example, If you want to ensure that all your log information is externalized and all your data buffers are externalized before you take a flash copy , issue three consecutive check points and then take the flash copy ).
Apart from this a check point will also check for any datasets that might need to be pseudo closed based on PCLOSEN parameter.
In conclusion , a commit is a SQL event and a checkpoint is a system wide event. Even though both write the OUTBUFF to the Active Log Data Set the way in which they write is different.