最近重新找了一下C语言的资料,深深的被c语言的底层操作特性迷恋~。在这方面,最经典的一本书莫过于清华大学出版社的《C高级实用程序设计》(王士元),在C语言高级应用领域里这是我见过的写的最好的一本书,非常可惜的这本书现在已经绝版了(可能是因为技术发展和更新的太快),在书店里网上都无法买到了。记得本科时期经常借同学的这本书来读,爱不释手,里面的知识极具魅力,即使今天看起来仍让我觉得不是过时,而是回味无穷。这里提到的字库文件和操作系统都已经属于古董级别了,现在可能也很难找到了。。。。这种应用在现在时代也很少有人研究了,但我想在单片机等嵌入式系统的点阵式汉字显示屏中仍然在使用。
在这里我参考了一些资料中的用C语言显示汉字字库的资料。在计算机发展的早期,为了支持显示汉字,国内发明了相应的2个字节表示的汉字国标(GB)码,根据这个编码规则,汉字分为94个区,每区94个汉字,汉字在其所在区内的位置用位号表示,两个字节分别表示区号和位号,为了区分ASCII码,每个字节的首位都被置为1。在网络传输时还有特定的区分方法,这里不细述这些细节了。在国际编码中,中国汉字被分配到第16区(起始区号0x0F)。为了显示汉字,需要汉字字形文件(字库)的支持。在DOS时代,出现了USDOS系统,有HZK16(16*16字形),HZK24(24*24字形)等字库文件,本质上一个汉字字符是一个二值图像(即bpp=1),所以本质上是一种图形字体(非矢量的),例如HZK16,每个字是16*16像素,每个像素占1位(1/8byte),因此每个汉字在文件中占据了16*16/8=32 bytes/汉字。HZK24每个汉字占据24*24/8=72 bytes/汉字。由于采用了这些约定,所以文件中没有任何文件头等附加描述信息,而全部是紧密排列的像素字形点阵,文件从第一个字节开始第一个字符一直到最后一个字符结束,文件也没有后缀名。字形在文件中是紧密排列的,但是需要注意的2点重要问题是:
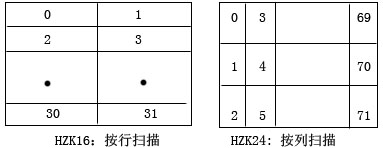
(1)字形扫描顺序:
HZK16是按行扫描,而HZK24是按列扫描。
所以假设一个字形读取到一个byte[]。则字节的分布分为按行扫描和按列扫描。例如在HZK16中是按行一行一行扫描,即前byte[0],byte[1]是第一行,接着2个byte是第二行。。。而HZK24为了使使用它的打印机输出,采用的是按列扫描,因为打印机有一个纵向的24针,每一次可以逐列的打印一行汉字,因此为了配合打印机,HZK24采用了按列扫描。如下图所示:(图中的数字表示的该字节在byte[]中的索引。)
下面这张图显示的是24*24像素的按列扫描的汉字字符,是如何用一个BYTE[]数组来描述的:图中用彩色填充的方式标示出了BYTE[0],BYTE[1],BYTE[2]:

(2)字形在字库文件中的定位:
请注意的是,在HZK16和HZK24中定位是不同的。这是由于汉字在文件中的起始区不同。HZK16的汉字起始区在第16个分区,而HZK24则直接从第一个分区开始。HZK16的前15个分区里面存储了一些特殊符号,字母等(见后面的截图)。因此汉字所在的分区是从15号分区开始的,而HZK24不包含前面的特殊字符,第一个区就是汉字区“啊”,从0号分区开始。另一点需要注意的是,两者的【bytes/汉字】数值不同。用offset表示从文件头开始计算的文件偏移地址,code[2]表示汉子码。
则code是用内码表示的,如汉字表中的第一个汉字“啊”的内码是{0xb0,0xa1};从汉字码的第一个字节获取区号,从第二个字节获取位号。将他们减去0xA1就转换为我们需要的区号和位号。即换算成区号是{0x0f,0x00},表示“啊”字位于第15区,位号是0。
对于HZK16来说:94是每个区的汉字数。
unsigned long offset=(
(code[0]-0xA1) *94 + (code[1]-0xA1) )*32L;
//32是每个汉字占据的字节数 对于HZK24来说:
unsigned long offset=(
(code[0]-0xA1-15) *94 + (code[1]-0xA1) )*72L;
//72是每个汉字占据的字节数
注意上面的HZK24中,由于第一个分区就是汉字区,所以区号被减去了0x0F。
这样,我们看显示一个字符的代码:(以下代码来自于《C高级应用程序设计》一书。)

 HZK16显示汉字的代码
HZK16显示汉字的代码
/*在屏幕的x0,y0位置显示一个汉字字符*/
void dishz(int x0,int y0,char code[],int color)
{
unsigned char mask[]={0x80,0x40,0x20,0x10,0x08,0x04,0x02,0x01};
/*屏蔽字模每行各位的数组*/
int i,j,x,y,pos;
char mat[32];
/*下面这个函数用于在文件中读取相应的字节到mat数组中*/
get_hz(code,mat);
y=y0;
for (i=0;i<16;++i)
{
x=x0;
pos=2*i;
for(j=0;j<16;++j)
{
/*屏蔽出汉字字模的一个位,即一个点是1 则显示,否则不显示该点*/
if ((mask[j%8]&mat[pos+j/8])!=NULL)
putpixel(x,y,color);
++x;
}
++y;
}
} 我们要注意的是,由于每个汉字占用了2个字节,因此我们必须每次是字符串的指针递增2。例如:
char* s="这是汉字字符串";
while(*s)
{
dishz(x0,y0,s,LIGHTBLUE);
x0+=16;
s+=2; //notice: not s++
}
上面的字模数组的每个数字的某一位为1,这样用位与操作可以判断某个byte中的某一位为1还是0,如果为1表示这里应该显示汉字的前景颜色。上面的代码是用于HZK16的,即按行扫描的顺序显示的。按列显示的代码原理类似,不再列出。
关于加载字模,主要采用上面的文件定位,读取一定数量字节即可,这里我们也不再列出。
下面的截图是HZK16字库的前面一部分特殊字符(有象棋棋子,制表符,全角的字母数字等等):(每行32个字符,每个字符的左上角被我标记了一个红点)。

上面的截图采用了在《用c语言显示BMP》一文中的TC截屏代码截屏的代码(我将截屏代码写到cpyscr.h文件中放到了include文件夹下,这样只要用#include "cpyscr.h"就可以直接使用截屏函数了),注意第一行中的数字序号表示的是该字符的序号(注意该序号不是ASCII码!!!),而不是文件地址!。
下图是用HZK24F(仿宋体)显示的汉字,上面是原样大小输出(24*24),较大的字是把字形边长扩大成2倍边长(48*48)的输出,由于是位图字体,所以扩大后会有位图放大的锯齿感:

宋体汉字库:

