分类:
2012-01-10 17:21:54
原文地址:linux cache 机制 作者:kkmm0105
原文地址:http://www.cnblogs.com/liloke/archive/2011/11/20/2255737.html
Linux Cache 机制
在阅读文章前,您应该具备基本的存储器层次结构知识,至少要了解局部性原理。要详细了解cache基本原理,可以参考本书《深入理解计算机系统》中存储器体系结构一章:
带着疑问来看文章,cache对于程序员是不可见的,它完全是由硬件控制的,为什么在linux内核中还有cache.h这个头文件,定义了一些关于cache的结构?
1. cache概述
cache,中译名高速缓冲存储器,其作用是为了更好的利用局部性原理,减少CPU访问主存的次数。简单地说,CPU正在访问的指令和数据,其可能会被以后多次访问到,或者是该指令和数据附近的内存区域,也可能会被多次访问。因此,第一次访问这一块区域时,将其复制到cache中,以后访问该区域的指令或者数据时,就不用再从主存中取出。
2. cache结构
假设内存容量为M,内存地址为m位:那么寻址范围为000…00~FFF…F(m位)
倘若把内存地址分为以下三个区间:
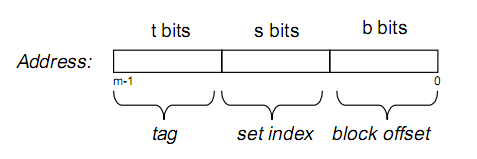
tag, set index, block offset三个区间有什么用呢?再来看看Cache的逻辑结构吧:
将此图与上图做对比,可以得出各参数如下:
B = 2^b
S = 2^s
现在来解释一下各个参数的意义:
一个cache被分为S个组,每个组有E个cacheline,而一个cacheline中,有B个存储单元,现代处理器中,这个存储单元一般是以字节(通常8个位)为单位的,也是最小的寻址单元。因此,在一个内存地址中,中间的s位决定了该单元被映射到哪一组,而最低的b位决定了该单元在cacheline中的偏移量。valid通常是一位,代表该cacheline是否是有效的(当该cacheline不存在内存映射时,当然是无效的)。tag就是内存地址的高t位,因为可能会有多个内存地址映射到同一个cacheline中,所以该位是用来校验该cacheline是否是CPU要访问的内存单元。
当tag和valid校验成功是,我们称为cache命中,这时只要将cache中的单元取出,放入CPU寄存器中即可。
当tag或valid校验失败的时候,就说明要访问的内存单元(也可能是连续的一些单元,如int占4个字节,double占8个字节)并不在cache中,这时就需要去内存中取了,这就是cache不命中的情况(cache miss)。当不命中的情况发生时,系统就会从内存中取得该单元,将其装入cache中,与此同时也放入CPU寄存器中,等待下一步处理。注意,以下这一点对理解linux cache机制非常重要:
当从内存中取单元到cache中时,会一次取一个cacheline大小的内存区域到cache中,然后存进相应的cacheline中。
例如:我们要取地址 (t, s, b) 内存单元,发生了cache miss,那么系统会取 (t, s, 00…000) 到 (t, s, FF…FFF)的内存单元,将其放入相应的cacheline中。
下面看看cache的映射机制:
当E=1时, 每组只有一个cacheline。那么相隔2^(s+b)个单元的2个内存单元,会被映射到同一个cacheline中。(好好想想为什么?)
当1
当E=C/B,此时S=1,每个内存单元都能映射到任意的cacheline。带有这样cache的处理器几乎没有,因为这种映射机制需要昂贵复杂的硬件来支持。
不管哪种映射,只要发生了cache miss,那么必定会有一个cacheline大小的内存区域,被取到cache中相应的cacheline。
现代处理器,一般将cache分为2~3级,L1, L2, L3。L1一般为CPU专有,不在多个CPU中共享。L2 cache一般是多个CPU共享的,也可能装在主板上。L1 cache还可能分为instruction cache, data cache. 这样CPU能同时取指令和数据。
下面来看看现实中cache的参数,以Intel Pentium处理器为例:
| E | B | S | C | |
| L1 i-cache | 4 | 32B | 128 | 16KB |
| L1 d-cache | 4 | 32B | 128 | 16KB |
| L2 | 4 | 32B | 1024~16384 | 128KB~2MB |
3. cache miss的代价
cache可能被分为L1, L2, L3, 越往外,访问时间也就越长,但同时也就越便宜。
L1 cache命中时,访问时间为1~2个CPU周期。
L1 cache不命中,L2 cache命中,访问时间为5~10个CPU周期
当要去内存中取单元时,访问时间可能就到25~100个CPU周期了。
所以,我们总是希望cache的命中率尽可能的高。
4. False Sharing(伪共享)问题
到现在为止,我们似乎还没有提到cache如何和内存保持一致的问题。
其实在cacheline中,还有其他的标志位,其中一个用于标记cacheline是否被写过。我们称为modified位。当modified=1时,表明cacheline被CPU写过。这说明,该cacheline中的内容可能已经被CPU修改过了,这样就与内存中相应的那些存储单元不一致了。因此,如果cacheline被写过,那么我们就应该将该cacheline中的内容写回到内存中,以保持数据的一致性。
现在问题来了,我们什么时候写回到内存中呢?当然不会是每当modified位被置1就写,这样会极大降低cache的性能,因为每次都要进行内存读写操作。事实上,大多数系统都会在这样的情况下将cacheline中的内容写回到内存:
当该cacheline被置换出去时,且modified位为1。
现在大多数系统正从单处理器环境慢慢过渡到多处理器环境。一个机器中集成2个,4个,甚至是16个CPU。那么新的问题来了。
以Intel处理器为典型代表,L1级cache是CPU专有的。
先看以下例子:
系统是双核的,即为有2个CPU,CPU(例如Intel Pentium处理器)L1 cache是专有的,对于其他CPU不可见,每个cacheline有8个储存单元。
我们的程序中,有一个 char arr[8] 的数组,这个数组当然会被映射到CPU L1 cache中相同的cacheline,因为映射机制是硬件实现的,相同的内存都会被映射到同一个cacheline。
2个线程分别对这个数组进行写操作。当0号线程和1号线程分别运行于0号CPU和1号CPU时,假设运行序列如下:
开始CPU 0对arr[0]写;
随后CPU 1对arr[1]写;
随后CPU 0对arr[2]写;
……
CPU 1对arr[7]写;
根据多处理器中cache一致性的协议:
当CPU 0对arr[0]写时,8个char单元的数组被加载到CPU 0的某一个cacheline中,该cacheline的modified位已经被置1了;
当CPU 1对arr[1]写时,该数组应该也被加载到CPU 1的某个cacheline中,但是该数组在cpu0的cache中已经被改变,所以cpu0首先将cacheline中的内容写回到内存,然后再从内存中加载该数组到CPU 1中的cacheline中。CPU 1的写操作会让CPU 0对应的cacheline变为invalid状态注意,由于相同的映射机制,cpu1 中的 cacheline 和cpu0 中的cacheline在逻辑上是同一行(直接映射机制中是同一行,组相联映射中则是同一组)
当CPU 0对arr[2]写时,该cacheline是invalid状态,故CPU 1需要将cacheline中的数组数据传送给CPU 0,CPU 0在对其cacheline写时,又会将CPU 1中相应的cacheline置为invalid状态
……
如此往复,cache的性能遭到了极大的损伤!此程序在多核处理器下的性能还不如在单核处理器下的性能高。
多CPU同时访问同一块内存区域就是“共享”,就会产生冲突,需要控制协议来协调访问。会引起“共享”的最小内存区域大小就是一个cache line。因此,当两个以上CPU都要访问同一个cache line大小的内存区域时,就会引起冲突,这种情况就叫“共享”。但是,这种情况里面又包含了“其实不是共享”的“伪共享”情况。比如,两个处理器各要访问一个word,这两个word却存在于同一个cache line大小的区域里,这时,从应用逻辑层面说,这两个处理器并没有共享内存,因为他们访问的是不同的内容(不同的word)。但是因为cache line的存在和限制,这两个CPU要访问这两个不同的word时,却一定要访问同一个cache line块,产生了事实上的“共享”。显然,由于cache line大小限制带来的这种“伪共享”是我们不想要的,会浪费系统资源(此段摘自如下网址:http://software.intel.com/zh-cn/blogs/2010/02/26/false-sharing/
对于伪共享问题,有2种比较好的方法:
1. 增大数组元素的间隔使得由不同线程存取的元素位于不同的cache line上。典型的空间换时间
2. 在每个线程中创建全局数组各个元素的本地拷贝,然后结束后再写回全局数组
而我们要说的linux cache机制,就与第1种方法有关。
5. Cache友好的代码
Cache友好的代码,简单地说,
在单核环境下,有一个典型的例子:
Cache友好的代码:
由于一般的机器中,C语言数组都是按行优先存储的。假设Cacheline的大小为B个字节,Cache总容量为C字节,直接映射存储方式,那么一共有C/B行Cacheline。对于a[M][N]这个M*N个字节。每每读到第 n*B 个数组元素时( 0
Cache不友好的代码:
这个代码是按列优先访问的,情况要复杂一些。我们只看一种比较简单的情况:
当赋予M,N较大值时,测试结果将会是列优先访问程序的运行时间远远大于行优先访问程序运行时间。
多核环境下,只要不同的线程或者进程访问同一cacheline的不同内容,就会发生“伪共享问题”。这样的问题较为隐蔽,难以发现。
6. GCC Attribute
7. 头文件
代码就不贴了
a. L1_CACHE_ALIGN(x)这个宏
该宏返回x所指向的内存区域的起始的cacheline的边界地址。
b. ____cacheline_aligned宏
该宏是gcc属性,对定义的数据结构做空间对齐,使之起始位置对齐cacheline
c. __cacheline_aligned宏
把数据分配到data段的cacheline_aligned子段里面,并且数据的起始位置对齐cacheline。.data..cacheline_aligned的定义在arch/XXX/kernel/vmlinuz.lds.S下面,有兴趣的读者可以自行查阅代码
b和c宏看起来很类似,只差了2个下划线而已,区别在于前者用于局部数据的声明,后者声明于全局数据,可以放在.data段
有一些在多处理器体系结构下的关键数据结构,就是用cacheline_aligned来声明的,譬如:


