分类: 服务器与存储
2008-07-29 09:22:33
重复数据删除在实际实现方式上包括联机处理和后期处理两种类型。不同的厂商拥护不同的技术,开发不同的产品,也为这两种实现方式的优劣争论不休。实际上联机重复数据删除和后期处理重复数据删除技术只不过是技术实现方式的不同而已,而无孰优孰劣之分。而且我认为争论哪种方式更好就如同讨论同步复制和异步复制方式谁更好一样。两种方式各有长短。 重要的是何种方式能够更好地满足客户的数据备份需求。
以下我阐述了重复数据删除技术的这两种实现方式以及各自的技术特点,借此希望能消除人们的对这两种处理方式的误解,并对客户选购具备重复数据删除特性的备份设备时有所帮助。
首先,我简述一下两种方式的实现原理和过程。
联机重复数据删除技术(我觉得称之为同步方式更合适)
当大量的备份数据流到达具备重复数据删除技术的备份设备时,首先驻留在内存里,重复数据删除引擎开始对先到的备份数据进行辨识,判断是否存在已保存过的数据块。 如果有,则写入一个指针来代替实际数据块的写入过程。如果没有,则写入该新数据块。任务结束。
采用这种方式进行重复数据删除工作,可以显著降低I/O的开销,因为大部分工作是在RAM内完成的。只是在做哈希算法查找重复的数据块时产生了少量的磁盘操作(只有一家厂商声称他们的哈希查找也是在RAM内完成的)。
某些重复数据删除产品还需要花费额外的时间,对于在原有数据块中初步已判断重复的数据块进行读操作,在字节级别确认匹配后才会舍弃。假设重复数据删除比为10:1,那么95%的处理时间只是对于重复的数据块进行一次写操作,用来更新哈希表就可以了,对于冗余的数据块丢弃即可而无需对磁盘进行其他任何写操作。剩余5%的时间用来将那些唯一的数据块写入磁盘并更新哈希表。
后期处理重复数据删除技术(我觉得称之为异步方式更合适)
当备份开始向备份设备传输备份数据流时,会将整个备份数据量作为一个整体来传送。 然后启动单独的进程开始读取已写入磁盘的数据块,开始重复数据删除处理过程(该过程通常由另外一个设备执行,访问备份数据已写入的磁盘),如读入的数据块和已的数据块重复了,则用指针替代该数据块,如果没有重复,则将该新数据块留在磁盘上,而无需任何其他操作。
这种处理方式比联机处理方式显然需要更多的I/O操作。首先,后期处理方式要求进行所有备份数据块的写入操作。 然后,还需要对写入的所有数据块进行再读入操作,并与哈希表记录进行对比查找重复的数据块,这就需要额外的磁盘读操作。某些厂商的产品还要求进行再次的读操作来确认数据块在字节级别的重复。如果确认了重复的数据块,需要进行删除重复的数据块的写操作,另外还需要发起更新哈希表的写操作,该过程占用了整个处理过程95%的时间。余下5%的时间用来处理那些不匹配的数据块,同样需要对哈希表进行更新写操作。
下表总结了两种处理方式的技术特点:
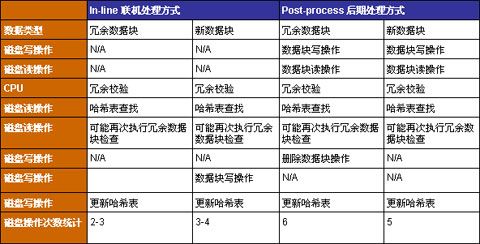
*某厂商宣称他们可以将哈希表保留在RAM内,这样就无需执行磁盘读操作来检查哈希表了。
