分类: 服务器与存储
2008-07-28 20:16:38
需求
目前企业信息化已经有了一定的积累,表现为或多或少积累了多个应用系统,在新系统构建或就系统升级中就出现了需要在多个系统进行数据迁移的需求。在不考虑扩展性和可维护性,表接口方式不失为一种高效的手段,因为它往往只需要后开发系统一方做开发工作,原系统只需提供数据字典即可。
作为独立的迁移工具,MSSqlLServer 的DTS或者Access的链接表都是不错的选择,但是这些必须是管理员去操作这些工具,不适合作为系统功能。
本数据迁移器开发目的: 提供一种可重复使用的,有可视化配置能力的,有良好系统接口的组件化工具。
规则分析
根据上面的需求,我们抽象出业务对象,主要就是两个数据集,来源数据集我们称之为A表,目的数据集我们称之为B表。然后进一步分析其规则:
数据库方面
A和B 可能在不同的数据实例中
A 可能是试图或是一个查询(但出于方便,下面都称A表 和B表)。
A和B可能是异构的。
但是 A 和B 必有用于判断是否对等记录的逻辑键Keys,A和B 的对应字段也必须是类型兼容的。
业务方面
业务需求往往不是需要简单的数据同步,在数据迁移前或迁移后需要触发一些其他的业务逻辑,所以要提供处理事件或调用存储过程的能力。
触发时机
可能是管理员去手工处理数据同步,也可能是系统事件去触发,还可能是时间管理器定时触发。前两种情况由二次开发宿主决定,后一种我们可以提供时间任务管理器。
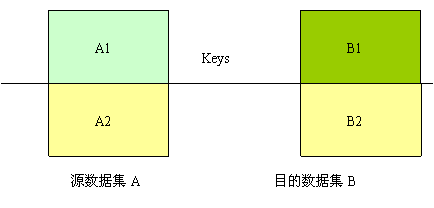
将源数据集A的数据迁移到目的数据集B中,根据逻辑字段Keys判断两表的数据是否“相同”,做如上划分,A1源表中的新数据,A2和B2 为逻辑相同的记录,B1 为目的表的专有数据。
抽象一般的数据迁移需求都可归结为如下迁移策略
1) 插入: 仅将A1 部分 Insert 到 B
2) 更新: 仅将A2 部分的非逻辑主键字段内容更新到B2
3) 插入更新: 插入+更新
4) 复制 : 将A代替B,意味着清空B,插入A的内容
5) 克隆: B并不存在,需要创建B并复制A
6) 删除: 删除B1
7) 删除更新: 删除+更新
8) 双向同步: A中加入B1,B中加入A1,A2更新B2或B2更新到A2
把上面的迁移策略再进行动作分解、归纳
迁移动作:
i. 插入A1
ii. 用A2更新B2
iii. 删除B1
iv. 清空B
v. 根据A创建B
这几个动作可组合出上面提到的各种策略,对双向同步无非是 A换成B,B换成A来考虑。
1) 数据源A并不一定是一个完整的表,它可能只是在条件约束下的数据集。
2) 字段对应,这项工作很繁琐,包括字段类型兼容性和长度检查,但做这类工作是计算机的拿手戏,所以应提供一工具。
3) 字段对应的信息需要持久化,XML是首选。
4) 目的表字段可能在来源表找不到直接的对应字段,而需要通过其他字段计算得出,所以要支持表达式。
5) 目的表可能存在非空字段,但该字段又在来源表中无对应字段,这需要填充常量。
6) 表达式或者常量都可能需要变量计算,需要支持参数变量。
7) B表可能有自己的物理主键,新增记录时需要依靠 序列 或者 自增长型字段填充。
好了,想下去还会有,想到了再加入,咱也Aglie。
根据上面已知的策略和补充考虑设计如下的对象模型
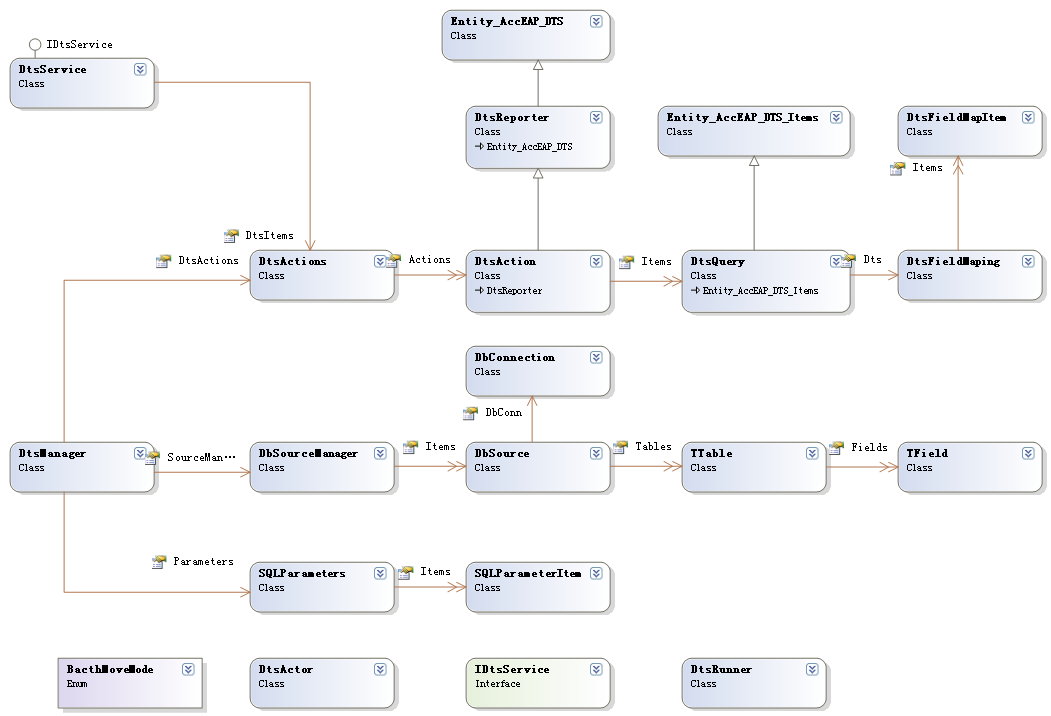
DtsManager 从名字上就能知道它是最根本的类,它管理了DtsActions 、DtsSourceManager、SQLParameter三个关键类。
DtsActions体系:
一个数据迁移项目命名为 DtsAction ,它是数据迁移的基本单位,一个DtsAction可分解为多个步骤,每个步骤就是一个DtsQuery(这个名字有点勉强),每个迁移步骤又可分解为多个迁移动作,也就是上面提到5种之一。另外DtsQuery还可以表示迁移或迁移后的数据整理,它实际是执行一个调用存储过程或引发一个代理。一个DtsAction将启动一个事务。
DtsFieldMaping 是一个字段对应处理器,是一个辅助类。因为自段对应信息是采用 【A表字段1~B表字段1,A表字段2~B表字段2】形式组织的,这样做无非是为了便于持久化存储,尤其是在使用数据表存储时,但这种结构不利于字段的对应操作,DtsFieldMaping类则可以把这种组织格式转化为两个列表结构。
DtsSourceManager ,也是一个管理者,主要管理的是数据库连接信息和数据库Schema信息。DbConnetion、Ttable、Tfield就很容易理解了,都对应于具体的数据库对象,是我们都很熟悉的东西。DtsSourceManager 还负责DbConnetion 的持久化工作,Ttable和 Tfield信息并不持久化,而是依赖DbConnetion 信息LazyLoad出来的。
DtsParameter类也好理解,它是处理参数的,包括参数的动态计算,参数的持久化等。
上面的几个类都是信息组织类,用于管理数据迁移需要的数据结构。
DtsService类是对外的唯一通道,它提供便利的调用数据迁移的服务,如 通过名称调用 数据迁移。该类对象通过单一模式产生。与时间管理器的结合也是通过这种方式。
真正关键的类是 DtsActor,它是数据迁移的执行器,根据DtsAction 的信息,DtsActor完成数据迁移工作。一个DtsActor 内聚的DtsRunner 类对应处理DtsQuery,因为DtsQuery类型不同,DtsRunner当然也有别。也就是说有一种类型的DtsQuery,至少应该对应有一种DtsRunner。进行二次开发,重点实现的也正是DtsActor和DtsRunner。
下面提供一种DtsActor 的实现
适用条件:
仅针对Oracle数据库间的数据迁移,
要求目的库有在来源库上建立 DBLink权限,并可对接口数据表有只读以上的权限。
实现:
由上面知道,实现迁移也就是实现五个迁移动作
这里五个动作是完全使用 PLSQL语句实现,具体如下
vi. 插入A1 insert into B( FB1 , FB2) select Fa1,Fa2 From A [Where 数据限制条件];
vii.用A2更新B2 update B set (Fb1,Fb2) =(select Fa1,Fa2 from A where A.Ka1 =B.Kb1 [and ...]) where exists (select 1 from A where A.Ka1 =B.Kb1 [and ...]);
viii. 删除B1 Delete B where exists (select 1 from A where A.Ka1 =B.Kb1 [and ...]);
ix. 清空B Truncate table B;
x. 根据A创建B Create table B from Select * from A where 1=2
都是SQL 语句,参数也只是做简单的字符串替换就可解决,表达式可扩展到所有PLSQL支持的表达式。实现上很简单,执行效率也是最高,当然是在上面的限制条件之下的简单。
其他的实现
上面的方案是借助 Oracle 的 Dblink 来实现, SQLServer 有外部数据源,Access的Jet引擎也有链接表,都是雷同的实现方案。如果你是个SQL 爱好者,你会喜欢这样的处理方式。
如果数据库不同,表又是异构,通用的处理方案应该是自己处理数据集,实现上述五种操作也不存在太多难度。
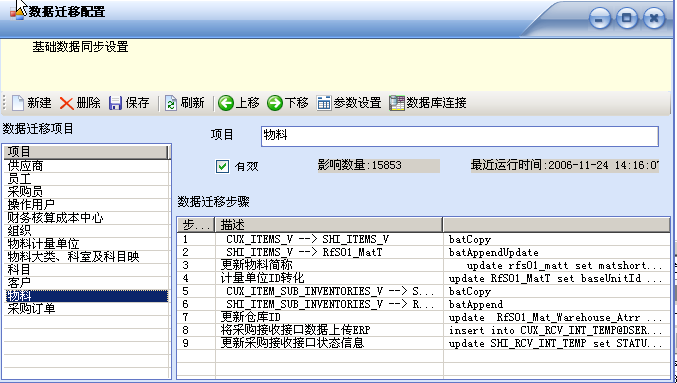
一个迁移项目下有多个迁移步骤,这些步骤将在一个事务内执行。
描述中 A--->B 格式的表示从A导数据到B,其中的字段对应使用下面的字段映射器进行配置。 汉字描述的为一个 预处理或后处理,预处理和后处理一般用于准备数据整理工作。
如果一个复杂的数据迁移,即便划分很多的迁移步骤也仍很困难时,可以考虑使用中间表,就是形成 A-->A'-->B 的形式,当然更复杂的话,A'可以是多个。
还有一种情况是一个来源表 多个目的表,也可以拆解为多个步骤来实现。反过来多个来源表的情况,你只有建立一个试图,把多个来源表简化成一个就OK了。
迁移步骤很重要,你可以通过右键菜单(上图没显示出来)的“上移”、“下移”调整步骤。其他的“编辑”、“删除”功能也在右键菜单中。
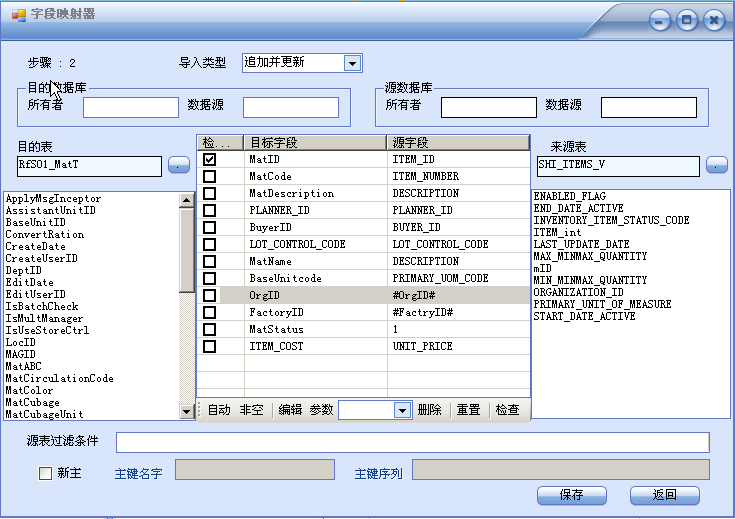
“导入类型” 就是上面提到的迁移策略。
来源表和目的表都有“所有者”和“数据源”,这是数据库的组织方式决定的,同一个数据库,同一个用户就不需要填写。不同数据库,就在“数据源”中填入 DBLink的名字(对oracle方案,其他的雷同)。“所有者” 就是数据库用户。
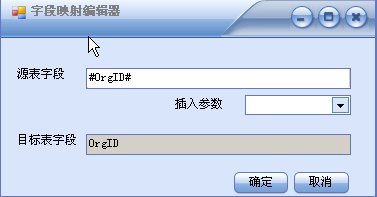
通过选择来源表和目的表,两表的字段将显示在左右两列表中,然后可以通过拖拽动作进行字段匹配。 需要使用表达式的字段,点击“编辑”按钮,进入表达式编辑界面,表达式中可使用参数。
表达式中仅仅式一个参数时,直接在参数中选择就可以了。
“源表过滤条件”用于解决补充考虑的第一点。
“新主键” 表示目的表需要使用新的物理主键,除指定主键的名字外,还有给出对该字段赋值的序列。解决了补充考虑的第7点。
从上面的三个列表中任何一个都可以拖拽字段名字到“源表过滤条件”编辑框,方便您的编辑。“主键名字”编辑框也可以接受上面的拖拽,并且主键序列默认自动命名为“SQ_目的表”,当然你可以更改这个默认命名,关键是别忘了要保证这个序列在数据库中真实存在,系统不负责创建序列,也不检查序列的存在性。
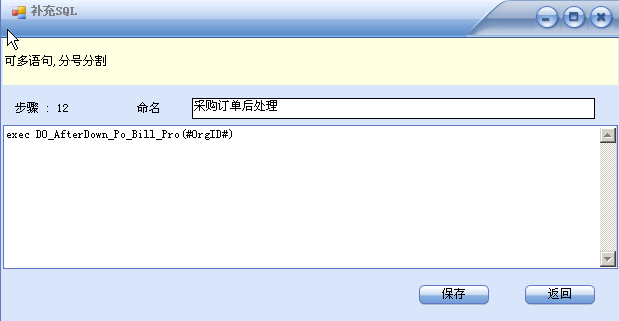
迁移的后处理,截图中的示例是调用一个存储过程 Do_After_Po_Bill_Pro, #OragID#代表调用参数为一个 。
这里的语法需要数据访问层做些解析工作,如下面的写法
Exec procName(P1[,p2,.....])
Exec 表示要执行一个存储过程,区别于一般的 数据更新语法
存储过程名后的括号里是参数值列表,这也需要数据访问层能支持不带参数名的调用方式。ADO.net 的 SQLCommand和 OracleComman都支持这中写法,但 OleCommand不支持,请注意。
这里的语句可以是多个,用“;” 格开就可以了。建议只写一个,并取一个到位的名字,这样会使你的迁移步骤看上去很清晰。
一个DBConnecion 是一个名称,数据库类型和一个数据库连接串,,在数据库连接串的编辑框中,右键菜单提供了多种数据库连接串的模板,如下图示。
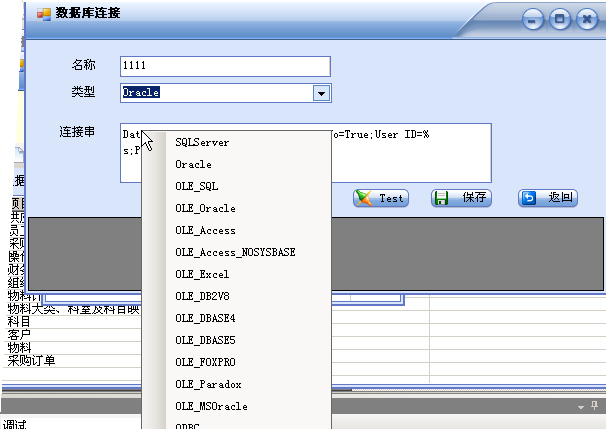

内置了上图所示的参数,您可以添加新的参数在表达式中使用。
//创建数据迁移器服务
DtsService Service = new DtsService();
///也可以使用默认服务对象
/// DtsService Service = DtsService.Default;
try
{
//调用服务
DtsReporter dtsResult= Service.ExecuteDTS("客户");
if (dtsResult.UPDATECOUNT > 0)
MessageBox.Show("成功导入数据 :"+dtsResult.ResultMessage);
}
catch (ApplicationException ex)
{
//异常处理
}
总结
写到这里,才发现是高估了自己的能力,以这些文字恐怕还远没介绍清楚,放出源码,希望能对各位有所作用。
另外排版上也苦煞俺了,不知道有没有好办法把 Word 中的排版直接贴上来。