分类: LINUX
2011-09-08 16:36:23
看到csdn上一篇管理Linux内核文章,感觉比较好,摘录如下:
(注)原文的链接: http://blog.csdn.net/leisure512/archive/2010/01/14/5188986.aspx
最近,开始研读一下Linux的内核代码,刚一开始,就有令人惊叹的发现,不得不感叹内核代码设计得之美!单是最常用的链表也设计得不得不令人佩服!
1.1.链表list_head
include/linux/list.h
很经典,链表在内核中很常用,例如管理进程,进程的各个状态队列都是使用这个双向链表实现的。内核中的链表定义成和数据无关的形式,而不是通常我们使用的链表格式,例如
typedef struct _list{
Elemtype elem;
struct _list *next;
}list;
内核中的链表定义为
struct list_head{
struct list_head *next, *prev;
};
可见,这个链表节点中不包含任何数据,只有两个指针。当需要使用链表来组织数据结构时,这个结构中就包含一个list_head成员,例如
struct _list_struct{
Elemtype elem;
struct list_head list;
...
};
显而易见,链表实现成和数据分离的好处是,不用为每种数据都定义链表操作,可以使用统一的链表操作即可。但是问题是:只知道数据成员list的地址,怎样去访问自身以及其他成员呢?
#define list_entry(ptr,type,member) \
container_of(ptr,type,member)
而container_of(ptr,type,member)宏定义在include/list/kernel.h中
#define container_of(ptr,type,member) ({
const typeof( ((type *)0)->member) *__ptr=ptr;
(type *)( (char *)__ptr - offsetof(type,member));})
上面的宏有几点需要解释:
1)typeof(type) 宏
typeof(type) 宏返回变量type的类型,例如:int a; typeof(a) b;等价于int b;
2)offsetof(type,member)宏
它定义在include/linx/stddef.h中,如下:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
这个宏返回member在type类型中的偏移量,type是一个结构,例如:
typeof(list_head,next);返回0,也就是返回相对于结构起始地址的偏移量。
3)为什么要使用typeof(((type *)0)->member)来定义指针 __ptr,而不是这样:
const typeof(member) *__ptr=ptr;?
其实,这个很简单,因为member是结构的成员,只能通过结构来访问!
4)访问数据
在文件include/linux/list.h中,有访问链表数据的代码
#define list_for_each_entry(pos, head, member)
for(pos=list_entry((head)->next,typeof(*pos),member);...)
从上面的使用来看,替换list_entry宏以及container_of宏后,变成如下:
pos=({const typeof(((typeof(*pos) *)0)->member) *__ptr=(head)->next;
(typeof(*pos) *)((char *)__ptr - offsetof(typeof(typeof(*pos)),member));});
1)这里的语法很奇怪,小括号()中包含了一个代码段{},这是平常都见不到的。
1.2.链表hlist_head
hlist_head链表也是一个双向链表,它的定义如下
struct hlist_head{
struct hlist_node *first;
};
struct hlist_node{
struct hlist_node *next, **prev;
};
显然,这个双向链表不是真正的双向链表,因为表头只有一个first域,为什么这样设计?代码中的注释解释:为了节约内存,特别适合作为Hash表的冲突链,但Hash表很大时,那么表头节约下来的内存就相当客观了,虽然每个表头只节约一个指针。
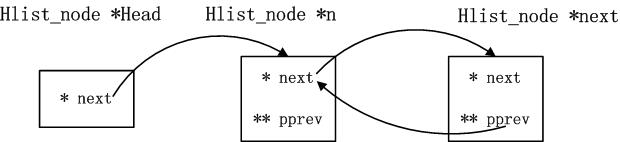
同时,表头的不一致性也会带来链表操作上的困难,显然就是在表头和首数据节点之间插入节点时需要特别处理,这也就是为什么会设计二级指针pprev的原因。看看代码
static inline void hlist_add_before(struct hlist_node *n,struct hlist_node *next)
{
n->pprev=next->pprev;
n->next=next;
next->pprev=&n->next;
*(n->pprev)=n;
}
解释:指针n指向新节点,指针next指向将要在它之前插入新节点的那个节点。
看上面的代码,就可以看到二级指针pprev的威力了!有没有看到,当next就是第一个数据节点时,这里的插入也就是在表头和首数据节点之间插入一个节
点,但是并不需要特别处理!而是统一使用*(n->pprev)来访问前驱的指针域(在普通节点中是next,而在表头中是first)。这太经典
了!
/* 上面这段代码的我的注释
* n->pprev=next->pprev; //待插入节点的二级指针与插入前next节点的二级指针相同
* n->next=next; //待插入节点的一级指针next为下一节点next
* next->pprev=&n->next; //下一个节点的二级指针的值为待插入节点的next变量的地址
* *(n->pprev)=n; //待插入节点的上一个节点的next域(n->pprev)的值为待插入节点地址
*/
下面是我的理解的图示: