Zoie是linkedin公司基于Lucene实现的实时搜索引擎系统,按照其官方wiki的描述为:
Zoie是一个实时的搜索引擎系统,其需要逻辑上独立的索引和搜索子系统相对紧密的结合在一起,从而使得一篇文档一经索引,就能够立刻被搜索的到。
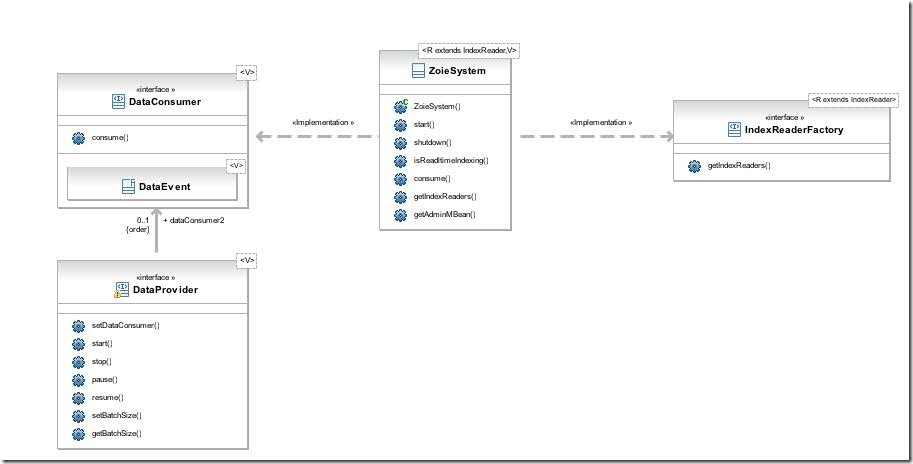
ZoieSystem是Zoie的重要组成部分,其一方面通过实现DataConsumer接口而完成了索引功能,一方面通过实现IndexReaderFactory>而完成了搜索功能,并将二者紧密的结合在一起。
下面就是ZoieSystem的总体架构图:
- 对于索引系统来讲,ZoieSystem是一个DataConsumer,也即是一个消费者,其有函数consume用于消费DataEvent对象而完成索引功能。
- 既然其是消费者,则向其提供数据的就应该是生产者DataProvider,要想使用Zoie建立实时搜索系统,必须提供自己的生产者。
- 对于搜索系统来讲,ZoieSystem是一个IndexReaderFactory,也即是一个能够得到读取索引的IndexReader的工厂,其有函数getIndexReaders得到所有的IndexReader列表,从而可以完成对索引数据读取的功能。
- 熟悉Lucene的读者应该很清楚,要想对Lucene的索引进行搜索,则首先要得到IndexReader,然后根据IndexReader生成IndexSearcher,从而可以进行搜索,收集结果,打分,排序等过程。既然IndexReader可以通过Zoie的工厂得到,用户需要实现自己的搜索逻辑方可。
Zoie实现实时搜索的原理1、利用两个内存索引一个硬盘索引实现实时搜索的原理(1) 当系统启动的时候,索引处在Sleeping状态,这时Mem结构中,只有索引A,索引B为null,索引A为_currentWritable,_currentReadOnly为null,_diskIndexReader为硬盘索引的IndexReader。由于内存中索引的IndexReader是每添加完文档后立刻更新的,而且速度很快,而硬盘上的索引一旦打开,在下次合并之前,一直使用,可以保证新添加的文档能够马上被搜索到。

(2) 当A中的文档数量达到一定的数量的时候,需要同硬盘上的索引进行合并,因此要进入Working状态。合并是一个相对比较长的过程,这时候会创建内存索引B,在合并过程中新添加的文档全部索引到B中。此时的Mem结构中,有内存索引A,内存索引B,索引A为currentReadOnly,索引B为currentWritable,diskIndexReader为硬盘索引的IndexReader。此时要获得ZoieSystem的IndexReader,则三个IndexReader全都返回,由于索引B的IndexReader是添加文档后立刻更新的,因而能够保证新添加的文档能够马上被搜索到,这个时候虽然索引A已经在同硬盘索引进行合并,然而由于硬盘索引的IndexReader还没有重新打开,因而索引A中的数据不会被重复搜到。

(3) 当索引A中的数据已经完全合并到硬盘上之后,则要重新打开硬盘索引的IndexReader,打开完毕后,创建一个新的Mem结构,原来的索引B作为索引A,为currentWritable,原来的索引A被抛弃,设为null,currentReadOnly也设为null,diskIndexReader为新打开的硬盘索引的IndexReader。然后通过无缝切换用新的Mem结构替代旧的Mem结构,然后索引进入Sleeping状态。

2、有关文档的更新问题上面一节中,我们可以看到,对于新添加的文档的实时搜索问题相对简单,然而当遇到文档更新的时候,就相对复杂了。
如何实时的删除已经索引在硬盘上的文档是一个很大的问题,为此Zoie实现了ZoieSegmentReader:
- 成员变量_decoratedReader是ZoieSegmentReader把Lucene的IndexReader被用户指定的装饰器装饰后又封装了一层。
- long[] _uidArray是从Lucene的文档ID到Zoie的文档ID的一个对应,Lucene的文档ID是下标,Zoie的文档ID是对应项的值。
- IntRBTreeSet _delDocIdSet表示在此索引中删除的Lucene的文档ID
- 在索引中,Zoie的文档ID是作为一个特殊的Term(“_ID”, “_UID”)的倒排表中每个Lucene的文档号的Payload信息保存的,保存为如下格式,其fillDocumentID函数就是将Zoie的文档ID放入Payload中。
- 当要从此ZoieSegmentReader中删除文档的时候,调用markDeletes函数,将要删除的文档的Zoie文档号通过DocIDMapper转换为Lucene的文档号,将Lucene的文档号加入_delDocIdSet
- 熟悉Lucene的读者应该知道,IndexReader是通过TermDocs接口从索引中取得倒排表的,Zoie也实现了自己的ZoieSegmentTermDocs,其有一个DocIdSetIterator作为成员变量,是在生成的时候由ZoieSegmentReader将自己的_delDocIdSet的遍历器传给它的,每当取下一个文档号的时候,其会将DocIdSetIterator中有的文档号过滤掉。对于TermPositions也是同样实现了ZoieSegmentTermPositions
- ZoieSegmentReader使得较慢的从硬盘索引中删除文档的操作变为较快的在内存中的标记操作,并且不用重新打开IndexReader删除就能够被看到,还保证了更新的完整性(更新的操作是一个删除,外加一个添加,新添加的文档最初是在内存索引中,则删除操作也应该在内存中被标记,否则一旦系统crash,会出现新添加的丢了,老的版本也被删除了的情况,即便有重做机制也难以实现).
有了ZoieSegmentReader,下面我们来看文档更新情况下的实时搜索机制。
(1) 最初系统启动的时候,是在Sleeping状态下的,这个时候,内存索引为空,硬盘索引上有文档A,B,C。

(2) 在Sleeping状态下,更新文档B,则新的文档B进入内存索引,而硬盘索引中B被标记删除。

(3) 当内存中索引足够大的时候,索引会进入Working状态,进入合并过程。合并过程会首先将硬盘索引中被标记删除的文档先真实的删除,然后再将内存索引向硬盘索引进行合并。此时如果有新的更新进入,比如更新文档A,则将在另外一个内存索引和硬盘索引中都标记删除,然后将新文档添加到内存索引中。

(4) 当合并完毕后,硬盘索引会标记删除原来在内存索引中标记删除的文档,被合并的索引以及其标记删除的文档全部丢弃,索引进入Working状态。

Zoie的索引过程1、将文档添加到内存索引(1) Zoie的索引过程由DataProvider中调用ZoieSystem的consume函数开始,其实是调用AsyncDataConsumer的consume(Collection> data)函数,其仅仅将DataEvent放在LinkedList> _batch中。
(2) AsyncDataConsumer有一个背后的线程ConsumerThread _consumerThread,其会调用_consumer.consume(currentBatch),由ZoieSystem的构造函数中第(5)步我们知道,此处的_consumer为RealtimeIndexDataLoader _rtdc。
(3) RealtimeIndexDataLoader.consume函数分一下几个步骤:
- 调用_interpreter的convertAndInterpret函数,将所有的DataEvent转换为ZoieIndexable,放入链表ArrayList> indexableList。ZoieIndexable其中封装了Lucene的Document
- RealtimeIndexDataLoader在创建的时候,除了传进去的DiskLuceneIndexDataLoader作为成员变量_luceneDataLoader,还会创建成员变量RAMLuceneIndexDataLoader _ramConsumer用于索引到内存索引。在上一步做完后,调用_ramConsumer.consume(indexableList)将这些ZoieIndexable索引到内存中。
(4) RAMLuceneIndexDataLoader的consume函数会调用LuceneIndexDataLoader的consume函数,其包含以下步骤:
- 得到RAMSearchIndex idx
- Zoie对所有的文档都做更新操作,将文档ID放入LongOpenHashSet delSet,将封装Lucene的Document的IndexingReq放入List docList中
- 对于每一篇文档,使用ZoieSegmentReader.fillDocumentID(doc, uid)向Payload中添加Zoie的文档ID
- 更新内存索引idx.updateIndex(delSet, docList, _analyzer,_similarity),其中先用IndexReader删除,再用IndexWriter进行添加
- 当然要被删除的文档除了在内存索引中删除掉之外,还要在另外一个内存索引和硬盘索引中过滤掉。因而调用RAMLuceneIndexDataLoader的propagateDeletes(LongSet delDocs)函数:
- 首先得到另一个内存索引,这个时候应该是ReadOnly并正在和硬盘索引合并的索引:RAMSearchIndex readOnlyMemoryIdx = _idxMgr.getCurrentReadOnlyMemoryIndex()
- 在ReadOnly的内存索引中标记删除,从而搜索的时候可以将其过滤掉,readOnlyMemoryIdx.markDeletes(delDocs)
- 然后得到硬盘索引,DiskSearchIndex diskIdx = _idxMgr.getDiskIndex()
- 在硬盘索引中标记删除,diskIdx.markDeletes(delDocs),从而在搜索中可以将其过滤掉
2、将内存索引合并到硬盘索引RealtimeIndexDataLoader的父类是BatchedIndexDataLoader,其有一个背后的线程LoaderThread,其会调用processBatch函数。
RealtimeIndexDataLoader的processBatch函数过程如下:
(1) 当内存索引中的文档数量超过配置的batch size或者时间超过设置的_delay的时候,就进行内存索引到硬盘索引的合并。
(2) 设置索引的状态从Sleeping到Working,_idxMgr.setDiskIndexerStatus(SearchIndexManager.Status.Working)
- 重新构造Mem _mem结构
- 原来在Sleeping状态下用于添加新文档的memIndexA变成_currentReadOnly的
- 创建在Working状态下用于添加新文档的memIndexB为_currentWritable
- 在合并阶段,硬盘索引的IndexReader还是老的IndexReader
- 从代码我们也可以看出,内存索引A和B交换了位置:Mem mem = new Mem(memIndexA, memIndexB, memIndexB, memIndexA, oldMem.get_diskIndexReader());
(3) 得到需要合并的内存索引readOnlyMemIndex = _idxMgr.getCurrentReadOnlyMemoryIndex()
(4) 将内存索引合并到硬盘索引:_luceneDataLoader.loadFromIndex(readOnlyMemIndex),DiskLuceneIndexDataLoader的loadFromIndex函数做以下事情
- 得到DiskSearchIndex idx = getSearchIndex()
- idx.loadFromIndex(ramIndex),其中首先用IndexReader删除被标记的文档,然后调用IndexWriter的addIndexesNoOptimize函数将内存索引合并到硬盘
- 刷新硬盘索引的IndexReader,idx.refresh()
- idx.markDeletes(ramIndex.getDelDocs())继承内存索引中被标记删除的文档
(5) 设置索引的状态从Working到Sleeping,_idxMgr.setDiskIndexerStatus(Status.Sleep)
- 重新构造Mem _mem结构
- 将在Working状态下的memIndexB付给memIndexA以及currentWritable,而memIndexB设为null,也即把B当做A,没有B
- Mem mem = new Mem(oldMem.get_memIndexB(), null, oldMem.get_memIndexB(), null, diskIndexReader)
- lockAndSwapMem将Mem结构进行无缝切换
Zoie的搜索过程在使用Zoie进行搜索的时候,要调用ZoieSystem的getIndexReaders()函数,其调用了_searchIdxMgr.getIndexReaders()。
SearchIndexManager的getIndexReaders函数,分别得到RAMSearchIndex memIndexA的IndexReader,RAMSearchIndex memIndexB的IndexReader,以及硬盘索引的IndexReader。在Sleeping状态下得到两个IndexReader,在Working状态下得到三个IndexReader。







