简要说明
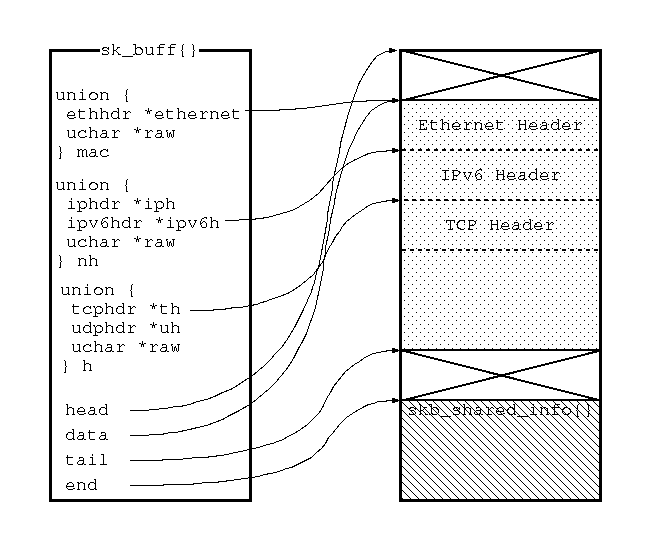
sk_buff结构可能是linux网络代码中最重要的数据结构,它表示接收或发送数据包的包头信息。它在中定义,并包含很多成员变量供网络代码中的各子系统使用。
这个结构被不同的网络层(MAC或者其他二层链路协议,三层的IP,四层的TCP或UDP等)使用,并且其中的成员变量在结构从一层向另一层传递时改变。L4向L3传递前会添加一个L4的头部,同样,L3向L2传递前,会添加一个L3的头部。添加头部比在不同层之间拷贝数据的效率更高。
由于在缓冲区的头部添加数据意味着要修改指向缓冲区的指针,这是个复杂的操作,所以内核提供了一个函数skb_reserve。
协议栈中的每一层在往下一层传递缓冲区前,第一件事就是调用skb_reserve在缓冲区的头部给协议头预留一定的空间。
skb_reserve同样被设备驱动使用来对齐接收到包的包头。如果缓冲区向上层协议传递,旧的协议层的头部信息就没什么用了。例如,L2的头部只有在网络驱动处理L2的协议时有用,L3是不会关心它的信息的。但是,内核并没有把L2的头部从缓冲区中删除,而是把有效荷载的指针指向L3的头部,这样做,可以节省CPU时间。
结构
内核把sk_buff组织成一个双向链表,这个链表还有另一个需求:每个sk_buff结构都必须能够很快找到链表头节点。为了满足这个需求,在第一个节点前面会插入另一个结构sk_buff_head,每个sk_buff结构都包含一个指向sk_buff_head的指针。
|
struct sk_buff_head {
struct sk_buff * next; /* These two members must be first. */
struct sk_buff * prev;
_ _u32 qlen; //链表元素的个数
spinlock_t lock; //防止对链表的并发访问
};
|
成员变量
struct sock *sk
这个指针在网络包由本机发出或者由本机进程接收时有效,因为插口相关的信息被L4(TCP或
UDP)或者用户空间程序使用。
如果sk_buff只在转发中使用(这意味着,源地址和目的地址都不是本机地址),这个指针是NULL。
unsigned int len
这是缓冲区中数据部分的长度。它包括主缓冲区中的数据长度(data指针指向它)和分片中的数据长度。它的值在缓冲区从一个层向另一个层传递时改变,因为往上层传递,旧的头部就没有用了,而往下层传递,需要添加本层的头部。len同样包含了协议头的长度。
unsigned int data_len
和len不同,data_len只计算分片中数据的长度。
atomic_t users
一个引用计数,用于计算有多少实体引用了这个sk_buff缓冲区。它的主要用途是防止释放sk_buff后,还有其他实体引用这个sk_buff。因此,每个引用这个缓冲区的实体都必须在适当的时候增加或减小这个变量。这个计数器只保护sk_buff结构本身,而缓冲区的数据部分由类似的计数器(dataref)来保护.
有时可以用atomic_inc和atomic_dec函数来直接增加或减小users,但是,通常还是使用函数skb_get和kfree_skb来操作这个变量。
unsigned int truesize
这是缓冲区的总长度,包括sk_buff结构和数据部分。如果申请一个len字节的缓冲区,alloc_skb函数会把它初始化成len+sizeof(sk_buff)
alloc_skb 和 dev_alloc_skb
alloc_skb用于分配缓冲区的函数。数据缓冲区和缓冲区的描述结构(sk_buff结构)是两种不同的实体,这就意味着,在分配一个缓冲区时,需要分配两块内存(一个是缓冲区,一个是缓冲区的描述结构
sk_buff)。
alloc_skb调用函数kmem_cache_alloc从缓存中获取一个sk_buff结构,并调用kmalloc分配缓冲区(如果有缓存的话,它同样从缓存中获取内存)。
dev_alloc_skb也是一个缓冲区分配函数,它主要被设备驱动使用,通常用在中断上下文中。这是一个alloc_skb函数的包装函数,它会在请求分配的大小上增加16字节的空间以优化缓冲区的读写效率,它的分配要求使用原子操作(GFP_ATOMIC),这是因为它是在中断处理函数中被调用的。
kfree_skb 和 dev_kfree_skb
这两个函数释放缓冲区,并把它返回给缓冲池(缓存)。kfree_skb可以直接调用,也可以通过包装函数dev_kfree_skb调用。后面这个函数一般被设备驱动使用,与之功能相反的函数是dev_alloc_skb。
dev_kfree_skb仅是一个简单的宏,它什么都不做,只简单地调用kfree_skb。这些函数只有在skb->users为1地情况下才释放内存(没有人引用这个结构)。否则,它只是简单地减小 skb->users。
克隆操作
如果一个缓冲区需要被不同的用户独立地操作,而这些用户可能会修改sk_buff中某些变量的值(比如h和nh值),内核没有必要为每个用户复制一份完整的sk_buff以及相应的缓冲区。相反,为提高性能,内核克隆一个缓冲区。克隆过程只复制sk_buff结构,同时修改缓冲区的引用计数以避免共享的数据被提前释放。克隆缓冲区使用skb_clone函数。
一个使用包克隆的场景是:一个接收包的过程需要把这个包传递给多个接收者,例如包处理函数或者一个或多个网络模块。
被克隆的sk_buff不会放在任何链表中,同时也不会有到socket的引用。原始的和克隆的sk_buff中的
skb->cloned值都被置为1。克隆包的skb->users值被置为1,这样,在释放时,可以先释放sk_buff结构。同时,缓冲区的引用计数(dataref)增加1(因为有多个sk_buff结构指向它)。
skb_share_check用于检查引用计数skb->users,如果users变量表明skb是被共享的, 则克隆一个新的sk_buff。
如果一个缓冲区被克隆了,这个缓冲区的内容就不能被修改。这就意味着,访问数据的函数没有必要加锁。
因此,当一个函数不仅要修改sk_buff,而且要修改缓冲区内容时,就需要同时复制缓冲区。在这种情况下,程序员有两个选择。如果知道所修改的数据在skb->start和skb->end之间,可以使用pskb_copy来复制这部分数据。如果同时需要修改分片中的数据,必须使用skb_copy。
next:sk_buff链表中的下一个缓冲区。
prev:sk_buff链表中的前一个缓冲区。以上两个变量将sk_buff链接到一个双向链表中。
sk:本网络报文所属的sock结构,此值仅在本机发出的报文中有效,从网络收到的报文此值为空。
tstamp:报文收到的时间戳。
dev:收到此报文的网络设备。
transport_header:传输层头部。
network_header:网络层头部。
mac_header:链接层头部。
cb:用于控制缓冲区。每个层都可以使用此指针,将私有的数据放置于此。
len:有效数据长度。
data_len:数据长度。
mac_len:连接层头部长度,对于以太网,指MAC地址所用的长度,为6。
hdr_len:skb的可写头部长度。
csum:校验和(包含开始和偏移)。
csum_start:当开始计算校验和时从skb->head的偏移。
csum_offset:从csum_start开始的偏移。
local_df:允许本地分片。
pkt_type:包的类别。
priority:包队列的优先级。
truesize:报文缓冲区的大小。
head:报文缓冲区的头。
data:数据的头指针。
tail:数据的尾指针。
end:报文缓冲区的尾部
alloc_skb之后
buffer从tcp层到链路层的过程中len,head,data,tail以及end的变化
阅读(2736) | 评论(0) | 转发(0) |