分类: C/C++
2010-06-29 23:21:28
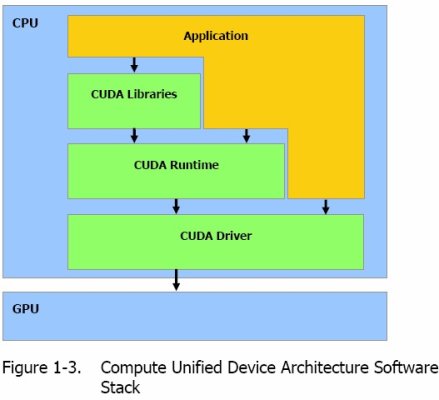
上图是CUDA系统的结构图,回头我会穿插的详解介绍每层的作用,并将同等功能映射到Direct3D程序中来。我们来着重了解下CUDA的编程模型,这个是了解硬件体系架构的基础。在CUDA中程序执行区域分为两部分,CPU和GPU——HOST和DEVICE,任务组织和发送是在CPU里完成的,但并行计算是在GPU里完成,每当CPU遇到需要并行计算的任务,则将要做的运算组织成kernel,然后丢给GPU去执行,当然任务是通过CUDA系统来丢,CUDA在把任务正式提交给GPU前,会对kernel做些处理,让kernel符合GPU体系架构(接下来几个概念是有对应的硬件的),现在先简单的把GPU想想成拥有上百个核的CPU,kernel当成一个要创建为线程的函数,所以CUDA现在要将你的kernel创建出上百个thread,然后将这些thread送到GPU中的各个核上去运行,但为了更好的利用GPU资源,提高并行度,CUDA还要将这些thread加以优化组织,将能利用共有资源的线程组织到一个thread block中,同一thread block中的thread可以通过share memory共享数据,每个thread block最高可拥有512个线程。拥有同样维度同样kernel的thread block被组织成一个grid,而CUDA处理任务的最大单元便是grid了。我们来看看CUDA中的可以使用的内存种类:
registers(Read-write per-thread)
local memory(Read-write per-thread)
shared memory(Read-write per-block)
global memory(Read-write per-grid)
constant memory(Read-only per-grid)
texture memory(Read-only per-grid)
提前先放个硬件体系图,下面的讲解大家会理解深入很多。
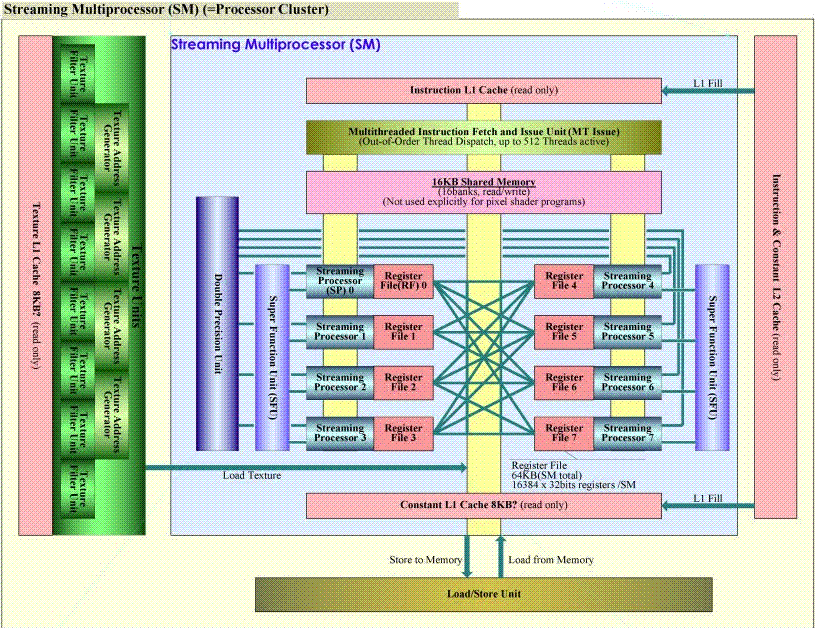
以上就是最大功能的执行单元的硬件体系图,很显然Regiter File、16KB的Share Memory都是ON-CHIP的,一个SM中的RF为64KB,16K个ENTRY,每个ENTRY 4BYTE用来存放单精度浮点数或者整数,而双精度浮点则需要占用相邻2个entry,注意这些ENTRY是JIT/DRIVER动态分配给thread的。我们在Shader中定义的局部变量一般都是分配在RF中,当RF不够用了就分到Local Memory中,可简单的将Local Memory当成线程堆栈,是存在于显存中的,注意并不是ON-CHIP。Texture Memory和Constant Memory都是在显存中,而且是只读的,特别的是他们跟CPU的内存一样,是可被CACHE到片上的,注意图中的Constant L1 Cache 8KB和Texture L1 Cache 8KB,另外在在SM之外还有256KB的Texture L2 Cache和Instruction&Constant L2 Cache。Global Memory可以被所有的thread读写,也存在于显存中,但CHIP上并没有CACHE这部分内存,所以对于Local Memory和Global Memory的读写应该是比较慢的。关于Cache的详细情况请参见我以前的文章和INTEL手册。
现在我们来看看grid是如何在GPU上执行的,首先,SM一次最多会处理8个thread block或者1024个thread,看哪个比较小,然后内部会将这些thread组织成warp,每个warp包含32个thread,因为SM一次最多可以同时处理32个thread,这里说明下,这种关于WARP的描述很容易蛊惑读者,其实一个WARP就是执行进度相同的32个KERNEL,而不同的WARP之间KERNEL是相同的,但执行进度是不一样的,虽然一个WARP中32个KERNEL执行进度相同(实际IP可能是不同的,因为可能存在条件跳转,这为后面描述条件跳转的LANTENCY埋下伏笔先。),但KERNEL处理的数据不一样,为什么是32个呢,因为SP的 执行延迟一般是4个周期,类似执行管线长度有4级,所以每个SP同时可以执行4条相同的指令来充分消除这些延迟,而一个SM中有8个SP,所以可以同时执行32个指令。可见GT200的SM一次可执行不同数据的32条相同指令,而且可以同时乱序执行32个warp,为什么要分WARP而不是把所有KERNEL都同等进度执行呢?因为很多指令的执行都是有延迟的,比如等待输入等,所以这时候就可以切到另外一个不用等待的WARP指令执行了。
SIMT编程模型
大概理解了一下GPU的执行流程,现在可以学习SIMT编程模型了。GPU与CPU的最大差别体现在内存系统上,CPU的内存系统的设计体现了良好的伸缩性,允许用户为系统更改升级内存,你可以用333MHZ的或者400MHZ或者DDR2或者DDR3,更换配置起来非常方便;而GPU的内存确实焊死在PCB板上,完全没有配置升级的可能性。GT200可以被实现在一块GPU上,但由于GT200相当的复杂,晶体管数量甚至超过了INTEL 四核CPU晶体管总数,这将会导致需要大面积的单芯片来制造它,随之而来的是较低的良品率和较高的制造成本,所以NVIDIA准备将单GPU的GT200用来其高端产品上,而低端产品采用两个芯片来制造,用两块PCB合起来构成完整的GT200,但由于逻辑部分很多在分开在不同的芯片上,所以会导致性能有所损失。
GT200着重解决并行计算的数据吞吐效率,而不是跟CPU一样重点在解决但线程的运行效率,GT200可以容忍不太高的单线程执行效率,但一定要有高的并行度,一次将尽可能多的数据投入到运算中。GT200由10个Thread Porcessing Cluster (TPC)组成第一级核心计算框架,而每个TPC由3个Streaming Mutiprocessor(SM)或者叫TPA加一个纹理硬件管线构成,纹理硬件管线又包含了8个Texture Filter和4个Texture Address Generator,每个SM都有单独的Front-End,包括取指、解码、分发逻辑和执行单元等等。另外需要注意的是,GPU制造厂商经常宣传说他们拥有“
很显然SM没有分支预测部分,也没有错误恢复机制,SM假设没有随机执行的指令,所以在遇到分支的时候,SM必须等待分支跳转地址计算OK了才取下面的指令,而后才开始继续工作。NVIDIA称其执行模式了单指令多线程——SIMT,与SIMD有什么区别呢?我们知道SIMD的运算数据必须是vector,而vector的宽度是与MICROARCHITECTURE紧密相关的,比如CORE2的SSE指令操作数为16个byte,同时能执行4个浮点数的运算;而SIMT模式,执行数据的宽度将作为硬件细节被隐藏起来,程序中不再关注数据宽度限制,说到这里大家可能有些迷糊,打个比方吧:
float
用SIMD指令形式就是:
__ALIGN(16) float f1[4];
__ALIGN(16) float f2[4];
__ALIGN(16) float f0[4];
;Initial operate
movaps xmm0, f1
movaps xmm1, f2
mulaps xmm0, xmm1
movaps f0, xmm0
而SIMT就是:
float f1[4];
float f2[4];
float f0[4];
void mul0()
{
f0[0] = f1[0] * f2[0];
}
void mul1()
{
f0[1] = f1[1] * f2[1];
}
void mul2()
{
f0[2] = f1[2] * f2[2];
}
void mul3()
{
f0[3] = f1[3] * f2[3];
}
CreateThread( mul0 );
CreateThread( mul1 );
CreateThread( mul2 );
CreateThread( mul3 );
怎么样?明白了吧,一条乘法指令分成了4个线程来执行,而这4个线程在GPU是完全能并行运行。这样的好处就是不管你VECTOR是3分量还是4分量还是5分量,unified shader都可以利用scalar来处理,只不过线程创建数量不同而已,不再关心硬件限制。另外一个原因是纯粹使用SIMD不能并行的执行有条件跳转的函数,很显然条件跳转会根据输入数据不同在不同的线程中有不同表现,这个只有利用SIMT才能做到。另外一个就是效率问题,我们知道在线程经过条件跳转后,一个WARP中的32个IP可能指向了不同的地方,但8个SP共用了取指译码前端,所以Front-End需要依次为IP不同的SP发送指令,当然IP相同的SP是不需要重复发送指令的,系统通过一个硬件堆栈和每线程所有的断言逻辑来做到不重复发送相同的指令。另外一个目的就是让同一个vector中的每个元素能互相交换计算。每个thread都严格拥有私有的register file,不同thread之间只能通过share memory来做低延迟的通信。但后来CUDA中又加入了一些warp信息统计的函数如__any()、__all()却又让warp这样一个软件概念硬件化,违背了SIMT隐藏硬件细节的初衷啊。
总的来说GPU可优化的地方还很多,不具备RAT、指令依赖分析、投机执行等目前CPU上诸多特性,所以SP上运行的线程做不到乱序执行,而并行运行冲突也没有解决(至少从文档中暂时没看到有这机制),流水线也没有错误回滚机制(你可以是试着除0看看),连个分支预测都没有,内存管线也没有CPU强大,总的来说跟目前先进的CPU在技术上还是有差距,当然很多没有的特性是出于高效执行和低能耗考虑的,所以盲目的将CPU与GPU作对比还是没有太大意义,毕竟各司其责,在经济大衰退的背景下,看看IC行业大的企业财报,目前好像也只有INTEL一家不亏损,NV AMD任重道远。
上篇就到此吧,如果只是关注CUDA和并行软件的编程,到这个深度就OK了,下篇主要是为了深入了解GT200并行架构,介绍深入优化图形程序所需的基础,有Geometry Shader、Pixel Shader、Vertex Shader、Unified Shader、Setup/Raster详细讲解,SM流水线介绍,GT200的内存LOAD和STORE,纹理管线以及PerfHUD Frame profiler面板深入解析,敬请关注effulgent.cnblogs.com。
