分类:
2010-10-11 15:24:42
 |
|
For example:
/dev/rd/c0d0p3 /test ext2 noatime 1 2
The is another kernel tuneable that can be tweaked for improved disk i/o in some cases.
The value stored in /proc/sys/vm/dirty_background_ratio defines at what percentage of main memory the pdflush daemon should write data out to the disk.
If larger flushes are desired then increasing the default value of 10% to a larger value will cause less frequent flushes.
As in the example above the value can be changed to 25 as shown in
# sysctl -w vm.dirty_background_ratio=25
The default value 10 means that data will be written into system memory until the file system cache has a size of 10% of the server’s RAM.
The ratio at which dirty pages are written to disk can be altered as follows to a setting of 20% of the system memory
# sysctl -w vm.dirty_ratio=20
For the Adaptec aic7xxx series cards (2940's, 7890's, *160's, etc) this can be enabled with a module option like:
aic7xx=tag_info:{{0,0,0,0,}}
This enabled the default tagged command queing on the first device, on the first 4 scsi ids.
options aic7xxxaic7xxx=tag_info:{{24.24.24.24.24.24}}in /etc/modules.conf will set the TCQ depth to 24
You probably want to check the driver documentation for your particular scsi modules for more info.
Making sure the cards are running in full duplex mode is also very often critical to benchmark performance. Depending on the networking hardware used, some of the cards may not autosense properly and may not run full duplex by default.
Many cards include module options that can be used to force the cards into full duplex mode. Some examples for common cards include
alias eth0 eepro100 options eepro100 full_duplex=1 alias eth1 tulip options tulip full_duplex=1
Though full duplex gives the best overall performance, I've seen some circumstances where setting the cards to half duplex will actually increase thoughput, particulary in cases where the data flow is heavily one sided.
If you think your in a situation where that may help, I would suggest trying it and benchmarking it.
In order to optimize TCP performance for this situation, I would suggest tuning the following parameters.
echo 1024 65000 > /proc/sys/net/ipv4/ip_local_port_rangeAllows more local ports to be available. Generally not a issue, but in a benchmarking scenario you often need more ports available. A common example is clients running `ab` or `http_load` or similar software.
In the case of firewalls, or other servers doing NAT or masquerading, you may not be able to use the full port range this way, because of the need for high ports for use in NAT.
Increasing the amount of memory associated with socket buffers can often improve performance. Things like NFS in particular, or apache setups with large buffer configured can benefit from this.
echo 262143 > /proc/sys/net/core/rmem_max echo 262143 > /proc/sys/net/core/rmem_defaultThis will increase the amount of memory available for socket input queues. The "wmem_*" values do the same for output queues.
Note: With 2.4.x kernels, these values are supposed to "autotune" fairly well, and some people suggest just instead changing the values in:
/proc/sys/net/ipv4/tcp_rmem /proc/sys/net/ipv4/tcp_wmemThere are three values here, "min default max".
These reduce the amount of work the TCP stack has to do, so is often helpful in this situation.
echo 0 > /proc/sys/net/ipv4/tcp_sack echo 0 > /proc/sys/net/ipv4/tcp_timestampsSee also
But the basic tuning steps include:
Try using NFSv3 if you are currently using NFSv2. There can be very significant performance increases with this change.
Increasing the read write block size. This is done with the rsize and wsize mount options. They need to the mount options used by the NFS clients. Values of 4096 and 8192 reportedly increase performance alot. But see the notes in the HOWTO about experimenting and measuring the performance implications. The limits on these are 8192 for NFSv2 and 32768 for NFSv3
Another approach is to increase the number of nfsd threads running. This is normally controlled by the nfsd init script. On Red Hat Linux machines, the value "RPCNFSDCOUNT" in the nfs init script controls this value. The best way to determine if you need this is to experiment. The HOWTO mentions a way to determin thread usage, but that doesnt seem supported in all kernels.
Another good tool for getting some handle on NFS server performance is `nfsstat`. This util reads the info in /proc/net/rpc/nfs[d] and displays it in a somewhat readable format. Some info intended for tuning Solaris, but useful for it's description of the
See also the
documentation.Bumping the number of available httpd processes
Apache sets a maximum number of possible processes at compile time. It is set to 256 by default, but in this kind of scenario, can often be exceeded.
To change this, you will need to chage the hardcoded limit in the apache source code, and recompile it. An example of the change is below:
--- apache_1.3.6/src/include/httpd.h.prezab Fri Aug 6 20:11:14 1999 +++ apache_1.3.6/src/include/httpd.h Fri Aug 6 20:12:50 1999 @@ -306,7 +306,7 @@ * the overhead. */ #ifndef HARD_SERVER_LIMIT -#define HARD_SERVER_LIMIT 256 +#define HARD_SERVER_LIMIT 4000 #endif /*
To make useage of this many apache's however, you will also need to boost the number of processes support, at least for 2.2 kernels. See the for info on increasing this.
The biggest scalability problem with apache, 1.3.x versions at least, is it's model of using one process per connection. In cases where there large amounts of concurent connections, this can require a large amount resources. These resources can include RAM, schedular slots, ability to grab locks, database connections, file descriptors, and others.In cases where each connection takes a long time to complete, this is only compunded. Connections can be slow to complete because of large amounts of cpu or i/o usage in dynamic apps, large files being transfered, or just talking to clients on slow links.
There are several strategies to mitigate this. The basic idea being to free up heavyweight apache processes from having to handle slow to complete connections.
Static Content Servers
For purely static content, some of the other smaller more lightweight web servers can offer very good performance. They arent nearly as powerful or as flexible as apache, but for very specific performance crucial tasks, they can be a big win.
If you need even more ExtremeWebServerPerformance, you probabaly want to take a look at TUX, written by . This is the current world record holder for . It probabaly owns the right to be called the worlds fastest web server.
The easiest approache is probabaly to use mod_proxy and the "ProxyPass" directive to pass content to another server. mod_proxy supports a degree of caching that can offer a significant performance boost. But another advantage is that since the proxy server and the web server are likely to have a very fast interconnect, the web server can quickly serve up large content, freeing up a apache process, why the proxy slowly feeds out the content to clients. This can be further enhanced by increasing the amount of socket buffer memory thats for the kernel. See the for info on this.
proxy links
ListenBacklog
The apache ListenBacklog paramater lets you specify what backlog paramater is set to listen(). By default on linux, this can be as high as 128.
Increasing this allows a limited number of httpd's to handle a burst of attempted connections.
There are some experimental patches from SGI that accelerate apache. More info at:
I havent really had a chance to test the SGI patches yet, but I've been told they are pretty effective.
The first one is to rebuild it with mmap support. In cases where you are serving up a large amount of small files, this seems to be particularly useful. You just need to add a "--with-mmap" to the configure line.
You also want to make sure the following options are enabled in the /etc/smb.conf file:
read raw = no read prediction = true level2 oplocks = true
One of the better resources for tuning samba is the "Using Samba" book from O'reily. The
is available online.But aside from that, a good set of benchmarking utilities are often very helpful in doing system tuning work. It is impossible to duplicate "real world" situations, but that isnt really the goal of a good benchmark. A good benchmark typically tries to measure the performance of one particular thing very accurately. If you understand what the benchmarks are doing, they can be very useful tools.
Some of the common and useful benchmarks include:
Check for more info on Bonnie. There is also a somwhat newer version of Bonnie called that fixes a few bugs, and includes a couple of extra tests.
Dbench is available at
http_load is available from
dkftpbench is available from
The .
dt does a lot. disk io, process creation, async io, etc.
dt is available at
Info:
Download:
Info provided by Bill Hilf.
Info:
Download:
Info provided by Bill Hilf.
Info:
Download:
Info provided by Bill Hilf.
Heres a sample vmstat output on a lightly used desktop:
procs memory swap io system cpu r b w swpd free buff cache si so bi bo in cs us sy id 1 0 0 5416 2200 1856 34612 0 1 2 1 140 194 2 1 97
And heres some sample output on a heavily used server:
procs memory swap io system cpu r b w swpd free buff cache si so bi bo in cs us sy id 16 0 0 2360 264400 96672 9400 0 0 0 1 53 24 3 1 96 24 0 0 2360 257284 96672 9400 0 0 0 6 3063 17713 64 36 0 15 0 0 2360 250024 96672 9400 0 0 0 3 3039 16811 66 34 0
The interesting numbers here are the first one, this is the number of the process that are on the run queue. This value shows how many process are ready to be executed, but can not be ran at the moment because other process need to finish. For lightly loaded systems, this is almost never above 1-3, and numbers consistently higher than 10 indicate the machine is getting pounded.
Other interseting values include the "system" numbers for in and cs. The in value is the number of interupts per second a system is getting. A system doing a lot of network or disk I/o will have high values here, as interupts are generated everytime something is read or written to the disk or network.
The cs value is the number of context switches per second. A context switch is when the kernel has to take off of the executable code for a program out of memory, and switch in another. It's actually _way_ more complicated than that, but thats the basic idea. Lots of context swithes are bad, since it takes some fairly large number of cycles to performa a context swithch, so if you are doing lots of them, you are spending all your time chaining jobs and not actually doing any work. I think we can all understand that concept.
netstat
One of the more useful options is:
netstat -pa
The `-p` options tells it to try to determine what program has the socket open, which is often very useful info. For example, someone nmap's their system and wants to know what is using port 666 for example. Running netstat -pa will show you its satand running on that tcp port.
One of the most twisted, but useful invocations is:
netstat -a -n|grep -E "^(tcp)"| cut -c 68-|sort|uniq -c|sort -n
This will show you a sorted list of how many sockets are in each connection state. For example:
9 LISTEN
21 ESTABLISHED
ps
ps -eo pid,%cpu,vsz,args,wchan
Shows every process, their pid, % of cpu, memory size, name, and what syscall they are currently executing. Nifty.
Pmap - - Process Memory Usage
The command pmap report memory map of a process. Use this command to find out causes of memory bottlenecks.
# pmap -d PID
Iptraf - Real-time Network Statistics
Features of Iptraf are
Network traffic statistics by TCP connection
IP traffic statistics by network interface
Network traffic statistics by protocol
Network traffic statistics by TCP/UDP port and by packet size
Network traffic statistics by Layer2 address
You've just had your first cup of coffee and have received that dreaded phone call. The system is slow. What are you going to do? This article will discuss performance bottlenecks and optimization in Red Hat Enterprise Linux (RHEL5).
Before getting into any monitoring or tuning specifics, you should always use some kind of tuning methodology. This is one which I've used successfully through the years:
1. Baseline – The first thing you must do is establish a baseline, which is a snapshot of how the system appears when it's performing well. This baseline should not only compile data, but also document your system's configuration (RAM, CPU and I/O). This is necessary because you need to know what a well-performing system looks like prior to fixing it.
2. Stress testing and monitoring – This is the part where you monitor and stress your systems at peak workloads. It's the monitoring which is key here – as you cannot effectively tune anything without some historic trending data.
3. Bottleneck identification – This is where you come up with the diagnosis for what is ailing your system. The primary objective of section 2 is to determine the bottleneck. I like to use several monitoring tools here. This allows me to cross-reference my data for accuracy.
4. Tune – Only after you've identified the bottleneck can you tune it.
5. Repeat – Once you've tuned it, you can start the cycle again – but this time start from step 2 (monitoring) – as you already have your baseline.
It's important to note that you should only make one change at a time. Otherwise, you'll never know exactly what impacted any changes which might have occurred. It is only by repeating your tests and consistently monitoring your systems that you can determine if your tuning is making an impact.
RHEL monitoring tools
Before we can begin to improve the performance of our system, we need to use the monitoring tools available to us to baseline. Here are some monitoring tools you should consider using:
This tool (made available in RHEL5) utilizes the processor to retrieve kernel system information about system executables. It allows one to collect samples of performance data every time a counter detects an interrupt. I like the tool also because it carries little overhead – which is very important because you don't want monitoring tools to be causing system bottlenecks. One important limitation is that the tool is very much geared towards finding problems with CPU limited processes. It does not identify processes which are sleeping or waiting on I/O.
The steps used to start up Oprofile include setting up the profiler, starting it and then dumping the data.
First we'll set up the profile. This option assumes that one wants to monitor the kernel.
# opcontrol --setup –vmlinux=/usr/lib/debug/lib/modules/'uname -r'/vmlinux
Then we can start it up.
# opcontrol --start
Finally, we'll dump the data.
# opcontrol --stop/--shutdown/--dump
This tool (introduced in RHEL5) collects data by analyzing the running kernel. It really helps one come up with a correct diagnosis of a performance problem and is tailor-made for developers. SystemTap eliminates the need for the developer to go through the recompile and reinstallation process to collect data.
This is another tool which was introduced by Red Hat in RHEL5. What does it do for you? It allows both developers and system administrators to monitor running processes and threads. Frysk differs from Oprofile in that it uses 100% reliable information (similar to SystemTap) - not just a sampling of data. It also runs in user mode and does not require kernel modules or elevated privileges. Allowing one to stop or start running threads or processes is also a very useful feature.
Some more general Linux tools include and . While these are considered more basic, often I find them much more useful than more complex tools. Certainly they are easier to use and can help provide information in a much quicker fashion.
Top provides a quick snapshot of what is going on in your system – in a friendly character-based display. 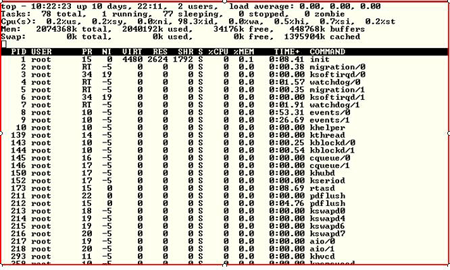
It also provides information on CPU, Memory and Swap Space.
Let's look at vmstat – one of the oldest but more important Unix/Linux tools ever created. Vmstat allows one to get a valuable snapshot of process, memory, sway I/O and overall CPU utilization.
Now let's define some of the fields:
Memory
swpd – The amount of virtual memory
free – The amount of free memory
buff – Amount of memory used for buffers
cache – Amount of memory used as page cache
Process
r – number of run-able processes
b – number or processes sleeping. Make sure this number does not exceed the amount of run-able processes, because when this condition occurs it usually signifies that there are performance problems.
Swap
si – the amount of memory swapped in from disk
so – the amount of memory swapped out.
This is another important field you should be monitoring – if you are swapping out data, you will likely be having performance problems with virtual memory.
CPU
us – The % of time spent in user-level code.
It is preferable for you to have processes which spend more time in user code rather than system code. Time spent in system level code usually means that the process is tied up in the kernel rather than processing real data.
sy – the time spent in system level code
id – the amount of time the CPU is idle wa – The amount of time the system is spending waiting for I/O.
If your system is waiting on I/O – everything tends to come to a halt. I start to get worried when this is > 10.
There is also:
Free – This tool provides memory information, giving you data around the total amount of free and used physical and swap memory.
Now that we've analyzed our systems – lets look at what we can do to optimize and tune our systems.
CPU Overhead – Shutting Running Processes
Linux starts up all sorts of processes which are usually not required. This includes processes such as autofs, cups, xfs, nfslock and sendmail. As a general rule, shut down anything that isn't explicitly required. How do you do this? The best method is to use the chkconfig command.
Here's how we can shut these processes down. [root ((Content component not found.)) _29_140_234 ~]# chkconfig --del xfs
You can also use the GUI - /usr/bin/system-config-services to shut down daemon process.
Tuning the kernel
To tune your kernel for optimal performance, start with:
sysctl – This is the command we use for changing kernel parameters. The parameters themselves are found in /proc/sys/kernel
Let's change some of the parameters. We'll start with the msgmax parameter. This parameter specifies the maximum allowable size of a single message in an IPC message queue. Let's view how it currently looks.
[root ((Content component not found.)) _29_139_52 ~]# sysctl kernel.msgmax
kernel.msgmax = 65536
[root ((Content component not found.)) _29_139_52 ~]#
There are three ways to make these kinds of kernel changes. One way is to change this using the echo command.
[root ((Content component not found.)) _29_139_52 ~]# echo 131072 >/proc/sys/kernel/msgmax
[root ((Content component not found.)) _29_139_52 ~]# sysctl kernel.msgmax
kernel.msgmax = 131072
[root ((Content component not found.)) _29_139_52 ~]#
Another parameter that is changed quite frequently is SHMMAX, which is used to define the maximum size (in bytes) for a shared memory segment. In Oracle this should be set large enough for the largest SGA size. Let's look at the default parameter:
# sysctl kernel.shmmax
kernel.shmmax = 268435456
This is in bytes – which translates to 256 MG. Let's change this to 512 MG, using the -w flag.
[root ((Content component not found.)) _29_139_52 ~]# sysctl -w kernel.shmmax=5368709132
kernel.shmmax = 5368709132
[root ((Content component not found.)) _29_139_52 ~]#
The final method for making changes is to use a text editor such as vi – directly editing the /etc/sysctl.conf file to manually make our changes.
To allow the parameter to take affect dynamically without a reboot, issue the sysctl command with the -p parameter.
Obviously, there is more to performance tuning and optimization than we can discuss in the context of this small article – entire books have been written on Linux performance tuning. For those of you first getting your hands dirty with tuning, I suggest you tread lightly and spend time working on development, test and/or sandbox environments prior to deploying any changes into production. Ensure that you monitor the effects of any changes that you make immediately; it's imperative to know the effect of your change. Be prepared for the possibility that fixing your bottleneck has created another one. This is actually not a bad thing in itself, as long as your overall performance has improved and you understand fully what is happening.
Performance monitoring and tuning is a dynamic process which does not stop after you have fixed a problem. All you've done is established a new baseline. Don't rest on your laurels, and understand that performance monitoring must be a routine part of your role as a systems administrator.
About the author: Ken Milberg is a systems consultant with two decades of experience working with Unix and Linux systems. He is a SearchEnterpriseLinux.com Ask the Experts advisor and columnist.
