【IT168 专稿】在前面一系列的列式数据库评测文章中,我们介绍了6种列式数据库。从本文开始,我们将评测传统的行存储数据库,评测的重点仍然是tpc-h分析型查询,主要检验各种数据库在数据仓库方面的能力。我们从市场占有率最高的商业数据库Oracle开始。
一、数据库安装
Oracle在其上提供了Oracle 10g R2、11g R1、11g R2等各种版本软件的下载,这里也提供了文档在线浏览和下载,这为用户试用带来了方便,但值得一提的,虽然软件本身没有对功能和试用期限进行限制,但在用户协议中对用户的权利和义务有明确的约定,用户必须接受协议才能试用。由于Oracle已经宣布Oracle 10g R2、11g R1产品生命周期的结束日期,此后不再提供技术支持服务。通过文档我们了解到,企业版比标准版具有更多的高级功能,比如:分区、并行查询等,也具有更大的扩展性。因此我们采用11g R2企业版来做评测,以最大限度地了解这个产品的全部功能。在上述网站注册一个免费用户就可以下载安装文件。
Oracle 11.2支持的平台有windows 32位/64位、linux、Solaris、HP-UX 、AIX等10种。本次测试基于Intel Xeon 7550*8的PC上用VMWare VSphere 4.1管理的虚拟机,虚拟机的逻辑个数是8, 100GB,存储为8个300GB SAS本地磁盘,采用一块512M缓存,按RAID5方式组成。采用和RHEL 5相同的核心级别的RedFlag Asian Linux Sever 3.0 x64。因此选用的安装文件是64位x86 Linux版本,和,2个文件合计大约2.2G,必须都下载,然后解压缩到同一个目录才能执行安装。Oracle的安装在各种数据库当中算是比较复杂的,但由于Oracle的市场地位和流行程度,专门介绍安装的文档在互联网上也是不计其数。因此本文不准备详细介绍每个步骤,只说明一些初次使用者易错的关键步骤。更详细的步骤,参考。
在Linux环境进行Oracle安装的关键步骤有下面几步:
1、先决条件检查,检查、交换文件和临时文件目录大小以及版本是否符合Oracle安装的最低要求。
![]()
[root@redflag11012501 ~]# grep MemTotal /proc/meminfo
![]()
MemTotal:
103140528 kB
![]()
[root@redflag11012501 ~]# grep SwapTotal /proc/meminfo
![]()
SwapTotal:
5996536 kB
![]()
[root@redflag11012501 ~]# free
![]()
total used free shared buffers cached
![]()
Mem:
103140528 5758696 97381832 0 138936 5261496![]()
-/+ buffers/cache:
358264 102782264![]()
Swap:
5996536 0 5996536![]()
[root@redflag11012501 ~]# df -h /dev/shm/
![]()
文件系统 容量 已用 可用 已用% 挂载点
![]()
tmpfs 50G
0 50G
0% /dev/shm
![]()
[root@redflag11012501 ~]# uname -m
![]()
x86_64
![]()
[root@redflag11012501 ~]# df -h /tmp
![]()
文件系统 容量 已用 可用 已用% 挂载点
![]()
/dev/mapper/VolGroup00-LogVol00
![]()
24G
5.4G 17G
25% /
![]()
[root@redflag11012501 ~]# df -h
![]()
文件系统 容量 已用 可用 已用% 挂载点
![]()
/dev/mapper/VolGroup00-LogVol00
![]()
24G
5.4G 17G
25% /
![]()
/dev/sda1 99M 13M 82M
14% /boot
![]()
tmpfs 50G
0 50G
0% /dev/shm
![]()
/dev/mapper/vg0-datalv
![]()
739G
4.9G 696G
1% /user1
![]()
[root@redflag11012501 ~]# cat /proc/version
![]()
Linux version
2.6.
18-
194.1.AXS3 (packager@asianux.com) (gcc version
4.1.
2 20080704 (Asianux
3.0 4.1.
2-
48)) #
1 SMP Fri May
7 10:
03:
53 CST
2010![]()
[root@redflag11012501 ~]# uname -r
![]() 2.6
2.6.
18-
194.1.AXS3
2、创建操作系统oracle用户和组。并给oracle用户设置口令。
![]()
[root@redflag11012501 ~]# /usr/sbin/groupadd oinstall
![]()
[root@redflag11012501 ~]# /usr/sbin/groupadd -g
502 dba
![]()
[root@redflag11012501 ~]# /usr/sbin/groupadd -g
503 oper
![]()
[root@redflag11012501 ~]# /usr/sbin/groupadd -g
504 asmadmin
![]()
[root@redflag11012501 ~]# /usr/sbin/groupadd -g
506 asmdba
![]()
[root@redflag11012501 ~]# /usr/sbin/groupadd -g
505 asmoper
![]()
[root@redflag11012501 ~]# /usr/sbin/useradd -u
502 -g oinstall -G dba,asmdba,oper oracle
![]()
[root@redflag11012501 ~]# passwd oracle
![]()
Changing password
for user oracle.
![]() New
New UNIX password:
![]()
BAD PASSWORD: it
is based
on a dictionary word
![]()
Retype
new UNIX password:
![]()
passwd: all authentication tokens updated successfully.
3、设定oracle用户的资源限制。S表示软限制、H表示硬限制。
![]()
[root@redflag11012501 ~]# su - oracle
![]()
[oracle@redflag11012501 ~]$ ulimit -Sn
2048![]()
[oracle@redflag11012501 ~]$ ulimit -Hn
65536![]()
[oracle@redflag11012501 ~]$ ulimit -Su
16384![]()
[oracle@redflag11012501 ~]$ ulimit -Hu
16384![]()
[oracle@redflag11012501 ~]$ ulimit -Ss
10240![]()
[oracle@redflag11012501 ~]$ ulimit -Hs unlimited
4、用root用户设定系统核心参数。从11.2开始,Oracle安装文件提供了自动修改某些参数的功能,因此这一步变得可选。可以查看原始参数的值。
![]()
[root@redflag11012501 ~]# /sbin/sysctl -a | grep sem
![]()
kernel.sem =
256 32000 100 142![]()
[root@redflag11012501 ~]# /sbin/sysctl -a | grep shm
![]()
vm.hugetlb_shm_group =
0![]()
kernel.shmmni =
4096![]()
kernel.shmall =
4294967296![]()
kernel.shmmax =
68719476736![]()
[root@redflag11012501 ~]# /sbin/sysctl -a | grep file-max
![]()
fs.file-max =
131072 5、创建安装二进制文件存放目录和数据库文件存放目录等,并改变属主为oracle。
![]()
[root@redflag11012501 ~]# mkdir -p /user1/app/oracle
![]()
[root@redflag11012501 ~]# chown -R oracle:oinstall /user1/app/oracle
![]()
[root@redflag11012501 ~]# chmod -R
775 /user1/app/oracle
![]()
[root@redflag11012501 ~]# mkdir -p /user1/app/oradata
![]()
[root@redflag11012501 ~]# chown -R oracle:oinstall /user1/app/oradata
![]()
[root@redflag11012501 ~]# chmod -R
775 /user1/app/oradata
![]()
[root@redflag11012501 ~]# mkdir -p /user1/app/recovery_area
![]()
[root@redflag11012501 ~]# chown -R oracle:oinstall /user1/app/recovery_area
![]()
[root@redflag11012501 ~]# chmod -R
775 /user1/app/recovery_area
6、用x图形界面工具登录。在图形终端中查看display的端口,并据此设定oracle用户DISPLAY环境变量,运行安装程序runInstaller,按界面提示操作。
![]()
[root@redflag11012501 ~]# xdpyinfo
![]()
name of display:
10.4.
105.241:
1.0![]()
version number:
11.0![]()
vendor
string: NetSarang Computer, Inc.
![]()
vendor release number:
1391![]()
...
![]()
[root@redflag11012501 ~]#
![]()
[root@redflag11012501 ~]# su - oracle
![]()
[oracle@redflag11012501 ~]$ export DISPLAY=
10.4.
105.241:
1.0![]()
[oracle@redflag11012501 ~]$ cd /user1/app/oradata/database
![]()
[oracle@redflag11012501 database]$ ./runInstaller
7、安装程序检查后自动生成了修改核心参数的脚本,需要用root用户执行。
![]()
[root@redflag11012501 ~]# /tmp/CVU_11.
2.0.
2.0_oracle/runfixup.sh
![]()
/usr/bin/id
![]()
Response file being used
is :/tmp/CVU_11.
2.0.
2.0_oracle/fixup.response
![]()
Enable file being used
is :/tmp/CVU_11.
2.0.
2.0_oracle/fixup.enable
![]() Log
Log file location: /tmp/CVU_11.
2.0.
2.0_oracle/orarun.log
![]()
Setting Kernel Parameters...
![]()
fs.file-max =
131072![]()
fs.file-max =
6815744![]()
net.ipv4.ip_local_port_range =
9000 65500![]()
net.core.rmem_max=
262144![]()
net.core.rmem_max =
4194304![]()
net.core.wmem_max=
262144![]()
net.core.wmem_max =
1048576![]()
fs.aio-max-nr =
1048576 安装注意事项:
Oracle用一个安装包包括了标准版和企业版的功能,只要在安装类型选择企业版即可。
安装完数据库软件后,执行dbca创建数据库,注意选择类型为一般用途,SGA一般用默认的物理内存的40%即可,不必设得过大,因为操作系统需要部分内存作文件缓存,如果Oracle占用过大,就会影响操作系统的操作,不但不能提高性能,反而会降低性能。用netca创建监听和服务。就可以进行一般的测试了。
二、TPC-H基准测试介绍
1、背景
TPC即美国事务处理效能委员会(Transaction Processing Performance Council),是一家非盈利机构,也是国际上最具权威性的高端产品效能评测组织之一,被称为 “高端计算机产品竞技的国际俱乐部”。目前在国际上几乎所有 IT界知名厂商都是其会员。负责定义事务处理与数据库性能基准测试,并依据这些基准测试项目发布客观性能数据。TPC基准测试有极为严格的运行要求,并且在独立审计机构监督下进行。
TPC-H(商业智能计算测试)是TPC的重要测试标准之一,主要用来模拟真实商业的应用环境。商业智能计算测试是对现实中商用计算需求的全面模拟。它包括模拟真实商业交易数据库的动态查询,以及作为决策支持与数据库应用系统的参考。可以全方位评测系统的整体商业计算综合能力,对厂商的要求更高,同时也具有普遍的商业实用意义。
TPC-H 基准测试是由 TPC-D发展而来的。TPC-H 用 3NF 实现了一个数据仓库,共包含 8 个基本关系/表,其中表REGION和表NATION的记录数是固定的(分别为5和25),其它6个表的记录数,则随所设定的参数SF而有所不同,其数据量可以设定从 1GB~3TB 不等。有8个级别供用户选择。测试时,将22个复杂查询(SELECT)随机组成查询流,2个更新(带有INSERT和DELETE的程序段)操作组成一个更新流,查询流和更新流并发执行数据库访问,查询流数目随数据量增加而增加。TPC-H 基准测试包括 22 个查询(Q1~Q22),其主要评价指标是各个查询的响应时间,即从提交查询到结果返回所需时间.TPC-H 基准测试的度量单位是每小时执行的查询数( QphH@size),其中 H 表示每小时系统执行复杂查询的平均次数,size 表示数据库规模的大小,它能够反映出系统在处理查询时的能力.TPC-H 是根据真实的生产运行环境来建模的,这使得它可以评估一些其他测试所不能评估的关键性能参数,满足了数据仓库领域的测试需求。
在我们的实验中,为了简化操作,只测试查询,并设定的SF的值为10。表示数据量为10GB级别。8张表的E/R图(来自tpc官方文档)如下:
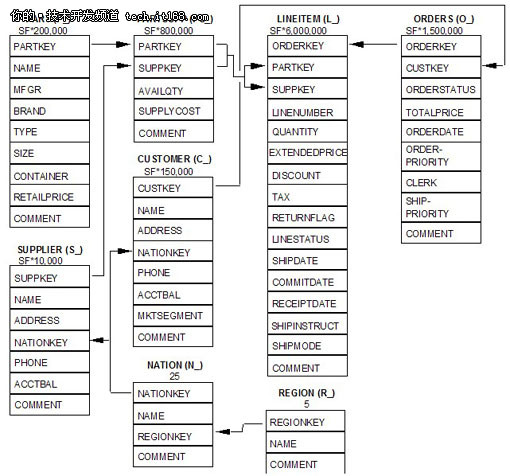
需要说明的是,虽然每个表都有唯一键,表之间有引用关系,TPC-H并不要求测试表定义中必须包含主键和外键定义。而允许测试的数据库自行决定。
TPC-H用来执行的查询具有下列特征:
1、具有高度复杂性;2、使用各种访问;3、是特定的;4、检查可用数据的大多数;5、各不相同;6、每次查询的参数可变。
这些查询为下列商业分析提供了答案:
价格和推广、供应和需求管理、利润和收入管理、顾客满意度研究、市场份额研究、发货管理。
因此TPC-H的22个查询涵盖了商业分析的诸方面,具有普遍性和实用性。从查询SQL语句的实际内容来看,包括符合SQL 92标准的表连接、子查询,IN、EXISTS操作,HAVING操作,GROUP BY,UNION,日期操作,也是全面地检验了数据库应付各种语句的能力。
注意:具体查询sql语句必须通过dbgen工具产生,除了限定输出记录行数的子句,不允许人工修改写法。
2、测试数据和查询语句的产生步骤
将从tpc网站下载的源代码包解压缩,从模板复制一份makefile,然后修改其中和数据库类型、操作系统类型相关的内容,执行make编译。
![]()
[root@redflag11012501 tmp]# su - oracle
![]()
[oracle@redflag11012501 ~]$ cd /user1/app/oradata/tmp
![]()
[oracle@redflag11012501 tmp]$ unzip /user1/app/tpch_2_13_0.zip
![]()
Archive: /user1/app/tpch_2_13_0.zip
![]()
inflating: build.c
![]()
inflating: driver.c
![]()
inflating: bm_utils.c
![]()
inflating:
rnd.c
![]()
inflating: print.c
![]()
inflating: load_stub.c
![]()
inflating: bcd2.c
![]()
inflating: speed_seed.c
![]()
inflating: text.c
![]()
....
![]()
![]()
![]()
[oracle@redflag11012501 tmp]$ cp makefile.suite makefile
![]()
[oracle@redflag11012501 tmp]$ vi makefile
![]()
...
![]()
################
![]()
## CHANGE NAME OF ANSI COMPILER HERE
![]()
################
![]()
CC = gcc
![]()
# Current values
for DATABASE are: INFORMIX, DB2, TDAT (Teradata)
![]()
# SQLSERVER, SYBASE, ORACLE
![]()
# Current values
for MACHINE are: ATT, DOS, HP, IBM, ICL, MVS,
![]()
# SGI, SUN, U2200, VMS, LINUX, WIN32
![]()
# Current values
for WORKLOAD are: TPCH
![]()
DATABASE= ORACLE
![]()
MACHINE = LINUX
![]()
WORKLOAD = TPCH
![]()
...
![]()
[oracle@redflag11012501 tmp]$ make
![]()
chmod
755 update_release.sh
![]()
./update_release.sh
2 13 0![]()
gcc -g -DDBNAME=\
"dss\" -DLINUX -DORACLE -DTPCH -DRNG_TEST -D_FILE_OFFSET_BITS=
64 -c -o build.o build.c
![]()
…
![]()
gcc -g -DDBNAME=\
"dss\" -DLINUX -DORACLE -DTPCH -DRNG_TEST -D_FILE_OFFSET_BITS=
64 -O -o dbgen build.o driver.o bm_utils.o
rnd.o print.o load_stub.o bcd2.o speed_seed.o text.o permute.o rng64.o -lm
![]()
gcc -g -DDBNAME=\
"dss\" -DLINUX -DORACLE -DTPCH -DRNG_TEST -D_FILE_OFFSET_BITS=
64 -c -o qgen.o qgen.c
![]()
gcc -g -DDBNAME=\
"dss\" -DLINUX -DORACLE -DTPCH -DRNG_TEST -D_FILE_OFFSET_BITS=
64 -c -o varsub.o varsub.c
![]()
gcc -g -DDBNAME=\
"dss\" -DLINUX -DORACLE -DTPCH -DRNG_TEST -D_FILE_OFFSET_BITS=
64 -O -o qgen build.o bm_utils.o qgen.o
rnd.o varsub.o text.o bcd2.o permute.o speed_seed.o rng64.o -lm
![]()
--编译完成的可执行文件
![]()
[oracle@redflag11012501 tmp]$ ls *gen
![]()
dbgen qgen
用编译好的dbgen产生测试数据,qgen产生查询语句。
![]()
--生成1GB的测试数据
![]()
[oracle@redflag11012501 tmp]$ ./dbgen -s
1![]()
TPC-H Population Generator (Version
2.13.
0)
![]()
Copyright Transaction Processing Performance Council
1994 -
2010![]() Do
Do you want
to overwrite ./supplier.tbl ? [Y/N]: Y
![]() Do
Do you want
to overwrite ./customer.tbl ? [Y/N]: Y
![]()
[oracle@redflag11012501 tmp]$
![]()
![]()
![]()
[oracle@redflag11012501 tmp]$ ls -l *tbl
![]()
-rw-r--r--
1 oracle oinstall
24346144 01-
30 11:
29 customer.tbl
![]()
-rw-r--r--
1 oracle oinstall
759863287 01-
30 11:
29 lineitem.tbl
![]()
-rw-r--r--
1 oracle oinstall
2224 01-
30 11:
29 nation.tbl
![]()
-rw-r--r--
1 oracle oinstall
171952161 01-
30 11:
29 orders.tbl
![]()
-rw-r--r--
1 oracle oinstall
118984616 01-
30 11:
29 partsupp.tbl
![]()
-rw-r--r--
1 oracle oinstall
24134899 01-
30 11:
29 part.tbl
![]()
-rw-r--r--
1 oracle oinstall
389 01-
30 11:
29 region.tbl
![]()
-rw-r--r--
1 oracle oinstall
1409184 01-
30 11:
29 supplier.tbl
![]()
--qgen需要在queries目录和dists.dss文件中读取模板
![]()
[oracle@redflag11012501 tmp]$ cd queries
![]()
[oracle@redflag11012501 queries]$ ../qgen
![]()
Open failed
for ./dists.dss at bm_utils.c:
308![]()
[oracle@redflag11012501 queries]$ cp ../dists.dss .
![]()
[oracle@redflag11012501 queries]$ ../qgen
![]()
-- using
1296360498 as a seed
to the RNG
![]()
![]()
![]() select
select![]()
l_returnflag,
![]()
l_linestatus,
![]()
sum(l_quantity)
as sum_qty,
![]()
sum(l_extendedprice)
as sum_base_price,
![]()
sum(l_extendedprice * (
1 - l_discount))
as sum_disc_price,
![]()
sum(l_extendedprice * (
1 - l_discount) * (
1 + l_tax))
as sum_charge,
![]()
avg(l_quantity)
as avg_qty,
![]()
avg(l_extendedprice)
as avg_price,
![]()
avg(l_discount)
as avg_disc,
![]()
count(*)
as count_order
![]()
from
![]()
lineitem
![]()
where
![]()
l_shipdate <=
date '1998-12-01' - interval '93' day (3)
![]()
group by
![]()
l_returnflag,
![]()
l_linestatus
![]()
order by
![]()
l_returnflag,
![]()
l_linestatus;
![]()
where rownum <= -
1;
从上面的输出结果可以看出,虽然指定了数据库参数,qgen产生的查询语句仍然不符合oracle的语法规则。只是添加了一个where rownum<=条件,仍然需要人工编辑,在select前面增加select * from,然后再将原始的查询作为子查询用()括起来,最后再加上where rownum条件,注意将rownum<=-1中的-1改为一个较大的正整数。另外3处需要针对Oracle语法修改的地方是:将substring函数修改为substr函数,将表别名前面的as关键字去掉,将子查询构成的别名后的列名移动到子查询的select子句。
我们在修改完成的包含22个查询语句的sql脚本前端和末尾加上如下参数,就可以方便地进行多次测试。
![]() set
set timi
on lines
140 pages
5000 trimspool
on termout off
![]() set
set autot off
![]()
spool test.log
![]()
…
![]()
pool off
![]() exit
exit 如果是需要强制并行查询,则采用下面的设置。无论原始表是否开启了并行,设定了什么并行度,查询优化器都采用并行查询。要查看各查询的时间,在linux下可以用grep命令:
![]() set
set timi
on lines
140 pages
5000 trimspool
on termout off
![]()
alter session force parallel query;
![]()
…
![]()
[oracle@redflag11012602 tpch]$ cat test.log|grep
"Elapsed:"![]()
Elapsed:
00:
01:
06.24![]()
Elapsed:
00:
00:
03.83![]()
…
![]()
Elapsed:
00:
00:
19.08![]()
Elapsed:
00:
00:
17.28![]()
Elapsed:
00:
00:
06.06 在Windows上可以用find命令完成同样的任务,如: find "Elapsed:" test.log。
三、数据加载和查询性能
本文不准备全面介绍Oracle的基本功能和特有功能,那需要一本书的篇幅,市面上也有很多书可供参考。这里只对分析型数据处理相关的功能做简要介绍和评测。
下面沿用TPC-H scale为10的大约10G字节数据来进行较大数据量的测试,先进行数据加载测试,测试前,先创建专用于测试的表空间tpch_ts,由于我们要测试的数据量大约10GB,考虑到PCT_FREE和其他开销,把表空间的大小定为20GB。然后创建tpch用户,将tpch用户的默认表空间设为tpch_ts,再利用tpch源代码包中的dss.ddl文件创建需要测试的8个表。另外,dss.ri文件中包含了表的主键和外键约束,为了提高数据加载速度,我们不执行它。
![]()
SQL> conn /
as sysdba
![]()
Connected.
![]()
SQL> create tablespace tpch_ts datafile
'/user1/tpch/tpch.dbf'size 20000m nologging;
![]()
![]()
Tablespace created.
![]()
![]()
Elapsed:
00:
01:
19.53![]()
SQL> create user tpch identified by tpch temporary tablespace temp default tablespace tpch_ts ;
![]()
![]()
User created.
![]()
![]()
Elapsed:
00:
00:
00.13![]()
SQL> grant connect,resource
to tpch;
![]()
![]()
Grant succeeded.
![]()
![]()
Elapsed:
00:
00:
00.02![]()
SQL> grant create any directory
to tpch;
![]()
![]()
Grant succeeded.
![]()
![]()
Elapsed:
00:
00:
00.00 1、sqlldr加载
我们采用Oracle的外部文件加载工具sqlldr来进行。
sqlldr的加载有2种模式,常规路径和直接路径,前者要将数据转化为INSERT语句,通过SGA区加载,后者将数据在内存中组成数据库的数据块格式,直接写入数据文件,避免了语句解释和记录日志的开销,因此在类似数据仓库的大量数据导入时,一般采用直接路径加载。
sqlldr加载需要准备一个控制文件,描述外部文件和数据库中的表的对应关系和一些参数选项,以lineitem表为例:
![]()
--
![]()
-- SQL*UnLoader: Fast Oracle Text Unloader (GZIP), Release
3.0.
1![]()
-- (@) Copyright Lou Fangxin (AnySQL.net)
2004 -
2010, all rights reserved.
![]()
--
![]()
-- CREATE TABLE lineitem (
![]()
-- L_ORDERKEY NUMBER(
38),
![]()
-- L_PARTKEY NUMBER(
38),
![]()
-- L_SUPPKEY NUMBER(
38),
![]()
-- L_LINENUMBER NUMBER(
38),
![]()
-- L_QUANTITY NUMBER(
15,
2),
![]()
-- L_EXTENDEDPRICE NUMBER(
15,
2),
![]()
-- L_DISCOUNT NUMBER(
15,
2),
![]()
-- L_TAX NUMBER(
15,
2),
![]()
-- L_RETURNFLAG VARCHAR2(
1),
![]()
-- L_LINESTATUS VARCHAR2(
1),
![]()
-- L_SHIPDATE
DATE,
![]()
-- L_COMMITDATE
DATE,
![]()
-- L_RECEIPTDATE
DATE,
![]()
-- L_SHIPINSTRUCT VARCHAR2(
25),
![]()
-- L_SHIPMODE VARCHAR2(
10),
![]()
-- L_COMMENT VARCHAR2(
44)
![]()
-- );
![]()
--
![]()
OPTIONS(BINDSIZE=
2097152,READSIZE=
2097152,ERRORS=-
1,ROWS=
50000000)
![]()
LOAD DATA
![]()
INFILE
'lineitem.tbl' "STR X'0a'"
![]()
INSERT INTO TABLE lineitem
![]()
FIELDS TERMINATED BY
'|' TRAILING NULLCOLS
![]()
(
![]() "L_ORDERKEY"
"L_ORDERKEY" CHAR(
40) NULLIF
"L_ORDERKEY"=BLANKS,
![]() "L_PARTKEY"
"L_PARTKEY" CHAR(
40) NULLIF
"L_PARTKEY"=BLANKS,
![]() "L_SUPPKEY"
"L_SUPPKEY" CHAR(
40) NULLIF
"L_SUPPKEY"=BLANKS,
![]() "L_LINENUMBER"
"L_LINENUMBER" CHAR(
40) NULLIF
"L_LINENUMBER"=BLANKS,
![]() "L_QUANTITY"
"L_QUANTITY" CHAR(
18) NULLIF
"L_QUANTITY"=BLANKS,
![]() "L_EXTENDEDPRICE"
"L_EXTENDEDPRICE" CHAR(
18) NULLIF
"L_EXTENDEDPRICE"=BLANKS,
![]() "L_DISCOUNT"
"L_DISCOUNT" CHAR(
18) NULLIF
"L_DISCOUNT"=BLANKS,
![]() "L_TAX"
"L_TAX" CHAR(
18) NULLIF
"L_TAX"=BLANKS,
![]() "L_RETURNFLAG"
"L_RETURNFLAG" CHAR(
1) NULLIF
"L_RETURNFLAG"=BLANKS,
![]() "L_LINESTATUS"
"L_LINESTATUS" CHAR(
1) NULLIF
"L_LINESTATUS"=BLANKS,
![]() "L_SHIPDATE" DATE "YYYY-MM-DD HH24:MI:SS"
"L_SHIPDATE" DATE "YYYY-MM-DD HH24:MI:SS" NULLIF
"L_SHIPDATE"=BLANKS,
![]() "L_COMMITDATE" DATE "YYYY-MM-DD HH24:MI:SS"
"L_COMMITDATE" DATE "YYYY-MM-DD HH24:MI:SS" NULLIF
"L_COMMITDATE"=BLANKS,
![]() "L_RECEIPTDATE" DATE "YYYY-MM-DD HH24:MI:SS"
"L_RECEIPTDATE" DATE "YYYY-MM-DD HH24:MI:SS" NULLIF
"L_RECEIPTDATE"=BLANKS,
![]() "L_SHIPINSTRUCT"
"L_SHIPINSTRUCT" CHAR(
25) NULLIF
"L_SHIPINSTRUCT"=BLANKS,
![]() "L_SHIPMODE"
"L_SHIPMODE" CHAR(
10) NULLIF
"L_SHIPMODE"=BLANKS,
![]() "L_COMMENT"
"L_COMMENT" CHAR(
44) NULLIF
"L_COMMENT"=BLANKS
![]()
)
我们看到,控制文件中设置了外部文件的行分隔符与列分隔符,ROWS参数是常规路径的绑定数组行数,或直接路径每次保存行数。加载方式是INSERT,此外还可以取值APPEND、REPLACE和TRUNCATE。要执行INSERT, 必须保证表为空,否则sqlldr报错,不能继续执行。如果想向表中增加记录,可以指定加载选项为APPEND;为了替换表中已有的数据,可以使用REPLACE或TRUNCATE。REPLACE使用DELETE语句删除全部记录;因此,如果要加载的表中已经包含许多记录,这个操作执行得很慢。TRUNCATE使用 TRUNCATE SQL命令,执行更快,因为它不必物理地删除每一行。但是TRUNCATE 不能回退。要小心地设置这个选项,有时候其他参数也会影响这个选项。NULLIF指定了当外部某列数据为空时的处理方式。
由于数据仓库应用通常数据量较大,将外部文件压缩可以减少存储空间和读文件的I/O,加载时利用命名管道将解压后数据重定向到/user1/daa文件,通过在sqlldr命令行指定data参数可以覆盖控制文件的同名参数。
![]()
[root@redflag11012602 bin]# mkfifo /user1/daa
![]()
[root@redflag11012602 bin]# chmod
666 /user1/daa
![]()
[root@redflag11012602 bin]# su - oracle
![]()
[oracle@redflag11012602 ~]$ gunzip -c /user1/tpch/lineitem.tbl.gz > /user1/daa &
![]()
[
1]
22955![]()
[oracle@redflag11012602 tpch]$
date;sqlldr tpch/tpch control=lineitem_sqlldr2.ctl data=/user1/daa direct=
true log=lineitem_sqlldr2_10.log ;
date![]()
2011年 05月 01日 星期日
08:
34:
45 CST
![]()
![]()
SQL*Loader: Release
11.2.
0.2.
0 - Production
on Sun May
1 08:
34:
45 2011![]()
![]()
Copyright (c)
1982,
2009, Oracle
and/
or its affiliates. All rights reserved.
![]()
![]()
Save data point reached - logical record count
50000000.
![]()
![]()
Load completed - logical record count
59986052.
![]()
[
1]+ Done gunzip -c /user1/tpch/lineitem.tbl.gz > /user1/daa (wd: ~)
![]()
(wd
now: /user1/tpch)
![]()
2011年 05月 01日 星期日
08:
42:
45 CST)
用时8分钟,大约1分钟1GB数据。如果同一个表有多个外部数据文件,那么通过设置Parallel参数=TRUE,采用并行加载,可以提高加载速度。注意Parallel参数只是表示允许多个sqlldr进程同时加载,而不是对当前语句采用并行方式,也就是说,一个sqlldr命令只能串行加载。下面我们用并行方式加载同样的数据,比较加载时间。
首先,将原始数据拆分成4个文件,这里我们采用linux系统提供的split工具,因为总行数大约6千万行,因此规定单个文件行数1500万行。
![]()
[root@redflag11012501 tpch2]# gzip --stdout -d /user1/app/oradata/tpch2/lineitem.tbl.gz >/user1/daa &
![]()
[
1]
28085![]()
![]()
[root@redflag11012501 tpch2]#
date;
split -l15000000 -d /user1/daa;
date![]()
2011年 04月 19日 星期二
16:
09:
11 CST
![]()
[
1]+ Done gzip --stdout -d /user1/app/oradata/tpch2/lineitem.tbl.gz > /user1/daa
![]()
2011年 04月 19日 星期二
16:
10:
53 CST
![]()
![]()
[root@redflag11012501 tpch2]# ls -l x*
![]()
-rw-r--r--
1 root root
1951033298 04-
19 16:
09 x00
![]()
-rw-r--r--
1 root root
1962174224 04-
19 16:
10 x01
![]()
-rw-r--r--
1 root root
1962182478 04-
19 16:
10 x02
![]()
-rw-r--r--
1 root root
1960323740 04-
19 16:
10 x03
如果原始文件已经有多个,那么,视文件的大小和个数,如果都比较平均,那么不需要再分割,如果存在个别文件特别大,那么对此文件继续分割。然后,同样将数据文件用gzip压缩。
下一步,我们需要修改控制文件的加载方式为APPEND,并行加载必须在APPEND方式下才能进行,因为其他方式都要求表为空或将表清空后才能进行。
![]()
gunzip -c /user1/tpch/x00.gz > /user1/daa &
![]()
gunzip -c /user1/tpch/x01.gz > /user1/dab &
![]()
gunzip -c /user1/tpch/x02.gz > /user1/dac &
![]()
gunzip -c /user1/tpch/x03.gz > /user1/dad &
![]()
--在后台并行执行sqlldr
![]()
sqlldr tpch/tpch control=lineitem_sqlldr.ctl data=/user1/daa direct=
true parallel=
true log=lineitem_sqlldr_a.log &
![]()
sqlldr tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dab direct=
true parallel=
true log=lineitem_sqlldr_b.log &
![]()
sqlldr tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dac direct=
true parallel=
true log=lineitem_sqlldr_c.log &
![]()
sqlldr tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dad direct=
true parallel=
true log=lineitem_sqlldr_d.log &
![]()
--可以观察到后台有4个sqlldr进程
![]()
[oracle@redflag11012602 tpch]$ ps -ef|grep sqlldr
![]()
oracle
23205 23129 77 08:
48 pts/
7 00:
00:
34 sqlldr tpch/tpch control=lineitem_sqlldr.ctl data=/user1/daa direct=
true parallel=
true log=lineitem_sqlldr_a.log
![]()
oracle
23206 23129 77 08:
48 pts/
7 00:
00:
33 sqlldr tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dab direct=
true parallel=
true log=lineitem_sqlldr_b.log
![]()
oracle
23209 23129 76 08:
48 pts/
7 00:
00:
33 sqlldr tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dac direct=
true parallel=
true log=lineitem_sqlldr_c.log
![]()
oracle
23210 23129 76 08:
48 pts/
7 00:
00:
33 sqlldr tpch/tpch control=lineitem_sqlldr.ctl data=/user1/dad direct=
true parallel=
true log=lineitem_sqlldr_d.log
![]()
oracle
23227 23129 0 08:
49 pts/
7 00:
00:
00 grep sqlldr
![]()
--4个sqlldr进程几乎同时结束
![]()
[oracle@redflag11012602 tpch]$
![]()
Load completed - logical record count
15000000.
![]()
![]()
Load completed - logical record count
15000000.
![]()
![]()
Load completed - logical record count
15000000.
![]()
![]()
Load completed - logical record count
14986052.
![]()
--查看每个sqlldr任务的日志
![]()
[oracle@redflag11012602 tpch]$ tail lineitem_sqlldr_a.log
![]()
Total logical records rejected:
0![]()
Total logical records discarded:
0![]()
Total stream buffers loaded by SQL*Loader main thread:
3709![]()
Total stream buffers loaded by SQL*Loader load thread:
5565![]()
![]()
Run began
on Sun May
01 08:
48:
20 2011![]()
Run ended
on Sun May
01 08:
50:
30 2011![]()
![]()
Elapsed
time was:
00:
02:
10.32![]() time
time was:
00:
01:
36.34![]()
[oracle@redflag11012602 tpch]$ tail lineitem_sqlldr_b.log
![]()
Total logical records rejected:
0![]()
Total logical records discarded:
0![]()
Total stream buffers loaded by SQL*Loader main thread:
3729![]()
Total stream buffers loaded by SQL*Loader load thread:
5593![]()
![]()
Run began
on Sun May
01 08:
48:
20 2011![]()
Run ended
on Sun May
01 08:
50:
30 2011![]()
![]()
Elapsed
time was:
00:
02:
10.29![]()
CPU
time was:
00:
01:
36.92![]()
[oracle@redflag11012602 tpch]$ tail lineitem_sqlldr_c.log
![]()
Total logical records rejected:
0![]()
Total logical records discarded:
0![]()
Total stream buffers loaded by SQL*Loader main thread:
3730![]()
Total stream buffers loaded by SQL*Loader load thread:
5593![]()
![]()
Run began
on Sun May
01 08:
48:
20 2011![]()
Run ended
on Sun May
01 08:
50:
30 2011![]()
![]()
Elapsed
time was:
00:
02:
10.28![]()
CPU
time was:
00:
01:
36.76![]()
[oracle@redflag11012602 tpch]$ tail lineitem_sqlldr_d.log
![]()
Total logical records rejected:
0![]()
Total logical records discarded:
0![]()
Total stream buffers loaded by SQL*Loader main thread:
3728![]()
Total stream buffers loaded by SQL*Loader load thread:
5591![]()
![]()
Run began
on Sun May
01 08:
48:
20 2011![]()
Run ended
on Sun May
01 08:
50:
30 2011![]()
![]()
Elapsed
time was:
00:
02:
10.28![]()
CPU
time was:
00:
01:
36.19 数据采用并行加载后,时间大幅度减少,大约是原来的四分之一。Windows操作系统不支持&语法的后台进程,可以用打开多个cmd窗口,分别执行多个不同的sqlldr语句的方式,也能达到相同的效果。需要指出的是,的I/O能力对加载有巨大的影响,如果读写的I/O带宽已经用满,那么实际上就是sqlldr在等待I/O完成,那么此刻再启动多个sqlldr也不会提高加载性能。
2、外部表方式加载
外部表支持sqlldr引擎和数据泵,由于我们的数据是文本方式,故采用sqlldr引擎。
首先创建外部表,注意type为oracle_loader,PREPROCESSOR选择zcat,表示用zcat的结果插入。
![]()
SQL> create directory tpch_dir
as '/user1/tpch';
![]()
![]()
Directory created.
![]()
![]()
Elapsed:
00:
00:
00.02![]()
SQL> create directory zcat_dir
as '/bin';
![]()
![]()
Directory created.
![]()
CREATE TABLE lineitem_ext (L_ORDERKEY NUMBER(
10),
![]()
L_PARTKEY NUMBER(
10),
![]()
L_SUPPKEY NUMBER(
10),
![]()
L_LINENUMBER NUMBER(
38),
![]()
L_QUANTITY NUMBER,
![]()
L_EXTENDEDPRICE NUMBER,
![]()
L_DISCOUNT NUMBER,
![]()
L_TAX NUMBER,
![]()
L_RETURNFLAG CHAR(
1),
![]()
L_LINESTATUS CHAR(
1),
![]()
L_SHIPDATE VARCHAR2(
10),
![]()
L_COMMITDATE VARCHAR2(
10),
![]()
L_RECEIPTDATE VARCHAR2(
10),
![]()
L_SHIPINSTRUCT VARCHAR2(
25),
![]()
L_SHIPMODE VARCHAR2(
10),
![]()
L_COMMENT VARCHAR2(
44))
![]()
ORGANIZATION EXTERNAL (
![]()
TYPE oracle_loader
![]()
DEFAULT DIRECTORY tpch_dir
![]()
ACCESS PARAMETERS (
![]()
RECORDS DELIMITED BY NEWLINE
![]()
PREPROCESSOR zcat_dir:
'zcat'
![]()
BADFILE
'bad_%a_%p.bad'
![]()
LOGFILE
'log_%a_%p.log'
![]()
FIELDS TERMINATED BY
'|'
![]()
MISSING FIELD VALUES ARE
NULL)
![]()
LOCATION (
'lineitem.tbl.gz'))
![]()
PARALLEL
2 ![]()
REJECT LIMIT
0 ![]()
/
![]()
Table created.
![]()
Elapsed:
00:
00:
00.03 然后用直接路径将外部表数据插入实际要处理的表。由于日期列需要指定格式,用to_date参数处理。
![]()
insert /*+append*/into h_lineitem
![]() select
select L_ORDERKEY,
![]()
L_PARTKEY,
![]()
L_SUPPKEY,
![]()
L_LINENUMBER,
![]()
L_QUANTITY,
![]()
L_EXTENDEDPRICE,
![]()
L_DISCOUNT,
![]()
L_TAX,
![]()
L_RETURNFLAG,
![]()
L_LINESTATUS,
![]()
to_date(L_SHIPDATE,
'YYYY-MM-DD'),
![]()
to_date(L_COMMITDATE,
'YYYY-MM-DD'),
![]()
to_date(L_RECEIPTDATE,
'YYYY-MM-DD'),
![]()
L_SHIPINSTRUCT,
![]()
L_SHIPMODE,
![]()
L_COMMENT
![]()
from lineitem_ext;
![]()
/
![]() 59986052
59986052 rows created.
![]()
Elapsed:
00:
10:
26.35![]()
--利用多个文件创建另一个外部表,只修改location
![]()
CREATE TABLE lineitem_ext2 (L_ORDERKEY NUMBER(
10),
![]()
…
![]()
LOCATION (
'x00.gz','x01.gz','x02.gz','x03.gz'))
![]()
…
![]()
--用第二个外部表并行插入
![]()
insert /*+append parallel (a
8)*/into lineitem a
![]() select
select /*+ parallel (b
8)*/L_ORDERKEY,
![]()
L_PARTKEY,
![]()
L_SUPPKEY,
![]()
L_LINENUMBER,
![]()
L_QUANTITY,
![]()
L_EXTENDEDPRICE,
![]()
L_DISCOUNT,
![]()
L_TAX,
![]()
L_RETURNFLAG,
![]()
L_LINESTATUS,
![]()
to_date(L_SHIPDATE,
'YYYY-MM-DD'),
![]()
to_date(L_COMMITDATE,
'YYYY-MM-DD'),
![]()
to_date(L_RECEIPTDATE,
'YYYY-MM-DD'),
![]()
L_SHIPINSTRUCT,
![]()
L_SHIPMODE,
![]()
L_COMMENT
![]()
from lineitem_ext2 b;
![]()
/
![]() 59986052
59986052 rows created.
![]()
Elapsed:
00:
04:
13.94![]()
--用第一个外部表并行插入
![]()
![]()
insert /*+append parallel (a
8)*/into lineitem a
![]() select
select /*+ parallel (b
8)*/L_ORDERKEY,
![]()
…
![]()
from lineitem_ext b;
![]()
/
![]()
![]() 59986052
59986052 rows created.
![]()
![]()
Elapsed:
00:
08:
59.89 我们看到,location单个外部文件的外部表,指定了并行插入仍然需要大约9分钟时间,比sqlldr单进程还慢,采用多个外部文件的外部表,并行插入时间4分钟多,也比sqlldr并行加载差很多,to_date的日期转换是有些影响,但由于加载引擎实际没有区别,也就难以超过sqlldr命令的效果。
3、数据查询
为了比较不同条件下的查询结果,我们进行了4种组合的查询。分别是:单进程不压缩,并行不压缩,单进程压缩,并行压缩,每种测试做2遍,取较快的一遍的结果。
![]()
--用来压缩表的语句,并行参数可加快速度,但并不改变被move的表的并行度
![]()
alter table CUSTOMER move compress parallel
32;
![]()
alter table LINEITEM move compress parallel
32;
![]()
alter table NATION move compress parallel
32;
![]()
alter table ORDERS move compress parallel
32;
![]()
alter table PART move compress parallel
32;
![]()
alter table PARTSUPP move compress parallel
32;
![]()
alter table REGION move compress parallel
32;
![]()
alter table SUPPLIER move compress parallel
32;
![]()
![]()
--压缩前字节数
![]()
SQL>
set numw
20 ![]()
SQL>
select segment_name,sum(bytes) from user_segments where segment_name
not like
'%EXT%' group by segment_name order by 1;
![]()
![]()
SEGMENT_NAME SUM(BYTES)
![]()
------------------ --------------------
![]()
CUSTOMER
281804800![]()
LINEITEM
7730102272![]()
NATION
65536![]()
ORDERS
1874067456![]()
PART
278986752![]()
PARTSUPP
1367867392![]()
REGION
65536![]()
SUPPLIER
16646144![]()
![]()
--压缩后
![]()
SEGMENT_NAME SUM(BYTES)
![]()
------------------- --------------------
![]()
CUSTOMER
248643584![]()
LINEITEM
5389484032![]()
NATION
65536![]()
ORDERS
1566310400![]()
PART
207290368![]()
PARTSUPP
1251344384![]()
REGION
65536![]()
SUPPLIER
17301504 从上面表的占用空间可见,对于tpc-h数据,因为dbgen生成的数据比较随机,又是符合第3范式的,冗余较少,Oracle压缩的效果不太明显。节约的I/O有限,像SUPPLIER表大小反而增加了,还增加了解压的负担。
下面是各组查询测试结果:
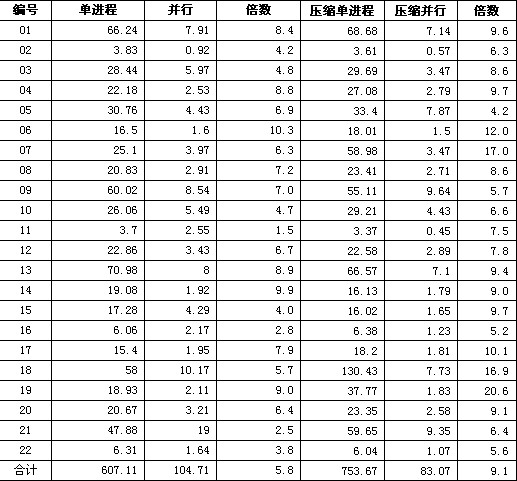
▲表1 TPC-H cale=10未压缩和压缩数据的测试对比,单位:秒
可见无论是否压缩,并行查询比单进程都有几倍或十几倍的提高,具体提高的倍数和查询的类型和机器的CPU个数有关。用来测试的机器有8个逻辑CPU,在不压缩的情况下能提高大约5倍,在压缩的情况下,单进程的性能比不压缩更差,所以光看提高的倍数是不够的,还要看查询的实际时间比。
从上述数据我们还可以得出单进程和并行分别查询压缩和非压缩数据的差异:
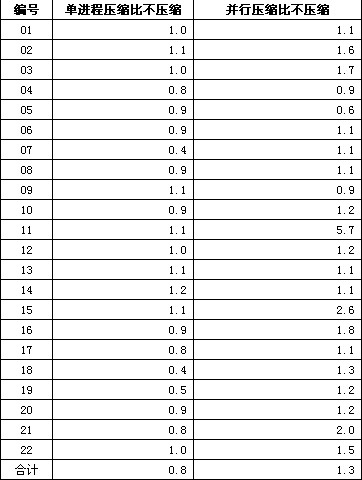
▲表2 TPC-H scale=10压缩前后数据的测试对比,单位:倍
如上表所示,从合计时间看,单进程压缩比不压缩反而速度降低了20%,而并行条件下,则有30%的性能提高。从单个查询看,压缩和不压缩互有胜负,这跟前面我们列出的压缩文件大小有关,如果I/O没有变化或者更大,那么加上解压开销,查询速度下降也是必然的。
四、性能调整和优化
Oracle性能调整和优化是个复杂的命题,涵盖表结构设计、查询设计、参数调整等方面,前文介绍的压缩和并行都是简单的参数调整优化手段,如果是实际的查询,而不是基准测试,我们就需要充分利用Oracle的功能,针对每个查询单独优化。
1、查询的改写
由于Oracle的查询优化器相对比较智能,对SQL语句书写的要求比其他数据库要相对低一些,这给应用开发人员带来了方便。比如第15个查询,下面2种完全迥异的写法,执行效果却是差不多的。
![]()
--根据原始的第15个查询语句,将视图改为子查询
![]()
SQL>
select * from(
![]() 2 select
2 select![]() 3
3 s_suppkey,
![]() 4
4 s_name,
![]() 5
5 s_address,
![]() 6
6 s_phone,
![]() 7
7 total_revenue
![]() 8
8 from
![]() 9
9 supplier,
![]() 10
10 (
![]() 11 select
11 select![]() 12
12 l_suppkey supplier_no,
![]() 13
13 sum(l_extendedprice * (
1 - l_discount))total_revenue
![]() 14
14 from
![]() 15
15 lineitem
![]() 16
16 where
![]() 17
17 l_shipdate >=
date '1995-02-01'
![]() 18 and
18 and l_shipdate <
date '1995-02-01' + interval '3' month
![]() 19
19 group by
![]() 20
20 l_suppkey
![]() 21
21 )
![]() 22
22 revenue0
![]() 23
23 where
![]() 24
24 s_suppkey = supplier_no
![]() 25 and
25 and total_revenue = (
![]() 26 select
26 select![]() 27
27 max(total_revenue)
![]() 28
28 from
![]() 29
29 (
![]() 30 select
30 select![]() 31
31 l_suppkey supplier_no,
![]() 32
32 sum(l_extendedprice * (
1 - l_discount))total_revenue
![]() 33
33 from
![]() 34
34 lineitem
![]() 35
35 where
![]() 36
36 l_shipdate >=
date '1995-02-01'
![]() 37 and
37 and l_shipdate <
date '1995-02-01' + interval '3' month
![]() 38
38 group by
![]() 39
39 l_suppkey
![]() 40
40 )
![]() 41
41 revenue0
![]() 42
42 )
![]() 43
43 order by
![]() 44
44 s_suppkey)
![]() 45
45 where rownum <=
10;
![]()
![]()
S_SUPPKEY S_NAME S_ADDRESS S_PHONE TOTAL_REVENUE
![]()
---------- ------------------- ------------------- --------------- -------------
![]() 83966
83966 Supplier#
000083966 0ITp9HCIUHEHgWCjeTt
24-
897-
113-
5492 2147201.69![]()
![]()
已用时间:
00:
00:
20.46![]()
![]()
--修改后的第15个查询语句,分析函数写法
![]()
SQL>
select s_suppkey, s_name, s_address, s_phone, total_revenue
![]() 2
2 from supplier
![]() 3
3 ,(
select l_suppkey
as supplier_no,
![]() 4
4 sum(l_extendedprice * (
1 - l_discount))
as total_revenue
![]() 5
5 ,RANK() OVER(ORDER BY sum(l_extendedprice * (
1 - l_discount)) DESC)
AS rnk
![]() 6
6 from lineitem
![]() 7
7 where l_shipdate >=
date '1995-02-01'
![]() 8 and
8 and l_shipdate <
date '1995-02-01' + interval '3' month
![]() 9
9 group by
![]() 10
10 l_suppkey
![]() 11
11 ) revenue1
![]() 12
12 where s_suppkey = supplier_no
![]() 13 AND
13 AND rnk=
1![]() 14
14 order by s_suppkey;
![]()
![]()
![]()
S_SUPPKEY S_NAME S_ADDRESS S_PHONE TOTAL_REVENUE
![]()
---------- ------------------- ------------------- --------------- -------------
![]() 83966
83966 Supplier#
000083966 0ITp9HCIUHEHgWCjeTt
24-
897-
113-
5492 2147201.69![]()
![]()
已用时间:
00:
00:
20.16 2、统计信息收集和管理
正确的统计信息对Oracle得出较好的执行计划有十分重要的影响,在大量插入或更新数据以后,甚至对表进行move后,需要重新收集统计信息。比如:对某个用户下所有的对象收集统计信息,degree表示并行收集的并行度。
![]()
SQL>
set timi
on ![]()
SQL> exec dbms_stats.gather_schema_stats(
'TPCH');
![]()
![]()
PL/SQL procedure successfully completed.
![]()
![]()
Elapsed:
00:
19:
29.98![]()
![]()
SQL> exec dbms_stats.gather_schema_stats(ownname =>
'TPCH', degree => 32)
![]()
![]()
PL/SQL procedure successfully completed.
![]()
![]()
Elapsed:
00:
14:
55.46 Oracle也提供了自动统计信息收集任务,一般在晚间执行,该过程首先检测统计信息缺失和陈旧的对象。然后确定优先级,再开始进行统计信息。
这个功能还是很有用的,比如第18个查询,单进程查询,没有收集统计信息前需要2个多小时,自动统计信息收集后只要不到2分钟就完成了。如果不利用统计信息,那么必须要求开发人员非常熟悉Oracle的各种连接和排序方法,人工添加提示来影响执行计划,这没有相当丰富的开发经验是做不到的。
还有其他的优化手段,比如添加必要的索引,由于时间所限,兼之前文所述的“TPC-H检查可用数据的大多数”原因,没有进行测试。但单从添加dss.ri中的主外键约束来看,测试结果和不带主外键约束,差别不大,具体数据就不易已列出了,有兴趣的读者可以自行检验。
五、小结
看到这里,相信读者对Oracle数据库已经有了初步的印象,安装虽然比较复杂,安装包也体积庞大,但功能还是很强大,性能也比较好,能充分利用硬件资源。对开发人员来说,不必在SQL的语法上面太过钻研,转而从业务理解上面按通常的写法就能取得较好的效果,可以大大提高他们的工作效率。Oracle 11g还提供了功能更强的SQL调优工具,可以帮助开发人员改善他们的SQL。
要说存在的问题, Oracle对硬件的要求较高,需要提供较大的内存和磁盘空间,也需要多个CPU。其次,压缩率不高,压缩数据对单进程查询有害无益,但对于企业应用,大容量存储和多CPU都不是大问题,因此这个缺点影响不大。再就是Oracle系统的复杂性,比如同样是统计信息收集,如果用的参数不同,产生的执行计划也有天壤之别,对数据库管理人员的要求还是较高的。
总的来说,如果用户十分在意查询性能,对数据压缩要求一般,那么Oracle是一个好的选择。而对最终用户来说,本文没有提及的图形化的管理工具EM也是一个很好的工具,不必手工输入和记忆大量的管理SQL语句,就能监控数据库运行和进行日常维护工作。
