分类:
2010-01-05 10:27:28
随着中国经济高速发展,中国已经成为“世界制造中心”,但我们的制造还大多数属于简单的浅层面。大部分产品是在国外研发设计,在国内生产。未来市场激烈竞争加剧,必然需要不断创新和追求完美的自主研发设计,在工程计算领域,用户对CAE(计算机辅助工程)技术的信任度和依赖性越来越高,CAE应用范围和深度在不断拓展、延伸。单一或少量零、部件的CAE分析逐渐过渡到了系统级的仿真计算(如整车);单一物理场的研究演变多物理场耦合问题的研究;单一目标的求解发展为多目标、甚至直接探求问题机理的求解计算……工程计算的规模和复杂度正迅速膨胀,专业CAE应用对计算机性能的要求也相应提高
CAE包括的FEA(有限元分析)和CFD(计算流体力学)分析手段,在工程设计和分析中,已经成为解决复杂的工程分析计算问题的有效途径,现在从汽车到航天飞机几乎所有的设计制造都已离不开有限元分析和计算流体力学计算,其在机械制造、材料加工、航空航天、汽车、土木建筑、电子电器,国防军工,船舶,铁道,石化,能源,科学研究等各个领域的广泛使用已使设计水平发生了质的飞跃。随着计算机运行速度与存储容量不断地增加,CAE所能解决问题的尺度与复杂度也逐渐加大,目前已能够为用户解决各种复杂的工程问题
CAE的HPC(高性能计算)应用软件使用最广泛是ANSYS、Fluent、CFX(流体)以及LS-DYNA(碰撞)等,用户使用这些软件进行复杂和大规模问题的求解,对计算机内存、处理器和I/O带宽的要求非常高。早期的数值分析软件是在大中型计算机上开发和运行的,后来又发展到以工程工作站(EWS,Engineering Work Station)上,它们都是用UNIX操作系统,所有这些成本太高,非一般单位的工程设计人员所能拥有的,现在不同了,四核64位处理器普及配合微软的高性能计算Windows系统,将极大地降低高性能计算的应用门槛,让更多的工程技术和研发人员有机会享受高性能计算的强大性能,高性能计算不再是高成本的时代了

产品型号:XASUN X5500 T23324AB
参考配置
|
配件 |
品牌和型号 |
数量 |
|
CPU |
四核Xeon W5590 |
2 |
|
风扇 |
超静音热管温控 |
2 |
|
主板 |
超微X8DA6 |
1 |
|
内存 |
4G DDR3 1333 Reg ECC |
6 |
|
显卡 |
Nvidia FX1800 768MB GDDR3 |
1 |
|
硬盘 |
ST 146G 6Gbps SAS |
1 |
|
机箱 |
XASUN T2-CB-SR105 |
1 |
|
电源 |
1000W EPS 24+8+8 静音 |
1 |
|
报价 |
49999元 |
XASUN超级工作站的技术要点
CAE对系统的浮点运算性能和内存带宽要求非常高,影响计算性能的主要环节是:CPU运算单元→ CPU二级缓存→ 前端总线 → 北桥芯片→ 内存→ 硬盘,每一个环节都不能忽视,最新英特尔Nehalem架构的四核Xeon5500处理器,拥有众多性能卓越的技术,包括基于Core架构的酷睿CP
CPU采用2颗Xeo
主板采用超微X8DA6 支持最新四核Xeon
,板载最新6Gbps SASII接口
内存容量24G,6根
硬盘采用最新6Gbps SAS
显卡Quadro FX1800 一款高端专业图形处理
整个机器噪音标准达到XASUN的静音级规格
将上述产品结合搭建的
基于FEA/CFD工作站关键配件选型
CPU 四核 Xeon W5590 4 x 3.33G /8M L2/6.4GTs
Nehalem新技术详解
1 .QPI总线技术
在Nehalem之前,Intel一直使用FSB前端总线作为处理器与芯片组连接的桥梁,虽然1600Mhz的前端总线对于桌面级数据处理来说已是绰绰有余,但对于数据量庞大的服务器来说,其仍然是性能的瓶颈。Nehalem因此引入了全新的串行总线QPI,QPI总线是基于数据包传输(packet-based)。其拥有高带宽、低延迟的点到点互连技术等特点,它的传输速度可以达到每秒6.4G次数据。与FSB最大的不同在于,QPI不仅仅可以负责CPU与北桥通信,还可以实现CPU与CPU之间的相互连通。正如前文中所提到的Nehalem模块化的特点,对于不同市场的Nehalem,可以具有不同的QPI总线条数。比如桌面市场的CPU,具有1条或者半条QPI总线(半条可能是用10bit位宽或单向);DP服务器(双CPU插座)的CPU,每个具有2条QPI总线;而MP服务器(4个或8个CPU插座)的,则每个具有4条或更多的QPI总线。
2.内存控制器
在AMD整合了内存控制器长达5年之久后,Intel终于按捺不住了。为了进一步降低处理器访问内存的延迟以提高处理器的性能,Intel也引入了内存控制器的概念。
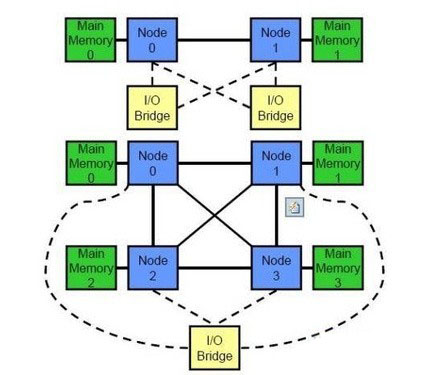
Intel 整合内存控制器(IMC)示意图
3.同步多线程技术
Intel的整合内存控制器(integrated memory controller),可以支持3通道的DDR3内存运行在1.33GT/s(DDR3-1333),这样总共的峰值带宽就可以达到32GB/s。三通道的DDR3内存,其每通道都能够独立操作,其处理器所集成的内存控制器需要乱序执行来降低延迟。
不过,高性能也是有高付出的,在高端平台上,必须要三条DDR3内存才能够打开三通道,而且三通道内存也并没有加入DDR2的设计,因此用户只能够选择DDR3内存来感受内存延迟降低的快感。
自从奔腾4时期开始,超线程技术便已经是家喻户晓了。在当时31级流水线的P4上面,为了提高处理器的性能,细化的流水线可以操作不同的任务进程。然而,在14级流水线下的Core上面,超线程技术消失了。不过这一切都是暂时的。因为Nehalem又重新引入了类似于·超线程技术的同步多线程技术。
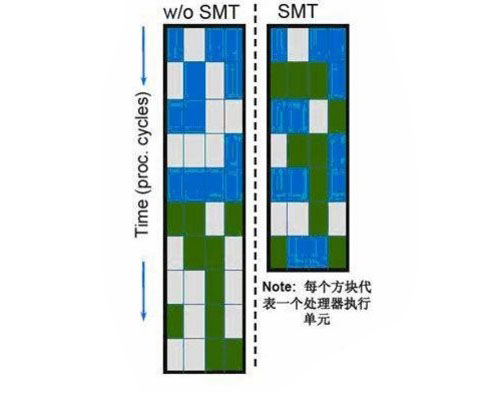
Nehalem同步多线程技术图解
Nehalem的同步多线程(Simultaneous Multi-Threading,SMT)是2-way的,每核心可以同时执行2个线程。这样就可以压缩多任务处理时所需要的总时间。同步多线程功能的好处是只需要消耗很小的核心面积代价,就可以在多任务的情况下提供显著的性能提升,比起完全再添加一个物理核心来说要划算得多。并且,Nehalem因为L3大缓存的设计及内存控制器的集成使之拥有了更大的缓存和更大的内存带宽,而且基于Core微架构中表现优秀的分支预测设计能够更加有效的发挥多线程的性能。
4.缓存结构
在早期的奔腾D时代,由于2颗核心之间互相独立,因此其之间的数据调配需要通过前端总线来进行,这使得数据的处理存在非常高的延迟。在Core时代,这一情况有所好转,因为Core核心共享了L2缓存,这使得数据处理延迟大大降低。而在Nehalem上,我们又看见了一种新的缓存管理机制,包含式缓存。

Nehalem缓存结构
Nehalem上,8MB的L3对于前两级来说,是完全包含式的,并且由4个核心共享,其可以处理几乎所有的一致性流量问题,而不需要打搅到每个独立核心的私有缓存。如果在L3中发生命中失败,那么要访问的数据就肯定也不在任何一个L2和L1中,不需要侦听其它内核。另一方面,Nehalem的L3对于缓存命中成功,也扮演着侦听过滤器的角色。在Nehalem的L3中的每一个缓存行里,有4 bit是用来做核心确认的,表明是哪一个核心在它的私有缓存里具有这个行的数据备份。如果一个核心确认位被设置成0,则那个核心就不具有该行的数据备份。Nehalem使用的是MESIF缓存一致性协议(MESIF cache coherency protocol),如果两个以上核心的确认位都有效(设置成1),那么该缓存行就被确定是未被修改的,任何一个内核的缓存行都不能够进入更改模式。当L3缓存命中,而4个核心确认位都是0时,就不需要对其它内核做侦听;而只有1个位是有效时,则只需要侦听那一个核心。这两种技术的联合使用,使得L3可以尽可能的让每个核心避免数据一致性错误,这样就给出更多的实际带宽。 Nehalem的每个核心有64KB L1和256KB必须在L3缓存中保留数据,这就意味着在8MB的L3中,有1-1.25MB的数据是前两级缓存中也有的数据。这也恰恰就是包含式缓存额外的开销。
主板 超微X8DA6 支持双路Xeon5500,提供6Gbps SAS接口
上面我们分析了有限元分析软件对运算的极高要求,我们推荐采用intel最新架构主板超微X8DA6
超微X8DA6为高性能计算要求而设计的工作站主板,它的配置更好的满足有限元分析软件的最高要求。下面是该主板技术参数
支持目前最高规格的Intel 基于Core2架构的四核Xeon5500系列处理器
全新QPI总线结构,从根本上解决前端总线方面的瓶颈,将具有1333MHz的处理器系统总线和核心逻辑来支持芯片,加宽CPU总线带宽
内存采用目前最新的DDR3-800/1066/1333 RDIMM/UDIMM,CPU与内存直连结构,CPU和内存之间三通道,CPU和内存带宽6.4GBs,集成双千兆网卡,板载声卡,USB2.0接口,并且拥有多条PCI-E x16插槽。此外还具有2条PCI-E x4插槽
支持最新SASII 6Gbps接口 8块,支持RAID0、1、10
SAS II代 6Gbps IO带宽硬盘---Seagate 146G 6Gbps SAS
硬盘采用最新SAS II 代 6Gbps接口,转速10000转的10K.3 300G,保证数据读写带宽大幅提升,如果借助硬RAID卡,硬盘读写带宽从160MB/S提升到800MB/S,CAE计算最大瓶颈将有质的改变。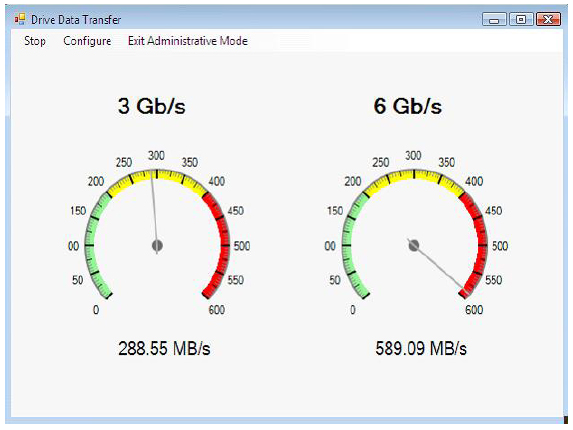
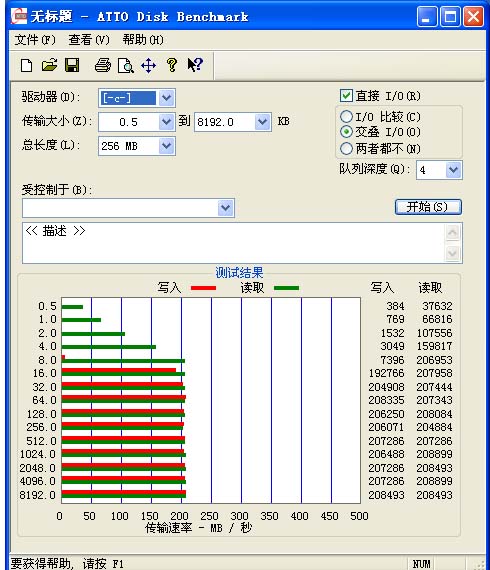
测试软件结果在200MB/S,这是目前最快的SAS硬盘了,对大IO吞吐率要求应用有显著的帮助和整体性能大幅提升
性价比之王--丽台Quadro FX1800 768MB 专业显卡
有限元分析软件对图形功能的要求不是特别高,只要对所计算的结果通过图形有所表现,基本就可以了,但是所有图形处理都是借助OPEN GL函数实现的,为此显卡方面推荐专业图形卡丽台NVIDIA Quadro FX1800是比较合适的,该卡配备768MB超高速GDDR3缓存、38.2GB/s内存带宽,以及支持高分辨率(2048 x 1536)数字屏幕;下一代PCI Express总线架构在几何与填充率上有超过两倍的改善,为CAE专业用户带来高性价比的图像解决方案。丽台Quadro FX1800不但有亲和力的价格,在功能/性能上也毫不含糊,提供完整且先进的功能与价值,兼顾精确度、效能表现和可程序化功能。
总结
英特尔四核处理器逐渐成为高性能计算更强大引擎。高性能计算作为企业工程设计中的一个重要组成部分,成为核心竞争力的来源.扮演支持业务发展的重要角色。随着IT软硬件技术及其相关的配套系统的快速发展,高性能计算不再像以前那样高不可及,已经成为更加标准化和商品化的lT基础架构,进入门槛足够低,架构灵活性和可扩展能力更高。因此,国内企业应该把握住这一时机,加速应用高性能计算,籍此提升自身的核心竞争力。
通过上述配件搭配,完全考虑到影响CPU运算速度的各个环节,CPU, 二级缓存,内存,以及之间的通道,比之老Xeon性能得到质的飞跃,订制的最大好处,结合应用软件合理配置硬件,可以搭配出性价比最高的一套配置,相对于通用型工作站要合算的多。目前很多设计研发单位在资金有限情况下,要求最小投入最大回报,这是一个明智的选择。
技术咨询:
北京太阳HPC应用中心
北京中关村E世界财富中心C座880室
13681027099 13520538244 010-82696887-8005
