DBA
分类: Mysql/postgreSQL
2013-04-18 17:56:55
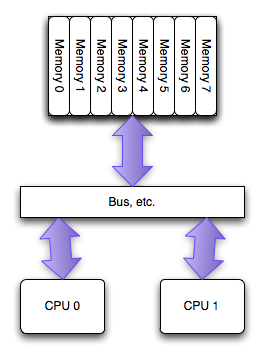
The SMP,
or UMA architecture, simplified
When the PC world first got multiple processors, they were all arranged with equal access to all of the memory in the system. This is called , or sometimes Uniform Memory Architecture (UMA, especially in contrast to NUMA). In the past few years this architecture has been largely phased out between physical socketed processors, but is still alive and well today within a single processor with multiple cores: all cores have equal access to the memory bank.
The NUMA architecture
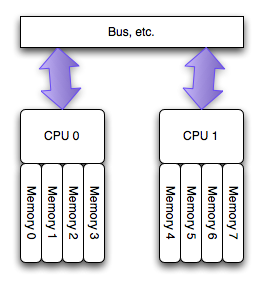
The NUMA
architecture, simplified
The new architecture for multiple processors, starting with and 2processors (we’ll call these “modern PC CPUs”), is a architecture, or more correctly . In this architecture, each processor has a “local” bank of memory, to which it has much closer (lower latency) access. The whole system may still operate as one unit, and all memory is basically accessible from everywhere, but at a potentially higher latency and lower performance.
Fundamentally, some memory locations (“local” ones) are faster, that is, cost less to access, than other locations (“remote” ones attached to other processors). For a more detailed discussion of NUMA implementation and its support in Linux, see .
Linux automatically understands when it’s running on a NUMA architecture system and does a few things:
You can see how Linux enumerated your system’s NUMA layout using the numactl --hardwarecommand:
# numactl --hardware available: 2 nodes (0-1) node 0 size: 32276 MB node 0 free: 26856 MB node 1 size: 32320 MB node 1 free: 26897 MB node distances: node 0 1 0: 10 21 1: 21 10
This tells you a few important things:
Technically, as long as everything runs just fine, there’s no reason that being UMA or NUMA should change how things work at the OS level. However, if you’re to get the best possible performance (and indeed in some cases with extreme performance differences for non-local NUMA access, any performance at all) some additional work has to be done, directly dealing with the internals of NUMA. Linux does the following things which might be unexpected if you think of CPUs and memory as black boxes:
The NUMA policy of any process can be changed, with broad-reaching effects, very simply using as a wrapper for the program. With a bit of additional work, it can be fine-tuned in detail by linking in and writing some code yourself to manage the policy. Some interesting things that can be done simply with the numactl wrapper are:
InnoDB, and really, nearly all database servers (), present an atypical workload (from the point of view of the majority of installations) to Linux: a single large multi-threaded process which consumes nearly all of the system’s memory and should be expected to consume as much of the rest of the system resources as possible.
In a NUMA-based system, where the memory is divided into multiple nodes, how the system should handle this is not necessarily straightforward. The default behavior of the system is to allocate memory in the same node as a thread is scheduled to run on, and this works well for small amounts of memory, but when you want to allocate more than half of the system memory it’s no longer physically possible to even do it in a single NUMA node: In a two-node system, only 50% of the memory is in each node. Additionally, since many different queries will be running at the same time, on both processors, neither individual processor necessarily has preferential access to any particular part of memory needed by a particular query.
It turns out that this seems to matter in one very important way. Using we can see all of the allocations made by mysqld, and some interesting information about them. If you look for a really big number in the anon=size, you can pretty easily find the buffer pool (which will consume more than 51GB of memory for the 48GB that it has been configured to use) [line-wrapped for clarity]:
2aaaaad3e000 default anon=13240527 dirty=13223315 swapcache=3440324 active=13202235 N0=7865429 N1=5375098
The fields being shown here are:
The entire numa_maps can be quickly summarized by the a simple script numa-maps-summary.pl, which I’ve written while analyzing this problem:
N0 : 7983584 ( 30.45 GB) N1 : 5440464 ( 20.75 GB) active : 13406601 ( 51.14 GB) anon : 13422697 ( 51.20 GB) dirty : 13407242 ( 51.14 GB) mapmax : 977 ( 0.00 GB) mapped : 1377 ( 0.01 GB) swapcache : 3619780 ( 13.81 GB)
An couple of interesting and somewhat unexpected things pop out to me:
The memory allocated by MySQL looks something like this:
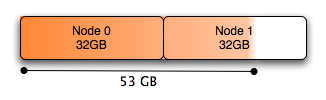
Allocating memory severely imbalanced, preferring Node 0
Due to Node 0 being completely exhausted of free memory, even though the system has plenty of free memory overall (over 10GB has been used for caches) it is entirely on Node 1. If any process scheduled on Node 0 needs local memory for anything, it will cause some of the already-allocated memory to be swapped out in order to free up some Node 0 pages. Even though there is free memory on Node 1, the Linux kernel in many circumstances (which admittedly I don’t totally understand3) prefers to page out Node 0 memory rather than free some of the cache on Node 1 and use that memory. Of course the paging is far more expensive than non-local memory access ever would be.
An easy solution to this is to interleave the allocated memory. It is possible to do this using numactlas described above:
# numactl --interleave all command
We can use this with MySQL by making a , adding the following line (after cmd="$NOHUP_NICENESS"), which prefixes the command to start mysqld with a call tonumactl:
cmd="/usr/bin/numactl --interleave all $cmd"
Now, when MySQL needs memory it will allocate it interleaved across all nodes, effectively balancing the amount of memory allocated in each node. This will leave some free memory in each node, allowing the Linux kernel to cache data on both nodes, thus allowing memory to be easily freed on either node just by freeing caches (as it’s supposed to work) rather than paging.
Performance regression testing has been done comparing the two scenarios (default local plus spillover allocation versus interleaved allocation) using the DBT2 benchmark, and found that performance in the nominal case is identical. This is expected. The breakthrough comes in that: In all cases where swap use could be triggered in a repeatable fashion, the system no longer swaps!
You can now see from the numa_maps that all allocated memory has been spread evenly across Node 0 and Node 1:
2aaaaad3e000 interleave=0-1 anon=13359067 dirty=13359067 N0=6679535 N1=6679532
And the summary looks like this:
N0 : 6814756 ( 26.00 GB) N1 : 6816444 ( 26.00 GB) anon : 13629853 ( 51.99 GB) dirty : 13629853 ( 51.99 GB) mapmax : 296 ( 0.00 GB) mapped : 1384 ( 0.01 GB)
In graphical terms, the allocation of all memory within mysqld has been made in a balanced way:
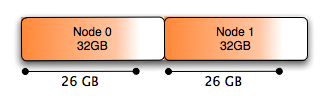
Allocating memory balanced (interleaved) across nodes
The zone_reclaim_mode tunable in /proc/sys/vm can be used to fine-tune memory reclamation policies in a NUMA system. Subject to from the linux-mm mailing list, it doesn’t seem to help in this case.
