分类: LINUX
2012-05-11 13:53:19
load average:平均负载,os级参数,被定义为在特定时间间隔内运行队列中的平均进程数。如果一个进程满足以下条件则其就会位于运行队列中:
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用'wait')
- 没有被停止(例如:等待终止)
查看命令:
$ uptime 11:12:26 up 3:44, 4 users, load average: 0.38, 0.31, 0.19
上面的输出,load average后面分别是1分钟、5分钟、15分钟的负载情况。数据是每隔5秒钟检查一次活跃的进程数,然后根据这个数值算出来的。如果这个数除以CPU的数目,结果高于5的时候就表明系统在超负荷运转了。从查到的其他资料上得知:load avarage/cpu数目 <3 系统良好,3到5之间可以接受,大于5 则可能有严重的性能问题。或者是主机提供的服务超过了他能够提供的能力,需要扩容了。要看具体情况。
==========================================================================
单个CPU 不超过3.0为正常, 如双核CPU 就是2*3.0<=6.0 为正常,如果四核,4*3.0<=12.0为正常,域者,现在 Load Average 数除以CPU个数 <=3 为正常,如现在 Load Average 为8.91 5.23 3.22 cpu 双核计算,8.91/2=4.455 >3 所以不正常, 对比方式来看双核来看是6在正常,但现在是8.91所以不正常,如果CPU是 四核(或至强CPU) 8.91/4=2.2275<3 这是正常, 对比方式来看,四核(至强CPU)12在为正常,但是现在8.91 所以也是正常的。
如果不正常,则需要:
检查那个进程 使用 CPU 时间最多,并且使用百分几率最高的程序,
如果硬盘没有问题,就是程序上有问题,分析都没有可凝,那么可能已经到负载拼颈,需要加设备来解决。
如果程序CPU占用率不多,时间不长,而 Load Average 仍然很高,这时要考虑检查硬盘是否有问题,或其它硬件的问题。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
linux load average 系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数。如果一个进程满足以下条件则其就会位于运行队列中: SIP的第四期结束了,因为控制策略的丰富,早先的的压力测试结果已经无法反映在高并发和高压力下SIP的运行状况,因此需要重新作压力测试。跟在测试人员后面做了快一周的压力测试,压力测试的报告也正式出炉,本来也就算是告一段落,但第二天测试人员说要修改报告,由于这次作压力测试的同学是第一次作,有一个指标没有注意,因此需要修改几个测试结果。那个没有注意的指标就是load average,他和我一样开始只是注意了CPU,内存的使用状况,而没有太注意这个指标,这个指标与他们通常的限制(10左右)有差别。重新测试的结果由于这个指标被要求压低,最后的报告显然不如原来的好看。自己也没有深入过压力测试,但是觉得不搞明白对将来机器配置和扩容都会有影响,因此去问了DBA和SA,得到的结果相差很大,看来不得不自己去找找问题的根本所在了。 通过下面的几个部分的了解,可以一步一步的找出Load Average在压力测试中真正的作用。 CPU时间片 为了提高程序执行效率,大家在很多应用中都采用了多线程模式,这样可以将原来的序列化执行变为并行执行,任务的分解以及并行执行能够极大地提高程序的运行效率。但这都是代码级别的表现,而硬件是如何支持的呢?那就要靠CPU的时间片模式来说明这一切。程序的任何指令的执行往往都会要竞争CPU这个最宝贵的资源,不论你的程序分成了多少个线程去执行不同的任务,他们都必须排队等待获取这个资源来计算和处理命令。先看看单CPU的情况。下面两图描述了时间片模式和非时间片模式下的线程执行的情况: 在图一中可以看到,任何线程如果都排队等待CPU资源的获取,那么所谓的多线程就没有任何实际意义。图二中的CPU Manager只是我虚拟的一个角色,由它来分配和管理CPU的使用状况,此时多线程将会在运行过程中都有机会得到CPU资源,也真正实现了在单CPU的情况下实现多线程并行处理。 多CPU的情况只是单CPU的扩展,当所有的CPU都满负荷运作的时候,就会对每一个CPU采用时间片的方式来提高效率。 在Linux的内核处理过程中,每一个进程默认会有一个固定的时间片来执行命令(默认为1/100秒),这段时间内进程被分配到CPU,然后独占使用。如果使用完,同时未到时间片的规定时间,那么就主动放弃CPU的占用,如果到时间片尚未完成工作,那么CPU的使用权也会被收回,进程将会被中断挂起等待下一个时间片。 CPU利用率和Load Average的区别 压 力测试不仅需要对业务场景的并发用户等压力参数作模拟,同时也需要在压力测试过程中随时关注机器的性能情况,来确保压力测试的有效性。当服务器长期处于一 种超负荷的情况下运行,所能接收的压力并不是我们所认为的可接受的压力。就好比项目经理在给一个人估工作量的时候,每天都让这个人工作12个小时,那么所制定的项目计划就不是一个合理的计划,那个人迟早会垮掉,而影响整体的项目进度。 CPU利用率在过去常常被我们这些外行认为是判断机器是否已经到了满负荷的一个标准,看到50%-60%的使用率就认为机器就已经压到了临界了。CPU利用率,顾名思义就是对于CPU的使用状况,这是对一个时间段内CPU使用状况的统计,通过这个指标可以看出在某一个时间段内CPU被占用的情况,如果被占用时间很高,那么就需要考虑CPU是否已经处于超负荷运作,长期超负荷运作对于机器本身来说是一种损害,因此必须将CPU的利用率控制在一定的比例下,以保证机器的正常运作。 Load Average是CPU的Load,它所包含的信息不是CPU的使用率状况,而是在一段时间内CPU正在处理以及等待CPU处理的进程数之和的统计信息,也就是CPU使用队列的长度的统计信息。为什么要统计这个信息,这个信息的对于压力测试的影响究竟是怎么样的,那就通过一个类比来解释CPU利用率和Load Average的区别以及对于压力测试的指导意义。 我们将CPU就类比为电话亭,每一个进程都是一个需要打电话的人。现在一共有4个电话亭(就好比我们的机器有4核),有10个人需要打电话。现在使用电话的规则是管理员会按照顺序给每一个人轮流分配1分钟的使用电话时间,如果使用者在1分钟内使用完毕,那么可以立刻将电话使用权返还给管理员,如果到了1分钟电话使用者还没有使用完毕,那么需要重新排队,等待再次分配使用。 上图中对于使用电话的用户又作了一次分类,1min的代表这些使用者占用电话时间小于等于1min,2min表示使用者占用电话时间小于等于2min,以此类推。根据电话使用规则,1min的用户只需要得到一次分配即可完成通话,而其他两类用户需要排队两次到三次。 电话的利用率 = sum (active use cpu time)/period 每一个分配到电话的使用者使用电话时间的总和去除以统计的时间段。这里需要注意的是是使用电话的时间总和(sum(active use cpu time)),这与占用时间的总和(sum(occupy cpu time))是有区别的。(例如一个用户得到了一分钟的使用权,在10秒钟内打了电话,然后去查询号码本花了20秒钟,再用剩下的30秒打了另一个电话,那么占用了电话1分钟,实际只是使用了40秒) 电话的Average Load体现的是在某一统计时间段内,所有使用电话的人加上等待电话分配的人一个平均统计。 电话利用率的统计能够反映的是电话被使用的情况,当电话长期处于被使用而没有的到足够的时间休息间歇,那么对于电话硬件来说是一种超负荷的运作,需要调整使用频度。而电话Average Load却从另一个角度来展现对于电话使用状态的描述,Average Load越高说明对于电话资源的竞争越激烈,电话资源比较短缺。对于资源的申请和维护其实也是需要很大的成本,所以在这种高Average Load的情况下电话资源的长期“热竞争”也是对于硬件的一种损害。 低利用率的情况下是否会有高Load Average的情况产生呢?理解占有时间和使用时间就可以知道,当分配时间片以后,是否使用完全取决于使用者,因此完全可能出现低利用率高Load Average的情况。由此来看,仅仅从CPU的使用率来判断CPU是否处于一种超负荷的工作状态还是不够的,必须结合Load Average来全局的看CPU的使用情况和申请情况。 所以回过头来再看测试部对于Load Average的要求,在我们机器为8个CPU的情况下,控制在10 Load左右,也就是每一个CPU正在处理一个请求,同时还有2个在等待处理。看了看网上很多人的介绍一般来说Load简单的计算就是2* CPU个数减去1-2左右(这个只是网上看来的,未必是一个标准)。 关于Linux系统load average负载的理解 你可能对于 Linux 的负载均值(load averages)已有了充分的了解。负载均值在 uptime 或者 top 命令中可以看到,它们可能会显示成这个样子: 很多人会这样理解负载均值:三个数分别代表不同时间段的系统平均负载(一分钟、五 分钟、以及十五分钟),它们的数字当然是越小越好。数字越高,说明服务器的负载越 大,这也可能是服务器出现某种问题的信号。 而事实不完全如此,是什么因素构成了负载均值的大小,以及如何区分它们目前的状况是 “好”还是“糟糕”?什么时候应该注意哪些不正常的数值? 回答这些问题之前,首先需要了解下这些数值背后的些知识。我们先用最简单的例子说明, 一台只配备一块单核处理器的服务器。 一 只单核的处理器可以形象得比喻成一条单车道。设想下,你现在需要收取这条道路的过桥 费 -- 忙于处理那些将要过桥的车辆。你首先当然需要了解些信息,例如车辆的载重、以及 还有多少车辆正在等待过桥。如果前面没有车辆在等待,那么你可以告诉后面的司机通过。 如果车辆众多,那么需要告知他们可能需要稍等一会。 因此,需要些特定的代号表示目前的车流情况,例如: 上面的情况和处理器的负载情况非常相似。一辆汽车的过桥时间就好比是处理器处理某线程 的实际时间。Unix 系统定义的进程运行时长为所有处理器内核的处理时间加上线程 在队列中等待的时间。 和收过桥费的管理员一样,你当然希望你的汽车(操作)不会被焦急的等待。所以,理想状态 下,都希望负载平均值小于 1.00 。当然不排除部分峰值会超过 1.00,但长此以往保持这 个状态,就说明会有问题,这时候你应该会很焦急。 嗯,这种情况其实并不完全正确。负荷 1.00 说明系统已经没有剩余的资源了。在实际情况中 ,有经验的系统管理员都会将这条线划在 0.70: 哇喔,你有四个处理器的主机?那么它的负载均值在 3.00 是很正常的。 在多处理器系统中,负载均值是基于内核的数量决定的。以 100% 负载计算,1.00 表示单个处理器,而 2.00 则说明有两个双处理器,那么 4.00 就说明主机具有四个处理器。 回到我们上面有关车辆过桥的比喻。1.00 我说过是“一条单车道的道路”。那么在单车道 1.00 情况中,说明这桥梁已经被车塞满了。而在双处理器系统中,这意味着多出了一倍的 负载,也就是说还有 50% 的剩余系统资源 -- 因为还有另外条车道可以通行。 所以,单处理器已经在负载的情况下,双处理器的负载满额的情况是 2.00,它还有一倍的资源可以利用。 先脱离下主题,我们来讨论下多核心处理器与多处理器的区别。从性能的角度上理解,一台主 机拥有多核心的处理器与另台拥有同样数目的处理性能基本上可以认为是相差无几。当然实际 情况会复杂得多,不同数量的缓存、处理器的频率等因素都可能造成性能的差异。 但即便这些因素造成的实际性能稍有不同,其实系统还是以处理器的核心数量计算负载均值 。这使我们有了两个新的法则: 让我们再来看看 uptime 的输出 这是个双核处理器,从结果也说明有很多的空闲资源。实际情况是即便它的峰值会到 1.7,我也从来没有考虑过它的负载问题。 那么,怎么会有三个数字的确让人困扰。我们知道,0.65、0.42、0.36 分别说明上一分钟、最后五分钟以及最后十五分钟的系统负载均值。那么这又带来了一个问题: 我们以哪个数字为准?一分钟?五分钟?还是十五分钟? 其 实对于这些数字我们已经谈论了很多,我认为你应该着眼于五分钟或者十五分钟的平均数 值。坦白讲,如果前一分钟的负载情况是 1.00,那么仍可以说明认定服务器情况还是正常的。 但是如果十五分钟的数值仍然保持在 1.00,那么就值得注意了(根据我的经验,这时候你应 该增加的处理器数量了)。 那么我如何得知我的系统装备了多少核心的处理器? 在 Linux 下,可以使用 获取你系统上的每个处理器的信息。如果你只想得到数字,那么就使用下面的命令: 1 load average 的定义 在特定时间间隔内运行队列中的平均进程数。 2 w 命令查看 load average load average: 1.00, 0.7, 0.8 1分钟 5 分钟 15分钟 其中分别代表1分钟,5分钟,15分钟系统的平均负载。则三个数字,会重点观察5分钟,15分钟对应的数值,这反映了系统一段时间的工作状况。此值低于1.00为正常(注释1),长时间等于1.00需要引起注意,大于5.00说明系统出现严重的 cpu资源不足,随时可能出问题,属于critical级别。 3 load average 与cpu 利用率的区别 3.1 cpu 利用率的查看,top命令 3.2 什么是cpu利用率 单位时间内进程使用cpu时间的百分比 3.3 load average 与cpu 利用率的区别 load average=占用cpu进程+排队进程数 cpu利用率=单位时间内进程使用cpu时间的百分比 load average 表示的是cpu还有多少件事情要处理,cpu利用率表示:一个进程别cpu处理时,占用时间片(注释2)的比值。 注释1:这里指的是1个cpu所对应的负载值。 注释2:在Linux的内核处理过程中,每一个进程默认会有一个固定的时间片来执行命令(默认为1/100秒),这段时间称为时间片。
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用'wait')
- 没有被停止(例如:等待终止)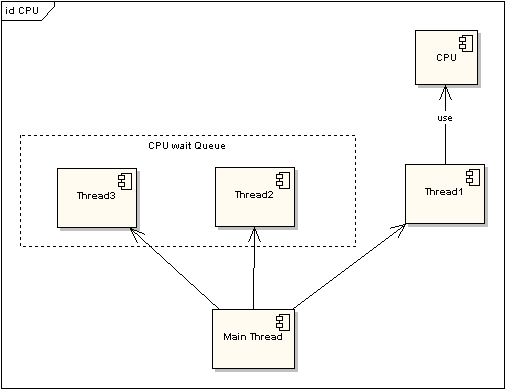
图 1 非时间片线程执行情况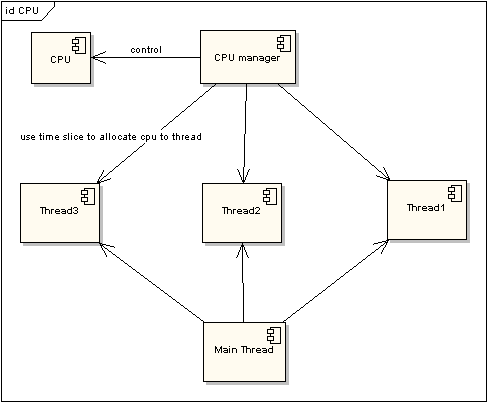
图 2 非时间片线程执行情况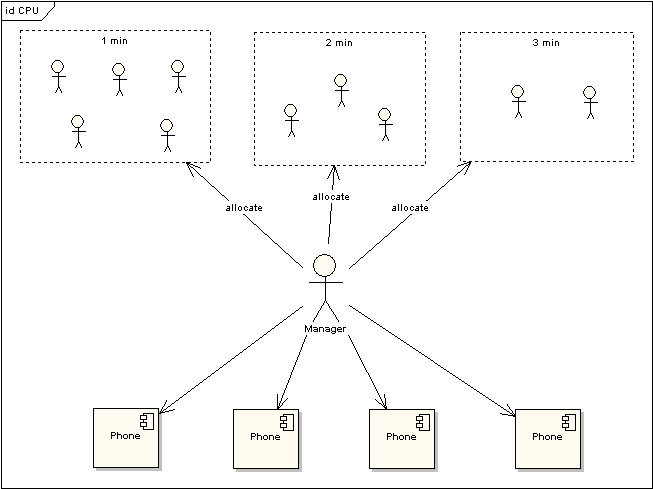
图 3 电话使用场景
那么多个处理器呢?我的均值是 3.00,但是系统运行正常!
审视我们自己
