分类: LINUX
2013-07-22 14:28:49
一. flume的简介
Flume 是一个分布式、可靠和高可用的服务,用于收集、聚合以及移动大量日志数据,使用一个简单灵活的架构,就流数据模型。这是一个可靠、容错的服务。
二. 关于nginx
理论上原有nginx不用做任何改动。(如果nginx的日志已经按天截断了的话)
三. flume的基本概念
如下图

每个agent都必须具有三个元素,source、channel、sink。
source:数据流的源。产生event。
channel:可以理解成数据流的管道。传递event
sink : 数据流的终点。消耗event
注:source可以上一节点的sink,sink可以指定为下一节点的source。比较常见的场景如下图
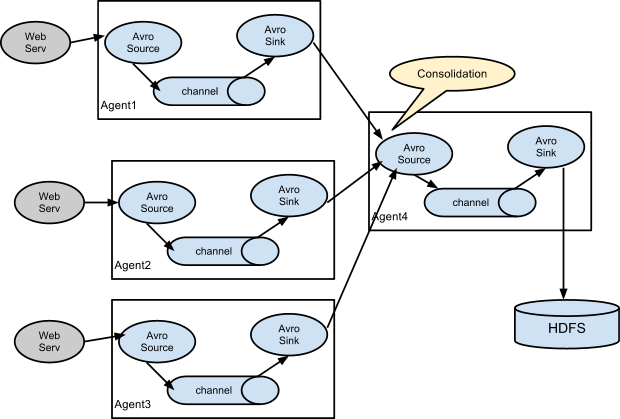
四.环境
4台nginx服务器对外提供服务。日志产生于本机(之前用udp的rsyslog收集时丢失日志现象比较严重)。并储存于本机固定位置。截断功能通过crontab 零点执行shell脚本进行。
五.方案制定
为以收集日志,并做实时的集中存储,元素相应类型如下
1.source : client端使用exec类型,通过tail –F 产生event。server端使用avro类型,用于接收client端发出的event
2.channel : 使用file类型。(测试期使用了mem类似)
3. sink: client端使用avro类型,传递给server端。server端使用file_roll类型,指定相应目录储存日志。最终方案会使用hdfs

六. 实施
1.flume的部署
下载、解压到相应位置即可,没具体要求。下以/usr/local/flume/ 为例
2.配置agent端
flume允许对环境资源使用做设置,需要修改配置,/PREFIX/conf/flume-env.sh 可以通过实际情况进行调整
配置(/PREFIX/conf/XXX.properties)
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# Describe/configure the source
a1.sources.r1.type = exec
#a1.sources.r1.command = tail -n 0 -F /tmp/1
a1.sources.r1.command = tail -n 0 -F /var/log/access.guang.j.cn.log
a1.sources.r1.channels = c1
# Describe/configure the channels (后面有file channel配置方案)
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Describe/configure the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = 192.168.1.35
a1.sinks.k1.port = 44444
a1.sinks.k1.channel = c1
3.配置server端
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
# Describe the sink (后面有hdfs方式)
a1.sinks.k1.type = file_roll
a1.sinks.k1.sink.directory = /tmp/test
a1.sinks.k1.sink.rollInterval = 3600
# Use a channel which buffers events in memory (后面有file channel配置方案)
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动(client 和server端只有配置文件不同)
cd /PREFIX
./flume-ng agent -n a1 -c ../conf -f ../conf/XXXX.properties 2>/dev/null &
经测试mem的channel并不支持在远端失效后的本地存储。所以只能使用file的方式
配置如下(主/从 相同)
# Describe/configure the channels
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /PREFIX/flume/checkpoint
a1.channels.c1.useDualCheckpoints = true
a1.channels.c1.backupCheckpointDir = /PREFIX/flume/backupcheckpoint
a1.channels.c1.dataDirs = /PREFIX/flume/data
hdfs sink的配置
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /PREFIX/nginx/%Y%m%d
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.filePrefix = access.DOMAIN
a1.sinks.k1.hdfs.inUseSuffix = .tmp
a1.sinks.k1.hdfs.idleTimeout = 300
以上配置1小时自动释放一次。可理解成每小时截断一次。因为hadoop目录使用日志变量,在某文件空闲5分钟后自己释放。
另附启停脚本
#!/bin/bash
PREFIX="/usr/local/flume"
AGENT="a1"
start(){
echo starting
ps aux |grep -v grep|grep $PREFIX -q
if [ $? -eq 0 ];then
echo flume is already running
exit 1
fi
cd $PREFIX
bin/flume-ng agent -n $AGENT -c conf -f conf/guang-client.properties 2>/dev/null &
}
stop(){
ps aux |grep -v grep|grep $PREFIX -q
if [ $? -ne 0 ];then
echo flume is not running
else
ps aux |grep -v grep|grep $PREFIX|awk '{print $2}'|xargs kill -15
sleep 3
ps aux |grep -v grep|grep $PREFIX -q
[ $? -eq 0 ] && ps aux |grep flume|grep -v grep|awk '{print $2}'|xargs kill -9
fi
}
status(){
ps aux |grep -v grep|grep $PREFIX -q
if [ $? -eq 0 ];then
echo flume is running
else
echo flume is not running
fi
}
case $1 in
start)
start
;;
stop)
stop
;;
restart)
stop
sleep 1
start
;;
status)
status
;;
*)
echo "Useage : $0 [start|stop|restat|status]"
;;
esac
