分类: LINUX
2010-10-28 01:18:09
 |
|
 |
|
我发现目前所有的HOWTO都缺乏Linux 2.4.x 内核中的Iptables和Netfilter 函数的信息,于是我试图回答一些问题,比如状态匹配。我会用插图和例子 加以说明,此处的例子可以在你的/etc/rc.d/使用。最初这篇文章是以HOWTO文档的形式书写的,因为许多人只接受HOWTO文档。
还有一个小脚本,我写它只是为使你在配置它的时候能象我一样有成功的感觉。
我请教了Marc Boucher 及netfilter团队的其他核心成员。对他们的工作以及对我在为boingworld.com 书写这个指南时的帮助表示极大的谢意,现在这个指南在我自己的站点frozentux.net上进行维护。这个文档将一步一步教你setup过程,让你对iptables包有更多的了解。这大部分的东西都基于例子rc.firewall 文件,因为我发现这是学习iptables的一个好方法。我决定自顶向下地跟随rc.firewall 文件来学习 iptables。虽然这样会困难一些,但更有逻辑。当你碰到不懂的东西时再来查看这个文件。
文中包含了一些术语,你应该有所了解。这里有一些解释,并说明了本文中如何使用它们。
DNAT - Destination Network Address Translation 目的网络地址转换。 DNAT是一种改变数据包目的 ip地址的技术,经常和SNAT联用,以使多台服务器能共享一个ip地址连入Internet,并且继续服务。通过对同一个ip地址分配不同的端口,来决定数据的流向。
Stream - 流 是指发送和接收的数据包和通信的双方都有关系的一种连接(译者注:本文中,作者把连接看作是单向的,流表示双向的连接)。一般的,这个词用于描述在两个方向上发送两个或三个数据包的连接。对于TCP,流意味着连接,它发送了一个SYN,然后又回复SYN/ACK。但也可能是指这样的连接,发送一个SYN,回复ICMP主机不可达信息。换句话说,我使用这个词很随意。
SNAT - Source Network Address Translation源网络地址转换。这是一种改变数据包源ip地址的技术,经常用来使多台计算机分享一个Internet地址。这只在IPv4中使用,因为IPv4的地址已快用完了,IPv6将解决这个问题。
State - 状态 指明数据包处于什么状态。状态在中定义,或由用户在Netfilter/iptables中自定义。需要注意的是Netfilter设定了一些关于连接和数据包的状态,但没有完全使用使用RFC 793的定义。
User space - 用户空间,指在内核外部或发生在内核外部的任何东西。例如,调用 iptables -h 发生在内核外部,但iptables -A FORWARD -p tcp -j ACCEPT (部分地)发生在内核内部,因为一条新的规则加入了规则集。
Kernel space - 内核空间 ,与用户空间相对,指那些发生在内核内部。
Userland - 参见用户空间
target - 这个词在后文中有大量的应用,它表示对匹配的数据包所做的操作。
这一章是学习iptables的开始,它将帮助你理解Netfilter和iptables在Linux中扮演的角色。它会告诉你如何配置、安装防火墙,你的经验也会随之增长。当然,要想达到你的目标,是要花费时间,还要有毅力。( 译者注:听起来很吓人的:) )
iptables 可以从下载,网站中的FAQs也是很好的教程。iptables 也使用一些内核空间,可以在用make configure配置内核的过程中配置,下面会介绍必要的步骤。
为了运行iptables,需要在内核配置期间,选择以下一些选项,不管你用make config或其他命令。
CONFIG_PACKET - 允许程序直接访问网络设备(译者注:最常用的就是网卡了),象tcpdump 和 snort就要使用这个功能。
 |
严格地说,iptables并不需要CONFIG_PACKET,但是它有很多用处(译者注:其他程序需要),所以就选上了。当然,你不想要,不选就是了。(译者注:建议还是选的为好) |
CONFIG_NETFILTER - 允许计算机作为网关或防火墙。这个是必需的,因为整篇文章都要用到这个功能。我想你也需要这个,谁叫你学iptables呢:)
当然,你要给网络设备安装正确的驱动程序,比如,Ethernet 网卡, PPP 还有 SLIP 。 上面的选项,只是在内核中建立了一个框架, iptables确实已经可以运行,但不能做任何实质性的工作。我们需要更多的选项。以下给出内核2.4.9的选项和简单的说明:
CONFIG_IP_NF_CONNTRACK - 连接跟踪模块,用于 NAT(网络地址转换) 和 Masquerading(ip地址伪装),当然,还有其他应用。如果你想把LAN中的一台机子作为防火墙,这个模块你算选对了。脚本 要想正常工作,就必需有它的存在。
CONFIG_IP_NF_FTP - 这个选项提供针对FTP连接进行连接跟踪的功能。一般情况下,对FTP连接进行连接跟踪是很困难的,要做到这一点,需要一个名为helper的动态链接库。此选项就是用来编译helper的。如果没有这个功能,就无法穿越防火墙或网关使用FTP。
CONFIG_IP_NF_IPTABLES - 有了它,你才能使用过滤、伪装、NAT。它为内核加入了iptables标识框架。没有它,iptables毫无作用。
CONFIG_IP_NF_MATCH_LIMIT - 此模块并不是十分必要,但我在例子中用到了。它提供匹配LIMIT的功能,以便于使用一个适当的规则来控制每分钟要匹配的数据包的数量。比如, -m limit --limit 3/minute 的作用是每分钟最多匹配三个数据包。这个功能也可用来消除某种DoS攻击。
CONFIG_IP_NF_MATCH_MAC - 选择这个模块,可以根据MAC地址匹配数据包。例如,我们想要阻塞使用了某些MAC地址的数据包,或阻塞某些计算机的通信,用这个很容易。因为每个Ethernet网卡都有它自己的MAC地址,且几乎从不会改变。但我在中没有用到这个功能,其他例子也未用到。(译者注:这又一次说明了学习是为将来打基础:) )
CONFIG_IP_NF_MATCH_MARK - 这个选项用来标记数据包。对数据包做 MARK(标记)操作,我们就可以在后面的表中用这个标记来匹配数据包。后文有详细的说明。
CONFIG_IP_NF_MATCH_MULTIPORT - 选择这个模块我们可以使用端口范围来匹配数据包,没有它,是无法做到这一点的。
CONFIG_IP_NF_MATCH_TOS - 使我们可以设置数据包的TOS(Type Of Service 服务类型)。这个工作也可以用命令ip/tc完成,还可在mangle表中用某种规则设定。
CONFIG_IP_NF_MATCH_TCPMSS - 可以基于MSS匹配TCP数据包。
CONFIG_IP_NF_MATCH_STATE - 相比较ipchains 这是最大的更新,有了它,我们可以对数据包做状态匹配。比如,在某个TCP连接的两个方向上已有通信,则这个连接上的数据包就被看作ESTABLISHED(已建立连接)状态。在 里大量使用了此模块的功能。
CONFIG_IP_NF_MATCH_UNCLEAN - 匹配那些不符合类型标准或无效的 P、TCP、UDP、ICMP数据包(译者注:之所以此模块名为UNCLEAN,可以这样理解,凡不是正确模式的包都是脏的。这有些象操作系统内存管理中的“脏页”,那这里就可以称作“脏包”了,自然也就UNCLEAN了)。我们一般丢弃这样的包,但不知这样做是否正确。另外要注意,这种匹配功能还在实验阶段,可能会有些问题。
CONFIG_IP_NF_MATCH_OWNER - 根据套接字的拥有者匹配数据包。比如,我们只允许root访问Internet。在iptables中,这个模块最初只是用一个例子来说明它的功能。同样,这个模块也处于实验阶段,还无法使用。
CONFIG_IP_NF_FILTER - 这个模块为iptables添加基本的过滤表,其中包含INPUT、FORWARD、OUTPUT链。通过过滤表可以做完全的IP过滤。只要想过滤数据包,不管是接收的还是发送的,也不管做何种过滤,都必需此模块。
CONFIG_IP_NF_TARGET_REJECT - 这个操作使我们用ICMP错误信息来回应接收到的数据包,而不是简单地丢弃它。有些情况必须要有回应的,比如,相对于ICMP和UDP来说,要重置或拒绝TCP连接总是需要一个TCP RST包。
CONFIG_IP_NF_TARGET_MIRROR - 这个操作使数据包返回到发送它的计算机。例如,我们在INPUT链里对目的端口为HTTP的包设置了MIRROR操作,当有人访问HTTP时,包就被发送回原计算机,最后,他访问的可能是他自己的主页。(译者注:应该不难理解为什么叫做MIRROR了)
CONFIG_IP_NF_NAT - 顾名思义,本模块提供NAT功能。这个选项使我们有权访问nat表。端口转发和伪装是必需此模块的。当然,如果你的LAN里的所有计算机都有唯一的有效的 IP地址,那在做防火墙或伪装时就无须这个选项了。是需要的:)
CONFIG_IP_NF_TARGET_MASQUERADE - 提供MASQUERADE(伪装)操作。如果我们不知道连接Internet的IP,首选的方法就是使用MASQUERADE,而不是DNAT或SNAT。换句话说,就是如果我们使用PPP或SLIP等连入Internet,由DHCP或其他服务分配IP,使用这个比SNAT好。因为MASQUERADE 不需要预先知道连接Internet的IP,虽然对于计算机来说MASQUERADE要比NAT的负载稍微高一点。
CONFIG_IP_NF_TARGET_REDIRECT - 这个操作和代理程序一起使用是很有用的。它不会让数据包直接通过,而是把包重新映射到本地主机,也就是完成透明代理。
CONFIG_IP_NF_TARGET_LOG - 为iptables增加 LOG(日志)操作。通过它,可以使用系统日志服务记录某些数据包,这样我们就能了解在包上发生了什么。这对于我们做安全审查、调试脚本的帮助是无价的。
CONFIG_IP_NF_TARGET_TCPMSS - 这个选项可以对付一些阻塞ICMP分段信息的ISP(服务提供商)或服务。没有ICMP分段信息,一些网页、大邮件无法通过,虽然小邮件可以,还有,在握手完成之后,ssh可以但scp不能工作。我们可以用TCPMSS解决这个问题,就是使MSS(Maximum Segment Size)被钳制于PMTU(Path Maximum Transmit Unit)。这个方法可以处理被Netfilter开发者们在内核配置帮助中称作“criminally brain-dead ISPs or servers”的问题。
CONFIG_IP_NF_COMPAT_IPCHAINS - ipchains 的,这只是为内核从2.2转换到2.4而使用的,它会在2.6中删除。
CONFIG_IP_NF_COMPAT_IPFWADM - 同上,这只是 ipfwadm的暂时使用的兼容模式。
上面,我简要介绍了很多选项,但这只是内核2.4.9中的。要想看看更多的选项,建议你去Netfilter 看看patch-o-matic。在那里,有其他的一些选项。POM可能会被加到内核里,当然现在还没有。这有很多原因,比如,还不稳定,Linus Torvalds没打算或没坚持要把这些补丁放入主流的内核,因为它们还在实验。
把以下选项编译进内核或编译成模块,才能使用。
CONFIG_PACKET
CONFIG_NETFILTER
CONFIG_IP_NF_CONNTRACK
CONFIG_IP_NF_FTP
CONFIG_IP_NF_IRC
CONFIG_IP_NF_IPTABLES
CONFIG_IP_NF_FILTER
CONFIG_IP_NF_NAT
CONFIG_IP_NF_MATCH_STATE
CONFIG_IP_NF_TARGET_LOG
CONFIG_IP_NF_MATCH_LIMIT
CONFIG_IP_NF_TARGET_MASQUERADE
以上是为保证 正常工作而需要的最少的选项。其他脚本需要的选项,在相应的章节里都有说明。目前,我们只需注意要学习的这个脚本。
下面,我们来看看如何编译iptables。iptables很多组件的配置、编译是与内核的配置、编译相关联的,了解这一点是很重要的。某些Linux产品预装了iptables,比如Red Hat,但是它的缺省设置是不启用iptables的。后文我们会介绍如何启用它,也会介绍一下其他 Linux产品里的iptables情况。
首先要解压iptables包。这里,我用iptables 1.2.6a做例子(译者注:在我翻译时,最新版本已经是 1.2.9,其中又有了不少改进,修补了一些bug,增添了几个match和target。)。命令 bzip2 -cd iptables-1.2.6a.tar.bz2 | tar -xvf -(当然也可以用tar -xjvf iptables-1.2.6a.tar.bz2,但这个命令可能对一些老版的tar不适用 ) 将压缩包解压至目录iptables-1.2.6a,其中的INSTALL文件有很多对编译、运行有用的信息。
这一步,你将配置、安装一些额外的模块,也可以为内核增加一些选项。我们这里只是检查、安装一些未被纳入内核的标准的补丁。当然,更多的在实验阶段的补丁,仅在进行其他某些操作时才会用到。
|
有一些补丁仅仅处在实验阶段,把它们也安装上不是一个好主意。这一步,你会遇到很多十分有趣的匹配和对数据包的操作,但它们还正在实验。 为了完成这一步,我们要在iptables的目录内用到如下一些命令: |
make pending-patches KERNEL_DIR=/usr/src/linux/
变量KERNEL_DIR指向内核原码的真实路径。一般情况下,都是/usr/src/linux/ ,但也会不一样,这要看你所用的Linux产品了。
|
总之,只有某些补丁会被询问是否加入内核,而Netfilter的开发者们有大量的补丁或附件想要加入内核,但还要再实验一阵子才能做到。如果你想安装这些东西,就用下面的命令: |
make most-of-pom KERNEL_DIR=/usr/src/linux/
这个命令会安装部分patch-o-matic(netfilter世界对补丁的称呼),忽略掉的是非常极端的那一部分,它们可能会对内核造成严重的破坏。你要知道这个命令的作用,要了解它们对内核原码的影响,好在在你选用之前,会有所提示。下面的命令可以安装所有的patch-o-matic(译者注:一定要小心哦)。
make patch-o-matic KERNEL_DIR=/usr/src/linux/
要仔细的读读每一个补丁的帮助文件,因为有些patch-o-matic会损坏内核,而有些对其他补丁有破坏作用。
|
你要是不打算用patch-o-matic修补内核,以上的命令都用不着,它们不是必需的。不过,你可以用这些命令来看看有什么有趣的玩意儿,这不会影响任何东西。 |
安装好patch-o-matic,现在应该重新编译内核了,因为其中增加了一些补丁。但别忘了重新配置内核,现有的配置文件里可没有你增加的补丁的信息。当然,你也可以先编译iptables , 再来编译内核。
接下来就该编译iptables了,用下面这个简单的命令:
make KERNEL_DIR=/usr/src/linux/
iptables应该编译好了,如果不行,好好考虑考虑问题在哪儿,要么订阅,那里可能有人能帮助你。
一切顺利的话,我们该安装iptables了,这几乎不会有什么问题的。我们用下面的命令来完成这一步:
make install KERNEL_DIR=/usr/src/linux/
现在大功告成了。如果你在前面没有重新编译、安装内核,现在就要做了,不然,你还是不能使用更新后的iptables。好好看看INSTALL吧,那里面有详细的安装信息。
Red Hat 7.1使用2.4.x的内核,支持Netfilter和iptables。Red Hat包含了所有基本的程序和需要的配置文件,但缺省使用的是B class=COMMAND>ipchains。“iptables为什么不能用”是最常见的问题,下面就让我们就来说说如何关闭ipchains而起用iptables 。
|
Red Hat 7.1预装的iptables版本有些老了,在使用之前,你可能想装个新的,再自己编译一下内核。 |
我们先要关闭ipchains,并且不想再让它运行起来,做到这一点,要更改目录/etc/rc.d/下的一些文件名。用以下命令完成:
chkconfig --level 0123456 ipchains off
这个命令把所有指向/etc/rc.d/init.d/ipchains的软连接改名为 K92ipchains。以S开头表示,在启动时会由初始化脚本运行此脚本。改为K开头后,就表示终止服务,或以后在启动时不再运行。这样,ipchains以后不会再开机就运行了。
要想终止正在运行的服务,要用service命令。终止ipchains 服务的命令是:
service ipchains stop
现在,我们可以启动iptables服务了。首先,要确定在哪个运行层运行,一般是 2,3和5,这些层有不同的用处:
2. 不带NFS的多用户环境,和层3的区别仅在于不带网络支持。
3. 多用户环境,就是我们一般事用的层。
5. X11,图形界面。
用下面的命令以使iptables能在这些层运行:
chkconfig --level 235 iptables on
你也可以使用这个命令使iptables能在其他层运行。但没这个必要,因为层1是单用户模式,一般用在维修上;层4保留不用;层6用来关闭计算机。
启动iptables用:
service iptables start
在脚本iptables里还没有定义规则。在Red Hat 7.1中添加规则的方法有二:第一个方法是编辑/etc/rc.d/init.d/iptables,要注意在用RPM升级iptables时,已有的规则可能会被删除。另一个方法是先装载规则,然后用命令iptables-save把规则保存到文件中,再由目录rc.d下的脚本(/etc/rc.d/init.d/iptables)自动装载。
我们先来说明如何利用“剪切粘贴大法”设置/etc/rc.d/init.d/iptables。为了能在计算机启动iptables时装载规则,可以把规则放在“start)”节或函数start()中。注意:如果把规则放在“start)”节里,则不要在“start)”节里运行start(),还要编辑“stop)”节,以便在关机时或进入一个不需要iptables的层时,脚本知道如何处理。还应检查“restart”节和“condrestart”节的设置。一定要注意,我们所做的改动在升级iptables时可能会被删除,而不管是通过Red Hat网络自动升级还是用 RPM升级。
下面介绍第二种方法:先写一个规则的脚本,或直接用iptables命令生成规则。规则要适合自己的需要,别忘了实验一下是否有问题,确认正常之后,使用命令iptables-save来保存规则。一般用iptables-save > /etc/sysconfig/iptables生成保存规则的文件 /etc/sysconfig/iptables,也可以用service iptables save,它能把规则自动保存在/etc/sysconfig/iptables中。当计算机启动时,rc.d下的脚本将用命令iptables-restore调用这个文件,从而就自动恢复了规则。
以上两种方法最好不要混用,以免用不同方法定义的规则互相影响,甚至使防火墙的设置无效。
至此,可以删除预装的ipchains和iptables了,这样可以避免新旧版本的iptables之间的冲突。其实,只有当你从原码安装时,才需要这样做。但一般来说,也不会出现互相影响的问题,因为基于rpm的包不使用原码的缺省目录。删除用以下命令:
rpm -e iptables
既然不用ipchains为什么要保留呢?删吧!命令如下:
rpm -e ipchains
历经磨难,胜利终于到来了。你已经能够从源码安装iptables了。那些老版的东西就删掉吧。
这一章我们来讨论数据包是以什么顺序、如何穿越不同的链和表的。稍后,在你自己写规则时,就会知道这个顺序是多么的重要。一些组件是iptables与内核共用的,比如,数据包路由的判断。了解到这一点是很重要的,尤其在你用iptables改变数据包的路由时。这会帮助你弄明白数据包是如何以及为什么被那样路由,一个好的例子是DNAT和SNAT,不要忘了TOS的作用。
当数据包到达防火墙时,如果MAC地址符合,就会由内核里相应的驱动程序接收,然后会经过一系列操作,从而决定是发送给本地的程序,还是转发给其他机子,还是其他的什么。
我们先来看一个以本地为目的的数据包,它要经过以下步骤才能到达要接收它的程序:
下文中有个词mangle,我实在没想到什么合适的词来表达这个意思,只因为我的英语太差!我只能把我理解的写出来。这个词表达的意思是,会对数据包的一些传输特性进行修改,在mangle表中允许的操作是 TOS、TTL、MARK。也就是说,今后只要我们见到这个词能理解它的作用就行了。
Table 3-1. 以本地为目标(就是我们自己的机子了)的包
| Step(步骤) | Table(表) | Chain(链) | Comment(注释) |
|---|---|---|---|
| 1 | 在线路上传输(比如,Internet) | ||
| 2 | 进入接口 (比如, eth0) | ||
| 3 | mangle | PREROUTING | 这个链用来mangle数据包,比如改变TOS等 |
| 4 | nat | PREROUTING | 这个链主要用来做DNAT。不要在这个链做过虑操作,因为某些情况下包会溜过去。 |
| 5 | 路由判断,比如,包是发往本地的,还是要转发的。 | ||
| 6 | mangle | INPUT | 在路由之后,被送往本地程序之前,mangle数据包。 |
| 7 | filter | INPUT | 所有以本地为目的的包都要经过这个链,不管它们从哪儿来,对这些包的过滤条件就设在这里。 |
| 8 | 到达本地程序了(比如,服务程序或客户程序) |
注意,相比以前(译者注:就是指ipchain)现在数据包是由INPUT链过,而不是FORWARD链。这样更符合逻辑。刚看上去可能不太好理解,但仔细想想就会恍然大悟的。
现在我们来看看源地址是本地器的包要经过哪些步骤:
Table 3-2. 以本地为源的包
| Step | Table | Chain | Comment |
|---|---|---|---|
| 1 | 本地程序(比如,服务程序或客户程序) | ||
| 2 | 路由判断,要使用源地址,外出接口,还有其他一些信息。 | ||
| 3 | mangle | OUTPUT | 在这儿可以mangle包。建议不要在这儿做过滤,可能有副作用哦。 |
| 4 | nat | OUTPUT | 这个链对从防火墙本身发出的包进行DNAT操作。 |
| 5 | filter | OUTPUT | 对本地发出的包过滤。 |
| 6 | mangle | POSTROUTING | 这条链主要在包DNAT之后(译者注:作者把这一次DNAT称作实际的路由,虽然在前面有一次路由。对于本地的包,一旦它被生成,就必须经过路由代码的处理,但这个包具体到哪儿去,要由NAT代码处理之后才能确定。所以把这称作实际的路由。),离开本地之前,对包 mangle。有两种包会经过这里,防火墙所在机子本身产生的包,还有被转发的包。 |
| 7 | nat | POSTROUTING | 在这里做SNAT。但不要在这里做过滤,因为有副作用,而且有些包是会溜过去的,即使你用了DROP策略。 |
| 8 | 离开接口(比如: eth0) | ||
| 9 | 在线路上传输(比如,Internet) |
在这个例子中,我们假设一个包的目的是另一个网络中的一台机子。让我们来看看这个包的旅程:
Table 3-3. 被转发的包
| Step | Table | Chain | Comment |
|---|---|---|---|
| 1 | 在线路上传输(比如,Internet) | ||
| 2 | 进入接口(比如, eth0) | ||
| 3 | mangle | PREROUTING | mangle数据包,,比如改变TOS等。 |
| 4 | nat | PREROUTING | 这个链主要用来做DNAT。不要在这个链做过虑操作,因为某些情况下包会溜过去。稍后会做SNAT。 |
| 5 | 路由判断,比如,包是发往本地的,还是要转发的。 | ||
| 6 | mangle | FORWARD | 包继续被发送至mangle表的FORWARD链,这是非常特殊的情况才会用到的。在这里,包被mangle(还记得mangle的意思吗)。这次mangle发生在最初的路由判断之后,在最后一次更改包的目的之前(译者注:就是下面的FORWARD链所做的,因其过滤功能,可能会改变一些包的目的地,如丢弃包)。 |
| 7 | filter | FORWARD | 包继续被发送至这条FORWARD链。只有需要转发的包才会走到这里,并且针对这些包的所有过滤也在这里进行。注意,所有要转发的包都要经过这里,不管是外网到内网的还是内网到外网的。在你自己书写规则时,要考虑到这一点。 |
| 8 | mangle | POSTROUTING | 这个链也是针对一些特殊类型的包(译者注:参考第6步,我们可以发现,在转发包时,mangle表的两个链都用在特殊的应用上)。这一步mangle是在所有更改包的目的地址的操作完成之后做的,但这时包还在本地上。 |
| 9 | nat | POSTROUTING | 这个链就是用来做SNAT的,当然也包括Masquerade(伪装)。但不要在这儿做过滤,因为某些包即使不满足条件也会通过。 |
| 10 | 离开接口(比如: eth0) | ||
| 11 | 又在线路上传输了(比如,LAN) |
就如你所见的,包要经历很多步骤,而且它们可以被阻拦在任何一条链上,或者是任何有问题的地方。我们的主要兴趣是iptables的概貌。注意,对不同的接口,是没有什么特殊的链和表的。所有要经防火墙/ 路由器转发的包都要经过FORWARD链。
 |
在上面的情况里,不要在INPUT链上做过滤。INPUT是专门用来操作那些以我们的机子为目的地址的包的,它们不会被路由到其它地方的。 |
现在,我们来看看在以上三种情况下,用到了哪些不同的链。图示如下:
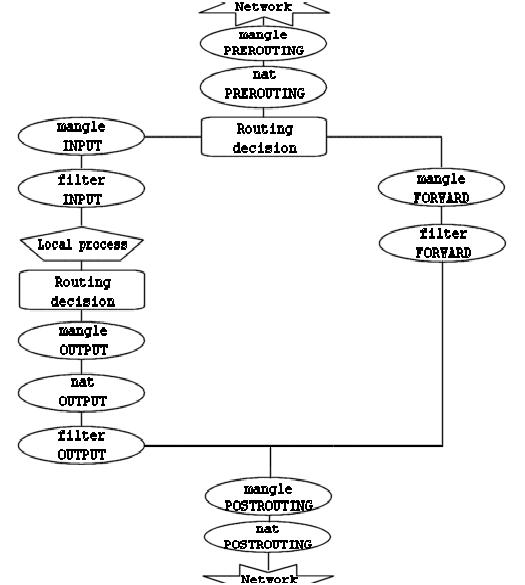
要弄清楚上面的图,可以这样考虑。在第一个路由判断处,不是发往本地的包,我们会发送它穿过 FORWARD链。若包的目的地是本地监听的IP地址,我们就会发送这个包穿过INPUT链,最后到达本地。
值得注意的是,在做NAT的过程中,发往本机的包的目的地址可能会在PREROUTING链里被改变。这个操作发生在第一次路由之前,所以在地址被改变之后,才能对包进行路由。注意,所有的包都会经过上图中的某一条路径。如果你把一个包DNAT回它原来的网络,这个包会继续走完相应路径上剩下的链,直到它被发送回原来的网络。
 |
想要更多的信息,可以看看,这个脚本包括了一些规则,它们会向你展示包是怎样通过各个表和链的。 |
这个表主要用来mangle包,你可以使用mangle匹配来改变包的TOS等特性。
|
强烈建议你不要在这个表里做任何过滤,不管是DANT,SNAT或者Masquerade。 |
以下是mangle表中仅有的几种操作:
TOS
TTL
MARK
TOS操作用来设置或改变数据包的服务类型域。这常用来设置网络上的数据包如何被路由等策略。注意这个操作并不完善,有时得不所愿。它在Internet上还不能使用,而且很多路由器不会注意到这个域值。换句话说,不要设置发往Internet的包,除非你打算依靠TOS来路由,比如用iproute2。
TTL操作用来改变数据包的生存时间域,我们可以让所有数据包只有一个特殊的TTL。它的存在有一个很好的理由,那就是我们可以欺骗一些ISP。为什么要欺骗他们呢?因为他们不愿意让我们共享一个连接。那些ISP会查找一台单独的计算机是否使用不同的TTL,并且以此作为判断连接是否被共享的标志。
MARK用来给包设置特殊的标记。iproute2能识别这些标记,并根据不同的标记(或没有标记)决定不同的路由。用这些标记我们可以做带宽限制和基于请求的分类。
此表仅用于NAT,也就是转换包的源或目标地址。注意,就象我们前面说过的,只有流的第一个包会被这个链匹配,其后的包会自动被做相同的处理。实际的操作分为以下几类:
DNAT
SNAT
MASQUERADE
DNAT操作主要用在这样一种情况,你有一个合法的IP地址,要把对防火墙的访问重定向到其他的机子上(比如DMZ)。也就是说,我们改变的是目的地址,以使包能重路由到某台主机。
SNAT改变包的源地址,这在极大程度上可以隐藏你的本地网络或者DMZ等。一个很好的例子是我们知道防火墙的外部地址,但必须用这个地址替换本地网络地址。有了这个操作,防火墙就能自动地对包做SNAT和De-SNAT(就是反向的SNAT),以使LAN能连接到Internet。如果使用类似 192.168.0.0/24这样的地址,是不会从Internet得到任何回应的。因为IANA定义这些网络(还有其他的)为私有的,只能用于LAN内部。
MASQUERADE的作用和MASQUERADE完全一样,只是计算机的负荷稍微多一点。因为对每个匹配的包,MASQUERADE都要查找可用的IP地址,而不象SNAT用的IP地址是配置好的。当然,这也有好处,就是我们可以使用通过PPP、 PPPOE、SLIP等拨号得到的地址,这些地址可是由ISP的DHCP随机分配的。
filter 表用来过滤数据包,我们可以在任何时候匹配包并过滤它们。我们就是在这里根据包的内容对包做DROP或ACCEPT的。当然,我们也可以预先在其他地方做些过滤,但是这个表才是设计用来过滤的。几乎所有的target都可以在这儿使用。大量具体的介绍在后面,现在你只要知道过滤工作主要是在这儿完成的就行了。
本章将详细介绍状态机制。通读本章,你会对状态机制是如何工作的有一个全面的了解。我们用一些例子来进行说明状态机制。实践出真知嘛。
状态机制是iptables中特殊的一部分,其实它不应该叫状态机制,因为它只是一种连接跟踪机制。但是,很多人都认可状态机制这个名字。文中我也或多或或少地用这个名字来表示和连接跟踪相同的意思。这不应该引起什么混乱的。连接跟踪可以让Netfilter知道某个特定连接的状态。运行连接跟踪的防火墙称作带有状态机制的防火墙,以下简称为状态防火墙。状态防火墙比非状态防火墙要安全,因为它允许我们编写更严密的规则。
在iptables里,包是和被跟踪连接的四种不同状态有关的。它们是NEW,ESTABLISHED,RELATED和INVALID。后面我们会深入地讨论每一个状态。使用--state匹配操作,我们能很容易地控制 “谁或什么能发起新的会话”。
所有在内核中由Netfilter的特定框架做的连接跟踪称作conntrack(译者注:就是connection tracking 的首字母缩写)。conntrack可以作为模块安装,也可以作为内核的一部分。大部分情况下,我们想要,也需要更详细的连接跟踪,这是相比于缺省的conntrack而言。也因为此,conntrack中有许多用来处理TCP, UDP或ICMP协议的部件。这些模块从数据包中提取详细的、唯一的信息,因此能保持对每一个数据流的跟踪。这些信息也告知conntrack流当前的状态。例如,UDP流一般由他们的目的地址、源地址、目的端口和源端口唯一确定。
在以前的内核里,我们可以打开或关闭重组功能。然而,自从iptables和Netfilter,尤其是连接跟踪被引入内核,这个选项就被取消了。因为没有包的重组,连接跟踪就不能正常工作。现在重组已经整合入 conntrack,并且在conntrack启动时自动启动。不要关闭重组功能,除非你要关闭连接跟踪。
除了本地产生的包由OUTPUT链处理外,所有连接跟踪都是在PREROUTING链里进行处理的,意思就是, iptables会在PREROUTING链里从新计算所有的状态。如果我们发送一个流的初始化包,状态就会在OUTPUT链里被设置为NEW,当我们收到回应的包时,状态就会在PREROUTING链里被设置为ESTABLISHED。如果第一个包不是本地产生的,那就会在PREROUTING链里被设置为NEW状态。综上,所有状态的改变和计算都是在nat表中的PREROUTING链和OUTPUT链里完成的。
我们先来看看怎样阅读/proc/net/ip_conntrack里的conntrack记录。这些记录表示的是当前被跟踪的连接。如果安装了ip_conntrack模块,cat /proc/net/ip_conntrack 的显示类似:
tcp 6 117 SYN_SENT src=192.168.1.6 dst=192.168.1.9 sport=32775 \
dport=22 [UNREPLIED] src=192.168.1.9 dst=192.168.1.6 sport=22 \
dport=32775 use=2
conntrack模块维护的所有信息都包含在这个例子中了,通过它们就可以知道某个特定的连接处于什么状态。首先显示的是协议,这里是tcp,接着是十进制的6(译者注:tcp的协议类型代码是6)。之后的117是这条conntrack记录的生存时间,它会有规律地被消耗,直到收到这个连接的更多的包。那时,这个值就会被设为当时那个状态的缺省值。接下来的是这个连接在当前时间点的状态。上面的例子说明这个包处在状态 SYN_SENT,这个值是iptables显示的,以便我们好理解,而内部用的值稍有不同。SYN_SENT说明我们正在观察的这个连接只在一个方向发送了一TCP SYN包。再下面是源地址、目的地址、源端口和目的端口。其中有个特殊的词UNREPLIED,说明这个连接还没有收到任何回应。最后,是希望接收的应答包的信息,他们的地址和端口和前面是相反的。
连接跟踪记录的信息依据IP所包含的协议不同而不同,所有相应的值都是在头文件linux/include/netfilter-ipv4/ip_conntrack*.h中定义的。IP、TCP、UDP、ICMP协议的缺省值是在linux/include/netfilter-ipv4/ip_conntrack.h里定义的。具体的值可以查看相应的协议,但我们这里用不到它们,因为它们大都只在conntrack内部使用。随着状态的改变,生存时间也会改变。
|
最近patch-o-matic里有一个新的补丁,可以把上面提到的超时时间也作为系统变量,这样我们就能够在系统空闲时改变它们的值。以后,我们就不必为了改变这些值而重编译内核了。 这些可通过/proc/sys/net/ipv4/netfilter下的一些特殊的系统调用来改变。仔细看看/proc/sys/net/ipv4/netfilter/ip_ct_*里的变量吧。 |
当一个连接在两个方向上都有传输时,conntrack记录就删除[UNREPLIED]标志,然后重置。在末尾有 [ASSURED]的记录说明两个方向已没有流量。这样的记录是确定的,在连接跟踪表满时,是不会被删除的,没有[ASSURED]的记录就要被删除。连接跟踪表能容纳多少记录是被一个变量控制的,它可由内核中的ip- sysctl函数设置。默认值取决于你的内存大小,128MB可以包含8192条目录,256MB是16376条。你也可以在 /proc/sys/net/ipv4/ip_conntrack_max里查看、设置。
就象前面说的,包的状态依据IP所包含的协议不同而不同,但在内核外部,也就是用户空间里,只有4种状态:NEW,ESTABLISHED,RELATED 和INVALID。它们主要是和状态匹配一起使用。下面就简要地介绍以下这几种状态:
Table 4-1. 数据包在用户空间的状态
| State(状态) | Explanation(注释) |
|---|---|
| NEW | NEW说明这个包是我们看到的第一个包。意思就是,这是conntrack模块看到的某个连接第一个包,它即将被匹配了。比如,我们看到一个SYN 包,是我们所留意的连接的第一个包,就要匹配它。第一个包也可能不是SYN包,但它仍会被认为是NEW状态。这样做有时会导致一些问题,但对某些情况是有非常大的帮助的。例如,在我们想恢复某条从其他的防火墙丢失的连接时,或者某个连接已经超时,但实际上并未关闭时。 |
| ESTABLISHED | ESTABLISHED已经注意到两个方向上的数据传输,而且会继续匹配这个连接的包。处于ESTABLISHED状态的连接是非常容易理解的。只要发送并接到应答,连接就是ESTABLISHED的了。一个连接要从NEW变为ESTABLISHED,只需要接到应答包即可,不管这个包是发往防火墙的,还是要由防火墙转发的。ICMP的错误和重定向等信息包也被看作是ESTABLISHED,只要它们是我们所发出的信息的应答。 |
| RELATED | RELATED是个比较麻烦的状态。当一个连接和某个已处于ESTABLISHED状态的连接有关系时,就被认为是RELATED的了。换句话说,一个连接要想是RELATED的,首先要有一个ESTABLISHED的连接。这个ESTABLISHED连接再产生一个主连接之外的连接,这个新的连接就是RELATED的了,当然前提是conntrack模块要能理解RELATED。ftp是个很好的例子,FTP-data 连接就是和FTP-control有RELATED的。还有其他的例子,比如,通过IRC的DCC连接。有了这个状态,ICMP应答、FTP传输、DCC等才能穿过防火墙正常工作。注意,大部分还有一些UDP协议都依赖这个机制。这些协议是很复杂的,它们把连接信息放在数据包里,并且要求这些信息能被正确理解。 |
| INVALID | INVALID说明数据包不能被识别属于哪个连接或没有任何状态。有几个原因可以产生这种情况,比如,内存溢出,收到不知属于哪个连接的ICMP 错误信息。一般地,我们DROP这个状态的任何东西。 |
这些状态可以一起使用,以便匹配数据包。这可以使我们的防火墙非常强壮和有效。以前,我们经常打开1024以上的所有端口来放行应答的数据。现在,有了状态机制,就不需再这样了。因为我们可以只开放那些有应答数据的端口,其他的都可以关闭。这样就安全多了。
本节和下面的几节,我们来详细讨论这些状态,以及在TCP、UDP和ICMP这三种基本的协议里怎样操作它们。当然,也会讨论其他协议的情况。我们还是从TCP入手,因为它本身就是一个带状态的协议,并且具有很多关于iptables状态机制的详细信息。
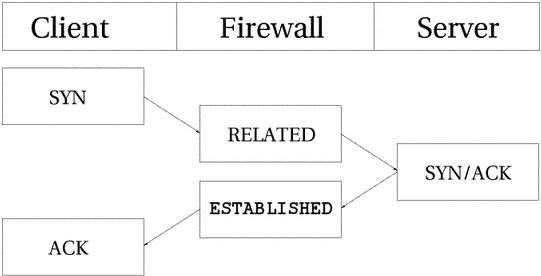
一个TCP连接是经过三次握手协商连接信息才建立起来的。整个会话由一个SYN包开始,然后是一个 SYN/ACK包,最后是一个ACK包,此时,会话才建立成功,能够发送数据。最大的问题在于连接跟踪怎样控制这个过程。其实非常简单。
默认情况下,连接跟踪基本上对所有的连接类型做同样的操作。看看下面的图片,我们就能明白在连接的不同阶段,流是处于什么状态的。就如你看到的,连接跟踪的代码不是从用户的观点来看待TCP连接建立的流程的。连接跟踪一看到SYN包,就认为这个连接是NEW状态,一看到返回的SYN/ACK包,就认为连接是 ESTABLISHED状态。如果你仔细想想第二步,应该能理解为什么。有了这个特殊处理,NEW和ESTABLISHED包就可以发送出本地网络,且只有ESTABLISHED的连接才能有回应信息。如果把整个建立连接的过程中传输的数据包都看作NEW,那么三次握手所用的包都是NEW状态的,这样我们就不能阻塞从外部到本地网络的连接了。因为即使连接是从外向内的,但它使用的包也是NEW状态的,而且为了其他连接能正常传输,我们不得不允许NEW状态的包返回并进入防火墙。更复杂的是,针对TCP连接内核使用了很多内部状态,它们的定义在 的21-23页。但好在我们在用户空间用不到。后面我们会详细地介绍这些内容。
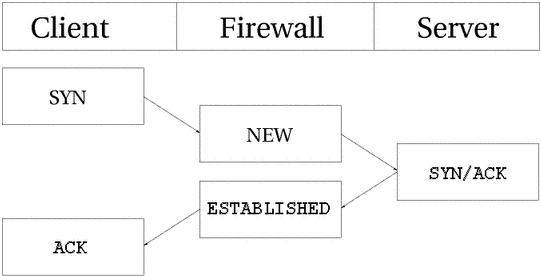
正如你看到的,以用户的观点来看,这是很简单的。但是,从内核的角度看这一块还有点困难的。我们来看一个例子。认真考虑一下在/proc/net/ip_conntrack里,连接的状态是如何改变的。
tcp 6 117 SYN_SENT src=192.168.1.5 dst=192.168.1.35 sport=1031 \
dport=23 [UNREPLIED] src=192.168.1.35 dst=192.168.1.5 sport=23 \
dport=1031 use=1
从上面的记录可以看出,SYN_SENT状态被设置了,这说明连接已经发出一个SYN包,但应答还没发送过来,这可从[UNREPLIED]标志看出。
tcp 6 57 SYN_RECV src=192.168.1.5 dst=192.168.1.35 sport=1031 \
dport=23 src=192.168.1.35 dst=192.168.1.5 sport=23 dport=1031 \
use=1
现在我们已经收到了相应的SYN/ACK包,状态也变为SYN_RECV,这说明最初发出的SYN包已正确传输,并且SYN/ACK包也到达了防火墙。 这就意味着在连接的两方都有数据传输,因此可以认为两个方向都有相应的回应。当然,这是假设的。
tcp 6 431999 ESTABLISHED src=192.168.1.5 dst=192.168.1.35 \
sport=1031 dport=23 src=192.168.1.35 dst=192.168.1.5 \
sport=23 dport=1031 use=1
现在我们发出了三步握手的最后一个包,即ACK包,连接也就进入ESTABLISHED状态了。再传输几个数据包,连接就是[ASSURED]的了。
下面介绍TCP连接在关闭过程中的状态。
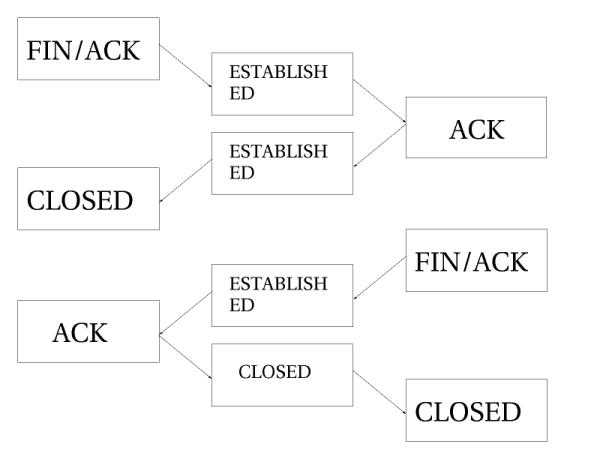
如上图,在发出最后一个ACK包之前,连接(指两个方向)是不会关闭的。注意,这只是针对一般的情况。连接也可以通过发送关闭,这用在拒绝一个连接的时候。在RST包发送之后,要经过预先设定的一段时间,连接才能断掉。
连接关闭后,进入TIME_WAIT状态,缺省时间是2分钟。之所以留这个时间,是为了让数据包能完全通过各种规则的检查,也是为了数据包能通过拥挤的路由器,从而到达目的地。
如果连接是被RST包重置的,就直接变为CLOSE了。这意味着在关闭之前只有10秒的默认时间。RST包是不需要确认的,它会直接关闭连接。针对TCP连接,还有其他一些状态我们没有谈到。下面给出一个完整的状态列表和超时值。
Table 4-2. 内部状态
| State | Timeout value |
|---|---|
| NONE | 30 minutes |
| ESTABLISHED | 5 days |
| SYN_SENT | 2 minutes |
| SYN_RECV | 60 seconds |
| FIN_WAIT | 2 minutes |
| TIME_WAIT | 2 minutes |
| CLOSE | 10 seconds |
| CLOSE_WAIT | 12 hours |
| LAST_ACK | 30 seconds |
| LISTEN> | 2 minutes |
这些值不是绝对的,可以随着内核的修订而变化,也可以通过/proc/sys/net/ipv4/netfilter/ip_ct_tcp_*的变量更改。这些默认值都是经过实践检验的。它们的单位是jiffies(百分之一秒),所以3000就代表30秒。
|
注意状态机制在用户空间里的部分不会查看TCP包的标志位(也就是说TCP标志对它而言是透明的)。如果我们想让NEW状态的包通过防火墙,就要指定NEW状态,我们理解的NEW状态的意思就是指SYN包,可是iptables又不查看这些标志位。这就是问题所在。有些没有设置SYN或ACK的包,也会被看作NEW状态的。这样的包可能会被冗余防火墙用到,但对只有一个防火墙的网络是很不利的(可能会被攻击哦)。那我们怎样才能不受这样的包的影响呢?你可以使用 里的命令。还有一个办法,就是安装patch-o-matic里的tcp-window-tracking扩展功能,它可以使防火墙能根据TCP的一些标志位来进行状态跟踪。 |
UDP连接是无状态的,因为它没有任何的连接建立和关闭过程,而且大部分是无序列号的。以某个顺序收到的两个数据包是无法确定它们的发出顺序的。但内核仍然可以对UDP连接设置状态。我们来看看是如何跟踪UDP连接的,以及conntrack的相关记录。
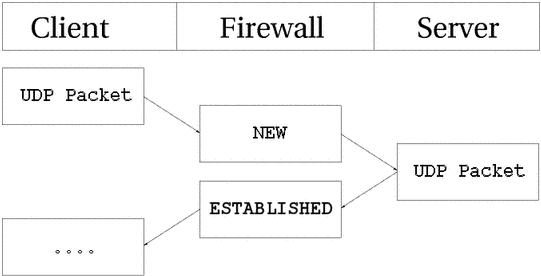
从上图可以看出,以用户的角度考虑,UDP连接的建立几乎与TCP的一样。虽然conntrack信息看起来有点儿不同,但本质上是一样的。下面我们先来看看第一个UDP包发出后的conntrack记录。
udp 17 20 src=192.168.1.2 dst=192.168.1.5 sport=137 dport=1025 \
[UNREPLIED] src=192.168.1.5 dst=192.168.1.2 sport=1025 \
dport=137 use=1
从前两个值可知,这是一个UDP包。第一个是协议名称,第二个是协议号,第三个是此状态的生存时间,默认是30秒。接下来是包的源、目地址和端口,还有期待之中回应包的源、目地址和端口。[UNREPLIED]标记说明还未收到回应。
udp 17 170 src=192.168.1.2 dst=192.168.1.5 sport=137 \
dport=1025 src=192.168.1.5 dst=192.168.1.2 sport=1025 \
dport=137 use=1
一旦收到第一个包的回应,[UNREPLIED]标记就会被删除,连接就被认为是ESTABLISHED的,但在记录里并不显示ESTABLISHED标记。相应地,状态的超时时间也变为180秒了。在本例中,只剩170秒了,10秒后,就会减少为160秒。有个东西是不可少的,虽然它可能会有些变化,就是前面提过的[ASSURED]。要想变为 [ASSURED]状态,连接上必须要再有些流量。
udp 17 175 src=192.168.1.5 dst=195.22.79.2 sport=1025 \
dport=53 src=195.22.79.2 dst=192.168.1.5 sport=53 \
dport=1025 [ASSURED] use=1
可以看出来,[ASSURED]状态的记录和前面的没有多大差别,除了标记由[UNREPLIED]变成[ASSURED]。如果这个连接持续不了180秒,那就要被中断。180秒是短了点儿,但对大部分应用足够了。只要遇到这个连接的包穿过防火墙,超时值就会被重置为默认值,所有的状态都是这样的。
ICMP也是一种无状态协议,它只是用来控制而不是建立连接。ICMP包有很多类型,但只有四种类型有应答包,它们是回显请求和应答(Echo request and reply),时间戳请求和应答(Timestamp request and reply),信息请求和应答(Information request and reply),还有地址掩码请求和应答(Address mask request and reply),这些包有两种状态,NEW和ESTABLISHED 。时间戳请求和信息请求已经废除不用了,回显请求还是常用的,比如ping命令就用的到,地址掩码请求不太常用,但是可能有时很有用并且值得使用。看看下面的图,就可以大致了解ICMP连接的NEW和ESTABLISHED状态了。
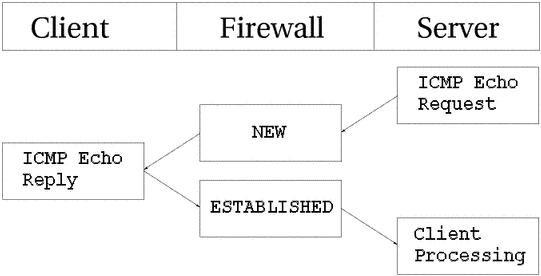
如图所示,主机向目标发送一个回显请求,防火墙就认为这个包处于NEW状态。目标回应一个回显应答,防火墙就认为包处于ESTABLISHED了。当回显请求被发送时,ip_conntrack里就有这样的记录了:
icmp 1 25 src=192.168.1.6 dst=192.168.1.10 type=8 code=0 \
id=33029 [UNREPLIED] src=192.168.1.10 dst=192.168.1.6 \
type=0 code=0 id=33029 use=1
可以看到,ICMP的记录和TCP、UDP的有点区别,协议名称、超时时间和源、目地址都一样,不同之处在于没有了端口,而新增了三个新的字段:type,code和id。字段type说明ICMP的类型。code说明ICMP的代码,这些代码在附录里有说明。id是ICMP包的ID。每个ICMP包被发送时都被分配一个ID,接受方把同样的ID 分配给应答包,这样发送方能认出是哪个请求的应答。
[UNREPLIED]的含义和前面一样,说明数的传输只发生在一个方向上,也就是说未收到应答。再往后,是应答包的源、目地址,还有相应的三个新字段,要注意的是type和code是随着应答包的不同而变化的,id和请求包的一样。
和前面一样,应答包被认为是ESTABLISHED的。然而,在应答包之后,这个ICMP 连接就不再有数据传输了。所以,一旦应答包穿过防火墙,ICMP的连接跟踪记录就被销毁了。
以上各种情况,请求被认为NEW,应答是ESTABLISHED。换句话说,就是当防火墙看到一个请求包时,就认为连接处于NEW状态,当有应答时,就是ESTABLISHED状态。
|
注意,应答包必须符合一定的标准,连接才能被认作established的,每个传输类型都是这样。 |
ICMP的缺省超时是30秒,可以在/proc/sys/net/ipv4/netfilter/ip_ct_icmp_timeout中修改。这个值是比较合适的,适合于大多数情况。
ICMP的另一个非常重要的作用是,告诉UDP、TCP连接或正在努力建立的连接发生了什么,这时ICMP应答被认为是RELATED的。主机不可达和网络不可达就是这样的例子。当试图连接某台机子不成功时(可能那台机子被关上了),数据包所到达的最后一台路由器就会返回以上的ICMP信息,它们就是RELATED的,如下图:
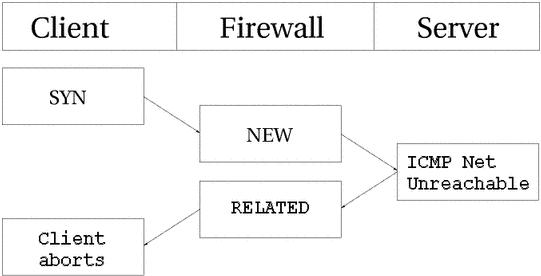
我们发送了一个SYN包到某一地址,防火墙认为它的状态是NEW。但是,目标网络有问题不可达,路由器就会返回网络不可达的信息,这是RELATED的。连接跟踪会认出这个错误信息是哪个连接的,连接会中断,同时相应的记录删除会被删除。
当UDP连接遇到问题时,同样会有相应的ICMP信息返回,当然它们的状态也是RELATED ,如下图:
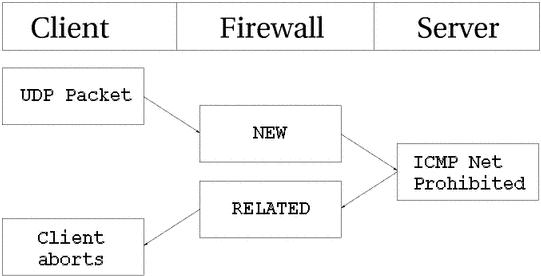
我们发送一个UDP包,当然它是NEW的。但是,目标网络被一些防火墙或路由器所禁止。我们的防火墙就会收到网络被禁止的信息。防火墙知道它是和哪个已打开的UDP连接相关的,并且把这个信息(状态是RELATED)发给它,同时,把相应的记录删除。客户机收到网络被禁止的信息,连接将被中断。
有时,conntrack机制并不知道如何处理某个特殊的协议,尤其是在它不了解这个协议或不知道协议如何工作时,比如,NETBLT,MUX还有EGP。这种情况下,conntrack使用缺省的操作。这种操作很象对UDP连接的操作,就是第一个包被认作NEW,其后的应答包等等数据都是 ESTABLISHED。
使用缺省操作的包的超时值都是一样的,600秒,也就是10分钟。当然,这个值可以通过/proc/sys/net/ipv4/netfilter/ip_ct_generic_timeout更改,以便适应你的通信量,尤其是在耗时较多、流量巨大的情况下,比如使用卫星等。
有些协议比其他协议更复杂,这里复杂的意思是指连接跟踪机制很难正确地跟踪它们,比如,ICQ、IRC 和FTP,它们都在数据包的数据域里携带某些信息,这些信息用于建立其他的连接。因此,需要一些特殊的 helper来完成工作。
下面以FTP作为例子。FTP协议先建立一个单独的连接——FTP控制会话。我们通过这个连接发布命令,其他的端口就会打开以便传输和这个命令相关的数据。这些连接的建立方法有两种:主动模式和被动模式。先看看主动模式,FTP客户端发送端口和IP地址信息给服务器端,然后,客户端打开这个端口,服务器端从它自己的20端口(FTP-Data端口号)建立与这个端口的连接,接着就可以使用这个连接发送数据了。
问题在于防火墙不知道这些额外的连接(相对于控制会话而言),因为这些连接在建立时的磋商信息都在协议数据包的数据域内,而不是在可分析的协议头里。因此,防火墙就不知道是不是该放这些从服务器到客户机的连接过关。
解决的办法是为连接跟踪模块增加一个特殊的helper,以便能检测到那些信息。这样,那些从FTP服务器到客户机的连接就可以被跟踪了,状态是RELATED,过程如下图所示:
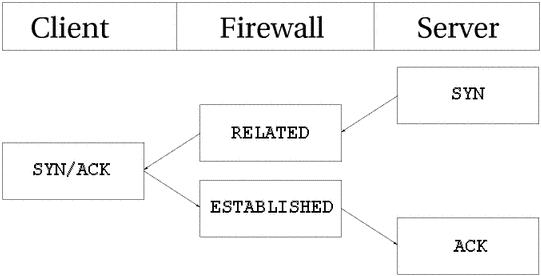
被动FTP工作方式下,data连接的建立过程和主动FTP的相反。客户机告诉服务器需要某些数据,服务器就把地址和端口发回给客户机,客户机据此建立连接接受数据。如果FTP服务器在防火墙后面,或你对用户限制的比较严格,只允许他们访问HTTP和FTP,而封闭了其他所有端口,为了让在Internet是的客户机能访问到FTP,也需要增加上面提到的helper。下面是被动模式下data连接的建立过程:
有些conntrack helper已经包含在内核中,在写这篇文章时,FTP和IRC已有了相应的conntrack helper。如果在内核里没有你想要的helper,可以到iptables用户空间的patch-o-matic目录中看看,那里有很多的helper,比如针对ntalk或H.323协议的等等。如果没找到,还有几个选择:可以查查iptables的 CVS,或者联系Netfilter-devel问问有没有你要的。还不行的话,只有你自己写了,我可以给你介绍一篇好文章,,连接放在附录里。
Conntrack helper即可以被静态地编译进内核,也可以作为模块,但要用下面的命令装载:
modprobe ip_conntrack_*
注意连接跟踪并不处理NAT,因此要对连接做NAT就需要增加相应的模块。比如,你想NAT并跟踪FTP连接,除了FTP的相应模块,还要有NAT的模块。所有的NAT helper名字都是以ip_nat_开头的,这是一个命名习惯:FTP NAT helper叫做ip_nat_ftp,IRC的相应模块就是ip_nat_irc。conntrack helper 的命名也遵循一样的习惯:针对IRC的conntrack helper叫ip_conntrack_irc,FTP的叫作ip_conntrack_ftp。
iptables提供了两个很有用的工具用来处理大规则集: iptables-save和iptables-restore,它们把规则存入一个与标准脚本代码只有细微查别的特殊格式的文件中,或从中恢复规则。
使用iptables-save和iptables-restore的一个最重要的原因是,它们能在相当程度上提高装载、保存规则的速度。使用脚本更改规则的问题是,改动每个规则都要调运命令iptables,而每一次调用iptables,它首先要把Netfilter内核空间中的整个规则集都提取出来,然后再插入或附加,或做其他的改动,最后,再把新的规则集从它的内存空间插入到内核空间中。这会花费很多时间。
为了解决这个问题,可以使用命令iptables-save和restore 。 iptables-save用来把规则集保存到一个特殊格式的文本文件里,而iptables-restore是用来把这个文件重新装入内核空间的。这两个命令最好的地方在于一次调用就可以装载和保存规则集,而不象脚本中每个规则都要调用一次iptables。 iptables-save运行一次就可以把整个规则集从内核里提取出来,并保存到文件里,而iptables-restore每次装入一个规则表。换句话说,对于一个很大的规则集,如果用脚本来设置,那这些规则就会反反复复地被卸载、安装很多次,而我们现在可以把整个规则集一次就保存下来,安装时则是一次一个表,这可是节省了大量的时间。
如果你的工作对象是一组巨大的规则,这两个工具是明显的选择。当然,它们也有不足之处,下面的章节会详细说明。
iptables-restore能替代所有的脚本来设置规则吗?不,到现在为止不行,很可能永远都不行。iptables-restore的主要不足是不能用来做复杂的规则集。例如,我们想在计算机启动时获取连接的动态分配的IP地址,然后用在脚本里。这一点,用iptables-restore来实现,或多或少是不可能的。
一个可能的解决办法是写一个小脚本来获取那个IP地址,并在iptables-restore调用的配置文件中设置相应的关键字,然后用获取的IP值替换关键字。你可以把更改后的配置文件存到一个临时文件中,再由 iptables-restore使用它。然而这会带来很多问题,并且你不能用iptables-save来保存带关键字的配置文件。此法较笨。
另一个办法是先装入iptables-restore文件,再运行一个特定的脚本把动态的规则装入。其实,这也是较笨的方法。iptables-restore并不适合于使用动态IP的场合,如果你想在配置文件里使用选项来实现不同的要求,iptables-restore也不适用。
iptables-restore和iptables-save还有一个不足,就是功能不够齐全。因为使用的人不是太多,所以发现这个问题的人也不多,还有就是一些match和target被引用时考虑不细致,这可能会出现我们预期之外的行为。 尽管存在这些问题,我还是强烈建议你使用它们,因为它们对于大部分规则集工作的还是很好的,只要在规则中别包含那些新的都不知如何使用的match和target。
iptables-save用来把当前的规则存入一个文件里以备iptables-restore使用。它的使用很简单,只有两个参数:
iptables-save [-c] [-t table]
参数-c的作用是保存包和字节计数器的值。这可以使我们在重启防火墙后不丢失对包和字节的统计。带-c参数的iptables-save命令使重启防火墙而不中断统计记数程序成为可能。这个参数默认是不使用的。
参数-t指定要保存的表,默认是保存所有的表。下面给出未装载任何规则的情况下iptables-save的输出。
# Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:17 2002 *filter :INPUT ACCEPT [404:19766] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [530:43376] COMMIT # Completed on Wed Apr 24 10:19:17 2002 # Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:17 2002 *mangle :PREROUTING ACCEPT [451:22060] :INPUT ACCEPT [451:22060] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [594:47151] :POSTROUTING ACCEPT [594:47151] COMMIT # Completed on Wed Apr 24 10:19:17 2002 # Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:17 2002 *nat :PREROUTING ACCEPT [0:0] :POSTROUTING ACCEPT [3:450] :OUTPUT ACCEPT [3:450] COMMIT # Completed on Wed Apr 24 10:19:17 2002
我们来解释一下这个输出格式。#后面的是注释。表都以*
上面的例子是最基本的,我想用一个简短的例子说明会更好,其中包含一个非常小的规则集。iptables-save的输出如下:
# Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:55 2002 *filter :INPUT DROP [1:229] :FORWARD DROP [0:0] :OUTPUT DROP [0:0] -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT -A FORWARD -i eth0 -m state --state RELATED,ESTABLISHED -j ACCEPT -A FORWARD -i eth1 -m state --state NEW,RELATED,ESTABLISHED -j ACCEPT -A OUTPUT -m state --state NEW,RELATED,ESTABLISHED -j ACCEPT COMMIT # Completed on Wed Apr 24 10:19:55 2002 # Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:55 2002 *mangle :PREROUTING ACCEPT [658:32445] :INPUT ACCEPT [658:32445] :FORWARD ACCEPT [0:0] :OUTPUT ACCEPT [891:68234] :POSTROUTING ACCEPT [891:68234] COMMIT # Completed on Wed Apr 24 10:19:55 2002 # Generated by iptables-save v1.2.6a on Wed Apr 24 10:19:55 2002 *nat :PREROUTING ACCEPT [1:229] :POSTROUTING ACCEPT [3:450] :OUTPUT ACCEPT [3:450] -A POSTROUTING -o eth0 -j SNAT --to-source 195.233.192.1 COMMIT # Completed on Wed Apr 24 10:19:55 2002
每个命令前都有包和字节计数器,这说明使用了-c参数。除了有计数器,其他的都和普通的脚本一样。现在的问题是怎么把输出保存到文件中。非常简单,既然使用linux,你应该早就知道了,用重定向啊:
iptables-save -c > /etc/iptables-save
这就会把规则集保存到/etc/iptables-save中,而且还有计数器。
iptables-restore用来装载由iptables-save保存的规则集。不幸的是,它只能从标准输入接受输入,而不能从文件接受。下面是它的事方法:
iptables-restore [-c] [-n]
参数-c要求装入包和字节计数器。如果你用iptables-save保存了计数器,现在想重新装入,就必须用这个参数。它的另一种较长的形式是--counters。
参数-n告诉iptables-restore不要覆盖已有的表或表内的规则。默认情况是清除所有已存的规则。这个参数的长形式是--noflush。
用iptables-restore装载规则有好几种方法,我们来看看最简单、最一般的:
这样规则集应该正确地装入内核并正常工作了。如果有问题,你就要除措了。
本章将详细地讨论如何构件你自己的规则。规则就是指向标,在一条链上,对不同的连接和数据包阻塞或允许它们去向何处。插入链的每一行都是一条规则。我们也会讨论基本的matche及其用法,还有各种各样的target,以及如何建立我们自己的target(比如,一个新的子链)。
我们已经解释了什么是规则,在内核看来,规则就是决定如何处理一个包的语句。如果一个包符合所有的条件(就是符合matche语句),我们就运行target或jump指令。书写规则的语法格式是:
iptables [-t table] command [match] [target/jump]
对于这个句法没什么可说的,但注意target指令必须在最后。为了易读,我们一般用这种语法。总之,你将见到的大部分规则都是按这种语法写的。因此,如果你看到别人写的规则,你很可能会发现用的也是这种语法,当然就很容易理解那些规则了。
如果你不想用标准的表,就要在[table]处指定表名。一般情况下没有必要指定使用的表,因为iptables 默认使用filter表来执行所有的命令。也没有必要非得在这里指定表名,实际上几乎可在规则的任何地方。当然,把表名在开始处已经是约定俗成的标准。
尽管命令总是放在开头,或者是直接放在表名后面,我们也要考虑考虑到底放在哪儿易读。command告诉程序该做什么,比如:插入一个规则,还是在链的末尾增加一个规则,还是删除一个规则,下面会仔细地介绍。
match细致地描述了包的某个特点,以使这个包区别于其它所有的包。在这里,我们可以指定包的来源IP 地址,网络接口,端口,协议类型,或者其他什么。下面我们将会看到许多不同的match。
最后是数据包的目标所在。若数据包符合所有的match,内核就用target来处理它,或者说把包发往 target。比如,我们可以让内核把包发送到当前表中的其他链(可能是我们自己建立的),或者只是丢弃这个包而没有什么处理,或者向发送者返回某个特殊的应答。下面有详细的讨论。
选项-t用来指定使用哪个表,它可以是下面介绍的表中的任何一个,默认的是 filter表。注意,下面的介绍只是章节的摘要。
Table 6-1. Tables
| Table (表名) | Explanation (注释) |
|---|---|
| nat | nat表的主要用处是网络地址转换,即Network Address Translation,缩写为NAT。做过NAT操作的数据包的地址就被改变了,当然这种改变是根据我们的规则进行的。属于一个流的包只会经过这个表一次。如果第一个包被允许做NAT或Masqueraded,那么余下的包都会自动地被做相同的操作。也就是说,余下的包不会再通过这个表,一个一个的被NAT,而是自动地完成。这就是我们为什么不应该在这个表中做任何过滤的主要原因,对这一点,后面会有更加详细的讨论。PREROUTING 链的作用是在包刚刚到达防火墙时改变它的目的地址,如果需要的话。OUTPUT链改变本地产生的包的目的地址。POSTROUTING链在包就要离开防火墙之前改变其源地址。 |
| mangle | 这个表主要用来mangle数据包。我们可以改变不同的包及包头的内容,比如 TTL,TOS或MARK。注意MARK并没有真正地改动数据包,它只是在内核空间为包设了一个标记。防火墙内的其他的规则或程序(如tc)可以使用这种标记对包进行过滤或高级路由。这个表有五个内建的链: PREROUTING,POSTROUTING, OUTPUT,INPUT和 FORWARD。PREROUTING在包进入防火墙之后、路由判断之前改变包,POSTROUTING是在所有路由判断之后。 OUTPUT在确定包的目的之前更改数据包。INPUT在包被路由到本地之后,但在用户空间的程序看到它之前改变包。FORWARD在最初的路由判断之后、最后一次更改包的目的之前mangle包。注意,mangle表不能做任何NAT,它只是改变数据包的 TTL,TOS或MARK,而不是其源目地址。NAT是在nat表中操作的。 |
| filter | filter表是专门过滤包的,内建三个链,可以毫无问题地对包进行DROP、LOG、ACCEPT和REJECT等操作。FORWARD 链过滤所有不是本地产生的并且目的地不是本地(所谓本地就是防火墙了)的包,而 INPUT恰恰针对那些目的地是本地的包。OUTPUT 是用来过滤所有本地生成的包的。 |
上面介绍了三个不同的表的最基本的内容。你应该知道它们的使用目的完全不同,还要清楚每一条链的使用。如果你不了解,就可能会在防火墙上留下漏洞,给人以可乘之机。在章节 中,我们已详细地讨论了这些必备的的表和链。如果你没有完全理解包是怎样通过这些表、链的话,我建议你回过头去再仔细看看。
在这一节里,我们将要介绍所有的command以及它们的用途。command指定iptables 对我们提交的规则要做什么样的操作。这些操作可能是在某个表里增加或删除一些东西,或做点儿其他什么。以下是iptables可用的command(要注意,如不做说明,默认表的是 filter表。):
Table 6-2. Commands
| Command | -A, --append |
| Example | iptables -A INPUT ... |
| Explanation | 在所选择的链末添加规则。当源地址或目的地址是以名字而不是ip地址的形式出现时,若这些名字可以被解析为多个地址,则这条规则会和所有可用的地址结合。 |
| Command | -D, --delete |
| Example | iptables -D INPUT --dport 80 -j DROP或iptables -D INPUT 1 |
| Explanation | 从所选链中删除规则。有两种方法指定要删除的规则:一是把规则完完整整地写出来,再就是指定规则在所选链中的序号(每条链的规则都各自从1被编号)。 |
| Command | -R, --replace |
| Example | iptables -R INPUT 1 -s 192.168.0.1 -j DROP |
| Explanation | 在所选中的链里指定的行上(每条链的规则都各自从1被编号)替换规则。它主要的用处是试验不同的规则。当源地址或目的地址是以名字而不是ip地址的形式出现时,若这些名字可以被解析为多个地址,则这条command会失败。 |
| Command | -I, --insert |
| Example | iptables -I INPUT 1 --dport 80 -j ACCEPT |
| Explanation | 根据给出的规则序号向所选链中插入规则。如果序号为1,规则会被插入链的头部,其实默认序号就是1。 |
| Command | -L, --list |
| Example | iptables -L INPUT |
| Explanation | 显示所选链的所有规则。如果没有指定链,则显示指定表中的所有链。如果什么都没有指定,就显示默认表所有的链。精确输出受其它参数影响,如-n 和-v等参数,下面会介绍。 |
| Command | -F, --flush |
| Example | iptables -F INPUT |
| Explanation | 清空所选的链。如果没有指定链,则清空指定表中的所有链。如果什么都没有指定,就清空默认表所有的链。当然,也可以一条一条地删,但用这个command会快些。 |
| Command | -Z, --zero |
| Example | iptables -Z INPUT |
| Explanation | 把指定链(如未指定,则认为是所有链)的所有计数器归零。 |
| Command | -N, --new-chain |
| Example | iptables -N allowed |
| Explanation | 根据用户指定的名字建立新的链。上面的例子建立了一个名为allowed的链。注意,所用的名字不能和已有的链、target同名。 |
| Command | -X, --delete-chain |
| Example | iptables -X allowed |
| Explanation | 删除指定的用户自定义链。这个链必须没有被引用,如果被引用,在删除之前你必须删除或者替换与之有关的规则。如果没有给出参数,这条命令将会删除默认表所有非内建的链。 |
| Command | -P, --policy |
| Example | iptables -P INPUT DROP |
| Explanation | 为链设置默认的target(可用的是DROP 和ACCEPT,如果还有其它的可用,请告诉我),这个target称作策略。所有不符合规则的包都被强制使用这个策略。只有内建的链才可以使用规则。但内建的链和用户自定义链都不能被作为策略使用,也就是说不能象这样使用:iptables -P INPUT allowed(或者是内建的链)。 |
| Command | -E, --rename-chain |
| Example | iptables -E allowed disallowed |
| Explanation | 对自定义的链进行重命名,原来的名字在前,新名字在后。如上,就是把allowed改为disallowed。这仅仅是改变链的名字,对整个表的结构、工作没有任何影响。 |
在使用iptables时,如果必须的参数没有输入就按了回车,那么它就会给出一些提示信息:告诉你需要哪些参数等等。iptables的选项-v用来显示iptables的版本,-h给出语法的简短说明。。下面将要介绍的就是部分选项,还有它们的作用。
Table 6-3. Options
| Option(选项) | -v, --verbose(详细的) |
| 可用此选项的命令 | --list, --append, --insert, --delete, --replace |
| Explanation(说明) | 这个选项使输出详细化,常与--list 连用。与--list连用时,输出中包括网络接口的地址、规则的选项、TOS掩码、字节和包计数器,其中计数器是以K、M、G(这里用的是10的幂而不是2的幂哦)为单位的。如果想知道到底有多少个包、多少字节,还要用到选项-x,下面会介绍。如果-v 和--append、--insert、--delete 或--replace连用,iptables会输出详细的信息告诉你规则是如何被解释的、是否正确地插入等等。 |
| Option | -x, --exact(精确的) |
| Commands used with | --list |
| Explanation | 使--list输出中的计数器显示准确的数值,而不用K、M、G等估值。注意此选项只能和--list连用。 |
| Option | -n, --numeric(数值) |
| Commands used with | --list |
| Explanation | 使输出中的IP地址和端口以数值的形式显示,而不是默认的名字,比如主机名、网络名、程序名等。注意此选项也只能和--list连用。 |
| Option | --line-numbers |
| Commands used with | --list |
| Explanation | 又是一个只能和--list连用的选项,作用是显示出每条规则在相应链中的序号。这样你可以知道序号了,这对插入新规则很有用哦。 |
| Option | -c, --set-counters |
| Commands used with | --insert, --append, --replace |
| Explanation | 在创建或更改规则时设置计数器,语法如下:--set-counters 20 4000,意思是让内核把包计数器设为20,把字节计数器设为4000。 |
| Option | --modprobe |
| Commands used with | All |
| Explanation | 此选项告诉iptables探测并装载要使用的模块。这是非常有用的一个选项,万一modprobe命令不在搜索路径中,就要用到了。有了这个选项,在装载模块时,即使有一个需要用到的模块没装载上,iptables也知道要去搜索。 |
这一节,我们会详细讨论一些matche,我把它们归为五类。第一类是generic matches(通用的匹配),适用于所有的规则;第二类是TCP matches,顾名思义,这只能用于TCP包;第三类是UDP matches,当然它只能用在UDP包上了;第四类是ICMP matches ,针对ICMP包的;第五类比较特殊,针对的是状态(state),所有者(owner)和访问的频率限制(limit)等,它们已经被分到更多的小类当中,尽管它们并不是完全不同的。我希望这是一种大家都容易理解的分类。
无论我们使用的是何种协议,也不管我们又装入了匹配的何种扩展,通用匹配都使可用的。也就是说,它们可以直接使用,而不需要什么前提条件,在后面你会看到,有很多匹配操作是需要其他的匹配作为前提的。
Table 6-4. Generic matches
| Match | -p, --protocol |
| Example | iptables -A INPUT -p tcp |
| Explanation | 匹配指定的协议。指定协议的形式有以下几种:
1、名字,不分大小写,但必须是在中定义的。 2、可以使用它们相应的整数值。例如,ICMP的值是1,TCP是6,UDP是17。 3、缺省设置,ALL,相应数值是0,但要注意这只代表匹配TCP、UDP、ICMP,而不是中定义的所有协议。 4、可以是协议列表,以英文逗号为分隔符,如:udp,tcp 5、可以在协议前加英文的感叹号表示取反,注意有空格,如: --protocol ! tcp 表示非tcp协议,也就是UDP和ICMP。可以看出这个取反的范围只是TCP、UDP和ICMP。 |
| Match | -s, --src, --source |
| Example | iptables -A INPUT -s 192.168.1.1 |
| Explanation | 以IP源地址匹配包。地址的形式如下:
1、单个地址,如192.168.1.1,也可写成 192.168.1.1/255.255.255.255或192.168.1.1/32 2、网络,如192.168.0.0/24,或 192.168.0.0/255.255.255.0 3、在地址前加英文感叹号表示取反,注意空格,如--source ! 192.168.0.0/24 表示除此地址外的所有地址 4、缺省是所有地址 |
| Match | -d, --dst, --destination |
| Example | iptables -A INPUT -d 192.168.1.1 |
| Explanation | 以IP目的地址匹配包。地址的形式和 -- source完全一样。 |
| Match | -i, --in-interface |
| Example | iptables -A INPUT -i eth0 |
| Explanation | 以包进入本地所使用的网络接口来匹配包。要注意这个匹配操作只能用于INPUT,FORWARD和 PREROUTING这三个链,用在其他任何地方都会提示错误信息。指定接口有一下方法:
1、指定接口名称,如:eth0、ppp0等 2、使用通配符,即英文加号,它代表字符数字串。若直接用一个加号,即iptables -A INPUT -i +表示匹配所有的包,而不考虑使用哪个接口。这也是不指定接口的默认行为。通配符还可以放在某一类接口的后面,如:eth+表示所有Ethernet接口,也就是说,匹配所有从Ethernet接口进入的包。 3、在接口前加英文感叹号表示取反,注意空格,如:-i ! eth0意思是匹配来自除eth0外的所有包。 |
| Match | -o, --out-interface |
| Example | iptables -A FORWARD -o eth0 |
| Explanation | 以包离开本地所使用的网络接口来匹配包。使用的范围和指定接口的方法与--in-interface完全一样。 |
| Match | -f, --fragment |
| Example | iptables -A INPUT -f |
| Explanation | 用来匹配一个被分片的包的第二片或及以后的部分。因为它们不包含源或目的地址,或ICMP类型等信息,其他规则无法匹配到它,所以才有这个匹配操作。要注意碎片攻击哦。这个操作也可以加英文感叹号表示取反,但要注意位置,如:! -f 。取反时,表示只能匹配到没有分片的包或者是被分片的包的第一个碎片,其后的片都不行。现在内核有完善的碎片重组功能,可以防止碎片攻击,所以不必使用取反的功能来防止碎片通过。如果你使用连接跟踪,是不会看到任何碎片的,因为在它们到达任何链之前就被处理过了。 |
这种匹配操作是自动地或隐含地装载入内核的。例如我们使用--protocol tcp 时,不需再装入任何东西就可以匹配只有IP包才有的一些特点。现在有三种隐含的匹配针对三种不同的协议,即TCP matches,UDP matches和 ICMP matches。它们分别包括一套只适用于相应协议的判别标准。相对于隐含匹配的是显式匹配,它们必须使用-m或--match被明确地装载,而不能是自动地或隐含地,下一节会介绍到。
TCP matches只能匹配TCP包或流的细节,它们必须有--protocol tcp作为前提条件。
Table 6-5. TCP matches
| Match | --sport, --source-port |
| Example | iptables -A INPUT -p tcp --sport 22 |
| Explanation | 基于TCP包的源端口来匹配包,端口的指定形式如下:
1、不指定此项,则暗示所有端口。 2、使用服务名或端口号,但名字必须是在 中定义的,因为iptables从这个文件里查找相应的端口号。从这可以看出,使用端口号会使规则装入快一点儿,当然,可读性就差些了。但是如果你想写一个包含200条或更多规则的规则集,那你还是老老实实地用端口号吧,时间是主要因素(在一台稍微慢点儿地机子上,这最多会有10秒地不同,但要是1000条、10000 条呢)。 3、可以使用连续的端口,如:--source-port 22:80这表示从22到80的所有端口,包括22和80。如果两个号的顺序反了也没关系,如:--source-port 80:22这和 --source-port 22:80的效果一样。 4、可以省略第一个号,默认第一个是0,如:--source-port :80表示从0到80的所有端口。 5、也可以省略第二个号,默认是65535,如:--source-port 22:表示从22到 65535的所有端口 6、在端口号前加英文感叹号表示取反,注意空格,如:--source-port ! 22表示除22号之外的所有端口;--source-port ! 22:80表示从22到80(包括22和80)之外的所有端口。 注意:这个匹配操作不能识别不连续的端口列表,如:--source-port ! 22, 36, 80 这样的操作是由后面将要介绍的多端口匹配扩展来完成的。 |
| Match | --dport, --destination-port |
| Example | iptables -A INPUT -p tcp --dport 22 |
| Explanation | 基于TCP包的目的端口来匹配包,端口的指定形式和--sport完全一样。 |
| Match | --tcp-flags |
| Example | |
| Explanation | 匹配指定的TCP标记。有两个参数,它们都是列表,列表内部用英文的逗号作分隔符,这两个列表之间用空格分开。第一个参数指定我们要检查的标记(作用就象掩码),第二个参数指定“在第一个列表中出现过的且必须被设为1(即状态是打开的)的”标记(第一个列表中其他的标记必须置0)。也就是说,第一个参数提供检查范围,第二个参数提供被设置的条件(就是哪些位置1)。这个匹配操作可以识别以下标记:SYN, ACK,FIN,RST ,URG,PSH。另外还有两个词也可使用,就是ALL和NONE。顾名思义,ALL是指选定所有的标记,NONE是指未选定任何标记。这个匹配也可在参数前加英文的感叹号表示取反。例如:
1、iptables -p tcp --tcp-flags SYN,FIN,ACK SYN表示匹配那些SYN标记被设置而FIN和ACK标记没有设置的包,注意各标记之间只有一个逗号而没有空格。 2、--tcp-flags ALL NONE匹配所有标记都未置1的包。 3、iptables -p tcp --tcp-flags ! SYN,FIN,ACK SYN表示匹配那些FIN和ACK标记被设置而SYN标记没有设置的包,注意和例1比较一下。 |
| Match | --syn |
| Example | iptables -p tcp --syn |
| Explanation | 这个匹配或多或少算是ipchains时代的遗留物,之所以还保留它,是为了向后兼容,也是为了方便规则在iptables和ipchains间的转换。它匹配那些SYN标记被设置而 ACK和RST标记没有设置的包,这和iptables -p tcp --tcp-flags SYN,RST,ACK SYN 的作用毫无二样。这样的包主要用在TCP连接初始化时发出请求。如果你阻止了这样的包,也就阻止了所有由外向内的连接企图,这在一定程度上防止了一些攻击。但外出的连接不受影响,恰恰现在有很多攻击就利用这一点。比如有些攻击黑掉服务器之后安装会一些软件,它们能够利用已存的连接到达你的机子,而不要再新开一个端口。这个匹配也可用英文感叹号取反,如:! --syn用来匹配那些 RST或ACK被置位的包,换句话说,就是状态为已建立的连接的包。 |
| Match | --tcp-option |
| Example | iptables -p tcp --tcp-option 16 |
| Explanation | 根据匹配包。TCP选项是TCP头中的特殊部分,有三个不同的部分。第一个8位组表示选项的类型,第二个8位组表示选项的长度(这个长度是整个选项的长度,但不包含填充部分所占的字节,而且要注意不是每个TCP选项都有这一部分的),第三部分当然就是选项的内容了。为了适应标准,我们不必执行所有的选项,但我们可以查看选项的类型,如果不是我们所支持的,那就只是看看长度然后跳过数据部分。这个操作是根据选项的十进制值来匹配的,它也可以用英文感叹号取反。所有的选项都可在里找到。 |
UDP matches是在指定--protocol UDP时自动装入的。UDP是一种无连接协议,所以在它打开、关闭连接以及在发送数据时没有多少标记要设置,它也不需要任何类型的确认。数据丢失了,就丢失了(不会发送ICMP错误信息的)。这就说明UDP matches要比TCP matches少多了。即使UDP和ICMP是无连接协议,状态机制也可以很好的工作,就象在TCP上一样,这在前面讨论过。
Table 6-6. UDP matches
| Match | --sport, --source-port |
| Example | iptables -A INPUT -p udp --sport 53 |
| Explanation | 基于UDP包的源端口来匹配包,端口的指定形式和TCP matches中的--sport完全一样。 |
| Match | --dport, --destination-port |
| Example | iptables -A INPUT -p udp --dport 53 |
| Explanation | 基于UDP包的目的端口来匹配包,端口的指定形式和TCP matches中的--sport完全一样。 |
ICMP协议也是无连接协议,ICMP包更是短命鬼,比UDP的还短。ICMP协议不是IP协议的下属协议,而是它的辅助者,其主要作用是报告错误和连接控制。ICMP包的头和IP的很相似,但又有很多不同。这个协议最主要的特点是它有很多类型,以应对不同的情况。比如,我们想访问一个无法访问的地址,就会收到一个ICMP host unreachable信息,它的意思是主机无法到达。在附录里有完整的ICMP类型列表。虽然有这么多类型,但只有一个 ICMP matche,这就足够对付它们了。这个matche是在指定--protocol ICMP时自动装入的。注意所有的通用匹配都可以使用,这样我们就可以匹配ICMP包的源、目地址。
Table 6-7. ICMP matches
| Match | --icmp-type |
| Example | iptables -A INPUT -p icmp --icmp-type 8 |
| Explanation | 根据ICMP类型匹配包,类型的指定可以使用十进制数值或相应的名字,数值在RFC792中有定义,名字可以用iptables --protocol icmp --help 查看,或者在附录中查找。这个匹配也可用英文感叹号取反,如:--icmp-type ! 8就表示匹配除类型8之外的所有ICMP包。要注意有些ICMP 类型已经废弃不用了,还有一些可能会对无防护的主机带来“危险”,因为它们可能把包重定向到错误的地方。 |
显式匹配必须用-m或--match装载,比如要使用状态匹配就必须使用-m state。有些匹配还需要指定协议,有些就不需要,比如连接状态就不要。这些状态是NEW(还未建立好的连接的第一个包), ESTABLISHED(已建立的连接,也就是已经在内核里注册过的),RELATED(由已经存在的、处于已建立状态的连接生成的新连接),等等。有些匹配还处在开发阶段,或者还只是为了说明iptables的强大能力。这说明不是所有的匹配一开始就是实用的,但以后你可能会用到它。随着iptables 新版本的发布,会有一些新的匹配可用。隐含匹配和显式匹配最大的区别就是一个是跟随协议匹配自动装载的,一个是显式装载的。
这个匹配操作必须由-m limit明确指定才能使用。有了它的帮助,就可以对指定的规则的日志数量加以限制,以免你被信息的洪流淹没哦。比如,你可以事先设定一个限定值,当符合条件的包的数量不超过它时,就记录;超过了,就不记录了。我们可以控制某条规则在一段时间内的匹配次数(也就是可以匹配的包的数量),这样就能够减少DoS syn flood攻击的影响。这是它的主要作用,当然,还有很多其他作用(译者注:比如,对于某些不常用的服务可以限制连接数量,以免影响其他服务)。limit match也可以用英文感叹号取反,如:-m limit ! --limit 5/s表示在数量超过限定值后,所有的包都会被匹配。
(译者注:为了更好地理解这个匹配操作,我们通过一个比喻来解释一下。原文也做了类似地比喻,但我觉得对于初学者不易理解,故未采用。)limit match的工作方式就像一个单位大门口的保安,当有人要进入时,需要找他办理通行证。早上上班时,保安手里有一定数量的通行证,来一个人,就签发一个,当通行证用完后,再来人就进不去了,但他们不会等,而是到别的地方去(在iptables里,这相当于一个包不符合某条规则,就会由后面的规则来处理,如果都不符合,就由缺省的策略处理)。但有个规定,每隔一段时间保安就要签发一个新的通行证。这样,后面来的人如果恰巧赶上,也就可以进去了。如果没有人来,那通行证就保留下来,以备来的人用。如果一直没人来,可用的通行证的数量就增加了,但不是无限增大的,最多也就是刚开始时保安手里有的那个数量。也就是说,刚开始时,通行证的数量是有限的,但每隔一段时间就有新的通行证可用。limit match有两个参数就对应这种情况,--limit-burst指定刚开始时有多少通行证可用,--limit指定要隔多长时间才能签发一个新的通行证。要注意的是,我这里强调的是“签发一个新的通行证”,这是以iptables的角度考虑的。在你自己写规则时,就要从这个角度考虑。比如,你指定了--limit 3/minute --limit-burst 5 ,意思是开始时有5个通行证,用完之后每20秒增加一个(这就是从iptables的角度看的,要是以用户的角度看,说法就是每一分钟增加三个或者每分钟只能过三个)。你要是想每20分钟过一个,只能写成--limit 3/hour --limit-burst 5,也就是说你要把时间单位凑成整的。
Table 6-8. Limit match options
| Match | --limit |
| Example | iptables -A INPUT -m limit --limit 3/hour |
| Explanation | 为limit match设置最大平均匹配速率,也就是单位时间内limit match可以匹配几个包。它的形式是一个数值加一个时间单位,可以是/second /minute /hour /day 。默认值是每小时3次(用户角度),即3/hour ,也就是每20分钟一次(iptables角度)。 |
| Match | --limit-burst |
| Example | iptables -A INPUT -m limit --limit-burst 5 |
| Explanation | 这里定义的是limit match的峰值,就是在单位时间(这个时间由上面的--limit指定)内最多可匹配几个包(由此可见,--limit-burst的值要比--limit的大)。默认值是5。为了观察它是如何工作的,你可以启动“只有一条规则的脚本”,然后用不同的时间间隔、发送不同数量的ping数据包。这样,通过返回的 echo replies就可以看出其工作方式了。 |
基于包的MAC源地址匹配包。到写这篇文章时,这个match还有一点限制(就是只能匹配MAC源地址匹),但今后定会有所发展,会更有用的。
|
注意,这个match是由-m mac装入的,而不是一些人想当然的-m mac-source,后者只是前者的选项而已。 |
Table 6-9. MAC match options
| Match | --mac-source |
| Example | iptables -A INPUT -m mac --mac-source 00:00:00:00:00:01 |
| Explanation | 基于包的MAC源地址匹配包,地址格式只能是XX:XX:XX:XX:XX:XX,当然它也可以用英文感叹号取反,如--mac- source ! 00:00:00:00:00:01,意思很简单了,就是除此之外的地址都可接受嘛。注意,因为 MAC addresses只用于Ethernet类型的网络,所以这个match只能用于Ethernet接口。而且,它还只能在PREROUTING,FORWARD 和INPUT链里使用。 |
以包被设置的mark来匹配包,这个值只能由内核更改。前面曾经提到过,mark比较特殊,它不是包本身的一部分,而是在包穿越计算机的过程中由内核分配的和它相关联的一个字段。它可能被用来改变包的传输路径或过滤。时至今日,在linux里只有一种方法能设置mark,即iptables的MARK target,以前在ipchains里是FWMARK target。这就是为什么在高级路由里我们仍要参照FWMARK的原因。mark字段的值是一个无符号的整数,在32位系统上最大可以是4294967296(就是2的32次方),这足够用的了:)
Table 6-10. Mark match options
| Match | --mark |
| Example | iptables -t mangle -A INPUT -m mark --mark 1 |
| Explanation | 以包被设置的mark值来匹配包,这个值是是由下面将要介绍的 MARK target来设置的,它是一个无符号的整数。所有通过 Netfilter的包都会被分配一个相关联的mark field 。但要注意mark值可不是在任何情况下都能使用的,它只能在分配给它值的那台机子里使用,因为它只是由内核在内存里分配的和包相关的几个字节,并不属于包本身,所以我们不能在本机之外的路由器上使用。mark的格式是--mark value[/mask],如上面的例子是没有掩码的,带掩码的例子如--mark 1/1。如果指定了掩码,就先把mark值和掩码取逻辑与,然后再和包的mark值比较。 |
多端口匹配扩展使我们能够在一条规则里指定不连续的多个端口,如果没有这个扩展,我们只能按端口来写规则了。其实这只是标准端口匹配的增强版罢了,使我们书写规则更方便而已。
|
注意:不能在一条规则里同时使用标准端口匹配和多端口匹配,如--sport 1024:63353 -m multiport --dport 21,23,80。这条规则并不能想你想象的那样工作,但也不是不能工作,iptables会使用第一个合法的条件,那么这里多端口匹配就白写了:) |
Table 6-11. Multiport match options
| Match | --source-port |
| Example | iptables -A INPUT -p tcp -m multiport --source-port 22,53,80,110 |
| Explanation | 源端口多端口匹配,最多可以指定15个端口,以英文逗号分隔,注意没有空格。使用时必须有-p tcp或-p udp为前提条件。 |
| Match | --destination-port |
| Example | iptables -A INPUT -p tcp -m multiport --destination-port 22,53,80,110 |
| Explanation | 目的端口多端口匹配,使用方法和源端口多端口匹配一样,唯一的区别是它匹配的是目的端口。 |
| Match | --port |
| Example | iptables -A INPUT -p tcp -m multiport --port 22,53,80,110 |
| Explanation | 同端口多端口匹配,意思就是它匹配的是那种源端口和目的端口是同一个端口的包,比如:端口80到端口80的包,110到110的包等。使用方法和源端口多端口匹配一样。 |
基于包的生成者(也就是所有者,或称作拥有者,owner)的ID来匹配包,owner可以是启动进程的用户的ID,或用户所在的组的ID,或进程的ID,或会话的ID。这个扩展原本只是为了说明iptables可以做什么,现在发展到实用阶段了。但要注意,此扩展只能用在OUTPUT中,原因显而易见:我们几乎不可能得到发送端例程的ID的任何信息,或者在去往真正目的地的路上哪儿有路由。甚至在 OUTPUT链里,这也不是十分可靠,因为有些包根本没有owner,比如 ICMP responses,所以它们从不会被这个match抓到:)
Table 6-12. Owner match options
| Match | --uid-owner |
| Example | iptables -A OUTPUT -m owner --uid-owner 500 |
| Explanation | 按生成包的用户的ID(UID)来匹配外出的包。使用这个匹配可以做这样一些事,比如,阻止除root外的用户向防火墙外建立新连接,或阻止除用户http外的任何人使用HTTP端口发送数据。 |
| Match | --gid-owner |
| Example | iptables -A OUTPUT -m owner --gid-owner 0 |
| Explanation | 按生成包的用户所在组的ID(GID)来匹配外出的包。比如,我们可以只让属于network组的用户上Internet,而其他用户都不行;或者只允许http组的成员能从HTTP端口发送数据。 |
| Match | --pid-owner |
| Example | iptables -A OUTPUT -m owner --pid-owner 78 |
| Explanation | 按生成包的进程的ID(GID)来匹配外出的包。比如,我们可以只允许PID为94的进程(http进程当然不能是多线程的)使用http端口。这个匹配使用起来有一点难度,因为你要知道进程的ID号。当然,你也可以写一个小小的脚本,先从ps的输出中得到PID,再添加相应的规则,这儿有个例子。 |
| Match | --sid-owner |
| Example | iptables -A OUTPUT -m owner --sid-owner 100 |
| Explanation | 按生成包的会话的ID(SID)来匹配外出的包。一个进程以及它的子进程或它的多个线程都有同一个SID。比如,所有的HTTPD进程的SID和它的父进程一样(最初的 HTTPD进程),即使HTTPD是多线程的(现在大部分都是,比如Apache和Roxen)也一样。这里有个脚本可以反映出这一点。 |
状态匹配扩展要有内核里的连接跟踪代码的协助,因为它是从连接跟踪机制中得到包的状态的。这样我们就可以了解连接所处的状态。它几乎适用于所有的协议,包括那些无状态的协议,如ICMP和UDP。针对每个连接都有一个缺省的超时值,如果连接的时间超过了这个值,那么这个连接的记录就被会从连接跟踪的记录数据库中删除,也就是说连接就不再存在了。这个match必须有-m state作为前提才能使用。状态机制的详细内容在章节中。
Table 6-13. State matches
| Match | --state |
| Example | iptables -A INPUT -m state --state RELATED,ESTABLISHED |
| Explanation | 指定要匹配包的的状态,当前有4种状态可用:INVALID,ESTABLISHED,NEW和RELATED。 INVALID意味着这个包没有已知的流或连接与之关联,也可能是它包含的数据或包头有问题。ESTABLISHED意思是包是完全有效的,而且属于一个已建立的连接,这个连接的两端都已经有数据发送。NEW表示包将要或已经开始建立一个新的连接,或者是这个包和一个还没有在两端都有数据发送的连接有关。RELATED说明包正在建立一个新的连接,这个连接是和一个已建立的连接相关的。比如,FTP data transfer,ICMP error 和一个TCP或UDP连接相关。注意NEW状态并不在试图建立新连接的TCP包里寻找SYN标记,因此它不应该不加修改地用在只有一个防火墙或在不同的防火墙之间没有启用负载平衡的地方。具体如何使用,你就再看看章节吧:) |
根据TOS字段匹配包,必须使用-m tos才能装入。TOS是IP头的一部分,其含义是Type Of Service,由8个二进制位组成,包括一个3 bit的优先权子字段(现在已被忽略),4 bit的TOS子字段和1 bit未用位(必须置0)。它一般用来把当前流的优先权和需要的服务(比如,最小延时、最大吞吐量等)通知路由器。但路由器和管理员对这个值的处理相差很大,有的根本就不理会,而有的就会尽量满足要求。
Table 6-14. TOS matches
| Match | --tos |
| Example | iptables -A INPUT -p tcp -m tos --tos 0x16 |
| Explanation | 根据TOS字段匹配包。这个match常被用来mark包,以便后用,除此之外,它还常和iproute2或高级路由功能一起使用。它的参数可以是16进制数,也可以是十进制数,还可以是相应的名字(用 iptables -m tos -h能查到)。到写这篇文章时,有以下参数可用:
Minimize-Delay 16 (0x10),要求找一条路径使延时最小,一些标准服务如telnet、SSH、FTP-control 就需要这个选项。 Maximize-Throughput 8 (0x08),要求找一条路径能使吞吐量最大,标准服务FTP-data能用到这个。 Maximize-Reliability 4 (0x04),要求找一条路径能使可靠性最高,使用它的有BOOTP和TFTP。 Minimize-Cost 2 (0x02),要求找一条路径能使费用最低,一般情况下使用这个选项的是一些视频音频流协议,如RTSP(Real Time Stream Control Protocol)。 Normal-Service 0 (0x00),一般服务,没有什么特殊要求。 |
根据IP头里的TTL (Time To Live,即生存期)字段来匹配包,此必须由-m ttl装入。TTL field是一个字节(8个二进制位),一旦经过一个处理它的路由器,它的值就减去1它的值。当该字段的值减为0时,报文就被认为是不可转发的,数据报就被丢弃,并发送ICMP报文通知源主机,不可转发的报文被丢弃。这也有两种情况,一是传输期间生存时间为0,使用类型为11代码是0的ICMP报文;二是在数据报重组期间生存时间为0,使用类型为11代码是1的ICMP报文。这个match只是根据TTL匹配包,而对其不做任何更改,所以在它之后可使用任何类型的match。
Table 6-15. TTL matches
| Match | --ttl |
| Example | iptables -A OUTPUT -m ttl --ttl 60 |
| Explanation | 根据TTL的值来匹配包,参数的形式只有一种,就是十进制数值。它可以被用来调试你的局域网,比如解决LAN内的主机到Internet上的主机的连接问题,或找出 Trojan(Trojan)可能的入口。这个match的用处相对有限,但它其实是很有用的,这就看你的想象力如何了。比如可以用它来发现那些TTL具有错误缺省值的机子(这可能是实现TCP/IP栈功能的那个程序本身的错误,或者是配置有问题)。 |
这个匹配没有任何参数,也不需要显式地装载。注意这应该被看作是一个实验性的匹配,它不总是能正常工作的,对有些不正常的包(unclean package,就是所谓的脏包)或问题,它是视而不见的。这个match 试图匹配那些好象畸形或不正常的包,比如包头错或校验和错,等等。它可能常用来DROP错误的连接、检查有错的流,但要知道这样做也可能会中断合法的连接。
target/jump决定符合条件的包到何处去,语法是--jump target或-j target。(译者注:本文中,原作者把target细分为两类,即Target和Jump。它们唯一的区别是jump的目标是一个在同一个表内的链,而target的目标是具体的操作。)我们会先接触到两个基本的target,就是ACCEPT和DROP。
前面提到过用户自定义链要用到-N命令。下面我们在filter表中建一个名为tcp_packets的链:
iptables -N tcp_packets
然后再把它作为jump的目标:
iptables -A INPUT -p tcp -j tcp_packets
这样我们就会从INPUT链跳入tcp_packets链,开始在tcp_packets中的旅行。如果到达了tcp_packets链的结尾(也就是未被链中的任何规则匹配),则会退到INPUT链的下一条规则继续它的旅行。如果在子链中被ACCEPT了,也就相当于在父链中被ACCEPT了,那么它不会再经过父链中的其他规则。但要注意这个包能被其他表的链匹配,过程可查看章节 。
target指定我们要对包做的操作,比如DROP和ACCEPT,还有很多,我们后面会介绍。不同的target有不同的结果。一些target会使包停止前景,也就是不再继续比较当前链中的其他规则或父链中的其他规则,最好的例子就是DROP和ACCEPT。而另外一些target在对包做完操作之后,包还会继续和其他的规则比较,如LOG,ULOG和TOS。它们会对包进行记录、mangle,然后让包通过,以便匹配这条链中的其他规则。有了这样的target,我们就可以对同一个包既改变它的TTL又改变它的TOS。有些target必须要有准确的参数(如TOS需要确定的数值),有些就不是必须的,但如果我们想指定也可以(如日志的前缀,伪装使用的端口,等等)。本节我们会尽可能全面地介绍每一个target。现在我们就来看看有哪几种target。
这个target没有任何选项和参数,使用也很简单,指定-j ACCEPT即可。一旦包满足了指定的匹配条件,就会被ACCEPT,并且不会再去匹配当前链中的其他规则或同一个表内的其他规则,但它还要通过其他表中的链,而且在那儿可能会百DROP也说不准哦。
这个target是用来做目的网络地址转换的,就是重写包的目的IP地址。如果一个包被匹配了,那么和它属于同一个流的所有的包都会被自动转换,然后就可以被路由到正确的主机或网络。DNAT target是非常有用的。比如,你的Web服务器在LAN内部,而且没有可在Internet上使用的真实IP地址,那就可以使用这个 target让防火墙把所有到它自己HTTP端口的包转发给LAN内部真正的Web服务器。目的地址也可以是一个范围,这样的话,DNAT会为每一个流随机分配一个地址。因此,我们可以用这个target做某种类型地负载平衡。
注意,DANT target只能用在nat表的PREROUTING和OUTPUT链中,或者是被这两条链调用的链里。但还要注意的是,包含DANT target的链不能被除此之外的其他链调用,如POSTROUTING。
Table 6-16. DNAT target
| Option | --to-destination |
| Example | iptables -t nat -A PREROUTING -p tcp -d 15.45.23.67 --dport 80 -j DNAT --to-destination 192.168.1.1-192.168.1.10 |
| Explanation | 指定要写入IP头的地址,这也是包要被转发到的地方。上面的例子就是把所有发往地址15.45.23.67的包都转发到一段LAN使用的私有地址中,即192.168.1.1到 192.168.1.10。如前所述,在这种情况下,每个流都会被随机分配一个要转发到的地址,但同一个流总是使用同一个地址。我们也可以只指定一个IP地址作为参数,这样所有的包都被转发到同一台机子。我们还可以在地址后指定一个或一个范围的端口。比如:--to-destination 192.168.1.1:80或 --to-destination 192.168.1.1:80-100。SNAT的语法和这个target的一样,只是目的不同罢了。要注意,只有先用--protocol指定了TCP或 UDP协议,才能使用端口。 |
因为DNAT要做很多工作,所以我要再罗嗦一点。我们通过一个例子来大致理解一下它是如何工作的。比如,我想通过Internet连接发布我们的网站,但是HTTP server在我们的内网里,而且我们对外只有一个合法的IP,就是防火墙那个对外的IP——$INET_IP。防火墙还有一个内网的IP——$LAN_IP,HTTP server的IP是$HTTP_IP (这当然是内网的了)。为了完成我们的设想,要做的第一件事就是把下面的这个简单的规则加入到nat表的PREROUTING链中:
iptables -t nat -A PREROUTING --dst $INET_IP -p tcp --dport 80 -j DNAT \ --to-destination $HTTP_IP
现在,所有从Internet来的、到防火墙的80端口去的包都会被转发(或称做被DNAT )到在内网的HTTP服务器上。如果你在Internet上试验一下,一切正常吧。再从内网里试验一下,完全不能用吧。这其实是路由的问题。下面我们来好好分析这个问题。为了容易阅读,我们把在外网上访问我们服务器的那台机子的IP地址记为$EXT_BOX。
包从地址为$EXT_BOX的机子出发,去往地址为$INET_IP 的机子。
包到达防火墙。
防火墙DNAT(也就是转发)这个包,而且包会经过很多其他的链检验及处理。
包离开防火墙向$HTTP_IP前进。
包到达HTTP服务器,服务器就会通过防火墙给以回应,当然,这要求把防火墙作为HTTP到达$EXT_BOX的网关。一般情况下,防火墙就是HTTP服务器的缺省网关。
防火墙再对返回包做Un-DNAT(就是照着DNAT的步骤反过来做一遍),这样就好像是防火墙自己回复了那个来自外网的请求包。
返回包好象没经过这么复杂的处理、没事一样回到$EXT_BOX。
现在,我们来考虑和HTTP服务器在同一个内网(这里是指所有机子不需要经过路由器而可以直接互相访问的网络,不是那种把服务器和客户机又分在不同子网的情况)的客户访问它时会发生什么。我们假设客户机的IP为$LAN_BOX,其他设置同上。
包离开$LAN_BOX,去往$INET_IP。
包到达防火墙。
包被DNAT,而且还会经过其他的处理。但是包没有经过SNAT 的处理,所以包还是使用它自己的源地址,就是$LAN_BOX(译者注:这就是IP 传输包的特点,只根据目的地的不同改变目的地址,但不因传输过程中要经过很多路由器而随着路由器改变其源地址,除非你单独进行源地址的改变。其实这一步的处理和对外来包的处理是一样的,只不过内网包的问题就在于此,所以这里交待一下原因)。
包离开防火墙,到达HTTP服务器。
HTTP服务器试图回复这个包。它在路由数据库中看到包是来自同一个网络的一台机子,因此它会把回复包直接发送到请求包的源地址(现在是回复包的目的地址),也就是$LAN_BOX。
回复包到达客户机,但它会很困惑,因为这个包不是来自它访问的那台机子。这样,它就会把这个包扔掉而去等待“真正”的回复包。
针对这个问题有个简单的解决办法,因为这些包都要进入防火墙,而且它们都去往需要做DNAT才能到达的那个地址,所以我们只要对这些包做SNAT操作即可。比如,我们来考虑上面的例子,如果对那些进入防火墙而且是去往地址为$HTTP_IP、端口为80的包做SNAT操作,那么这些包就好象是从$LAN_IP来的了,也就是说,这些包的源地址被改为$LAN_IP了。这样,HTTP服务器就会把回复包发给防火墙,而防火墙会再对包做 Un-DNAT操作,并把包发送到客户机。解决问题的规则如下:
iptables -t nat -A POSTROUTING -p tcp --dst $HTTP_IP --dport 80 -j SNAT \ --to-source $LAN_IP
要记住,按运行的顺序POSTROUTING链是所有链中最后一个,因此包到达这条链时,已经被做过DNAT操作了,所以我们在规则里要基于内网的地址$HTTP_IP(包的目的地)来匹配包。
 |
警告:我们刚才写的这条规则会对日志产生很大影响,这种影响应该说是很不好的。因为来自 Internet包在防火墙内先后经过了DNAT和SNAT处理,才能到达HTTP服务器(上面的例子),所以HTTP服务器就认为包是防火墙发来的,而不知道真正的源头是其他的IP。这样,当它记录服务情况时,所有访问记录的源地址都是防火墙的IP而不是真正的访问源。我们如果想根据这些记录来了解访问情况就不可能了。因此上面提供的“简单办法”并不是一个明智的选择,但它确实可以解决“能够访问”的问题,只是没有考虑到日志而已。 其他的服务也有类似的问题。比如,你在LAN内建立了SMTP服务器,那你就要设置防火墙以便能转发SMTP的数据流。这样你就创建了一个开放的SMTP中继服务器,随之而来的就是日志的问题了。 一定要注意,这里所说的问题只是针对没有建立DMZ或类似结构的网络,并且内网的用户访问的是服务器的外网地址而言的。(译者注:因为如果建立了DMZ,或者服务器和客户机又被分在不同的子网里,那就不需要这么麻烦了。因为所有访问的源头都不在服务器所在的网里,所以就没必要做SNAT去改变包的源地址了,从而记录也就不是问题了。如果内网客户是直接访问服务器的内网地址那就更没事了) 较好的解决办法是为你的LAN在内网建立一台单独的DNS服务器(译者注:这样,内网的客户使用网站名访问HTTP服务器时,DNS就可以把它解析成内网地址。客户机就可以直接去访问HTTP服务器的内网地址了,从而避免了通过防火墙的操作,而且包的源地址也可以被HTTP服务器的日志使用,也就没有上面说的日志问题了。),或者干脆建立DMZ得了(这是最好的办法,但你要有钱哦,因为用的设备多啊)。 |
对上面的例子应该考虑再全面些,现在还有一个问题没解决,就是防火墙自己要访问HTTP服务器时会发生什么,能正常访问吗?你觉得呢:)很可惜,现在的配置还是不行,仔细想想就明白了。我们这里讨论的基础都是假设机子访问的是HTTP服务器的外网地址,但这个外网地址其实就是防火墙对外的地址,所以当防火墙访问这个外网地址时,就是访问它自己。防火墙上如果有HTTP服务,那客户机就会看到页面内容,不过这不是它想看到的(它想要的在DNAT上了),如果没有HTTP服务,客户就只能收到错误信息了。前面给出的规则之所以不起作用是因为从防火墙发出的请求包不会经过那两条链。还记得防火墙自己发出的包经过哪些链吧:)我们要在nat表的OUTPUT链中添加下面的规则:
iptables -t nat -A OUTPUT --dst $INET_IP -p tcp --dport 80 -j DNAT \ --to-destination $HTTP_IP
有了最后这条规则,一切都正常了。和HTTP服务器不在同一个网的机子能正常访问服务了,和它在一个网内的机子也可以正常访问服务了,防火墙本身也能正常访问服务了,没有什么问题了。这种心情,套用《大话西游》里的一句话,就是“世界又清净了”。(不要说你不知道什么是《大话西游》)
|
我想大家应该能明白这些规则只说明了数据包是如何恰当地被DNAT和SNAT的。除此之外,在 filter表中还需要其他的规则(在FORWARD链里),以允许特定的包也能经过前面写的(在POSTROUTING链和 OUTPUT链里的)规则。千万不要忘了,那些包在到达FORWARD链之前已经在PREROUTING链里被DNAT过了,也就是说它们的目的地址已被改写,在写规则时要注意这一点。 |
顾名思义,如果包符合条件,这个target就会把它丢掉,也就是说包的生命到此结束,不会再向前走一步,效果就是包被阻塞了。在某些情况下,这个target会引起意外的结果,因为它不会向发送者返回任何信息,也不会向路由器返回信息,这就可能会使连接的另一方的sockets因苦等回音而亡:) 解决这个问题的较好的办法是使用REJECT target,(译者注:因为它在丢弃包的同时还会向发送者返回一个错误信息,这样另一方就能正常结束),尤其是在阻止端口扫描工具获得更多的信息时,可以隐蔽被过滤掉的端口等等(译者注:因为扫描工具扫描一个端口时,如果没有返回信息,一般会认为端口未打开或被防火墙等设备过滤掉了)。还要注意如果包在子链中被DROP了,那么它在主链里也不会再继续前进,不管是在当前的表还是在其他表里。总之,包死翘翘了。
这个target是专门用来记录包地有关信息的。这些信息可能是非法的,那就可以用来除错。LOG会返回包的有关细节,如IP头的大部分和其他有趣的信息。这个功能是通过内核的日志工具完成的,一般是syslogd。返回的信息可用dmesg阅读,或者可以直接查看syslogd的日志文件,也可以用其他的什么程序来看。LOG对调试规则有很大的帮助,你可以看到包去了哪里、经过了什么规则的处理,什么样的规则处理什么样的包,等等。当你在生产服务器上调试一个不敢保证100%正常的规则集时,用LOG代替DROP是比较好的(有详细的信息可看,错误就容易定位、解决了),因为一个小小的语法错误就可能引起严重的连接问题,用户可不喜欢这样哦。如果你想使用真正地扩展日志地话,可能会对ULOG target有些兴趣,因为它可以把日志直接记录到MySQL databases或类似的数据库中。
|
注意,如果在控制台得到的信息不是你想要的,那不是iptables或Netfilter的问题,而是 syslogd 配置文件的事,这个文件一般都是/etc/syslog.conf。有关这个问题的更多信息请查通过man syslog.conf查看。 |
LOG现在有5个选项,你可以用它们指定需要的信息类型或针对不同的信息设定一些值以便在记录中使用。选项如下:
Table 6-17. LOG target options
| Option | --log-level |
| Example | iptables -A FORWARD -p tcp -j LOG --log-level debug |
| Explanation | 告诉iptables和 syslog使用哪个记录等级。记录等级的详细信息可以查看文件syslog.conf,一般来说有以下几种,它们的级别依次是:debug,info,notice,warning,warn,err,error,crit,alert, emerg,panic。其中,error和err、warn和warning、panic和emerg分别是同义词,也就是说作用完全一样的。注意这三种级别是不被赞成使用的,换句话说,就是不要使用它们(因为信息量太大)。信息级别说明了被记录信息所反映的问题的严重程度。所有信息都是通过内核的功能被记录的,也就是说,先在文件 syslog.conf里设置kern.=info /var/log/iptables,然后再让所有关于iptables的LOG信息使用级别info,就可以把所有的信息存入文件/var/log/iptables内。注意,其中也可能会有其他的信息,它们是内核中使用info 这个等级的其他部分产生的。有关日志的详细信息,我建议你看看syslog和syslog.conf的帮助,还有HOWTO,等等。 |
| Option | --log-prefix |
| Example | iptables -A INPUT -p tcp -j LOG --log-prefix "INPUT packets" |
| Explanation | 告诉iptables在记录的信息之前加上指定的前缀。这样和grep或其他工具一起使用时就容易追踪特定的问题,而且也方便从不同的规则输出。前缀最多能有29个英文字符,这已经是包括空白字符和其他特殊符号的总长度了。 |
| Option | --log-tcp-sequence |
| Example | iptables -A INPUT -p tcp -j LOG --log-tcp-sequence |
| Explanation | 把包的TCP序列号和其他日志信息一起记录下来。TCP序列号可以唯一标识一个包,在重组时也是用它来确定每个分组在包里的位置。注意,这个选项可能会带来危险,因为这些记录被未授权的用户看到的话,可能会使他们更容易地破坏系统。其实,任何iptables的输出信息都增加了这种危险。(译者注:现在,我深刻理解了什么是“言多必失”,什么是“沉默是金”) |
| Option | --log-tcp-options |
| Example | iptables -A FORWARD -p tcp -j LOG --log-tcp-options |
| Explanation | 记录TCP包头中的字段大小不变的选项。这对一些除错是很有价值的,通过它提供的信息,可以知道哪里可能出错,或者哪里已经出了错。 |
| Option | --log-ip-options |
| Example | iptables -A FORWARD -p tcp -j LOG --log-ip-options |
| Explanation | 记录IP包头中的字段大小不变的选项。这对一些除错是很有价值的,还可以用来跟踪特定地址的包。 |
用来设置mark值,这个值只能在本地的mangle表里使用,不能用在其他任何地方,就更不用说路由器或另一台机子了。因为mark比较特殊,它不是包本身的一部分,而是在包穿越计算机的过程中由内核分配的和它相关联的一个字段。它可以和本地的高级路由功能联用,以使不同的包能使用不同的队列要求,等等。如果你想在传输过程中也有这种功能,还是用TOS target吧。有关高级路由的更多信息,可以查看。
Table 6-18. MARK target options
| Option | --set-mark |
| Example | iptables -t mangle -A PREROUTING -p tcp --dport 22 -j MARK --set-mark 2 |
| Explanation | 设置mark值,这个值是一个无符号的整数。比如,我们对一个流或从某台机子发出的所有的包设置了mark值,就可以利用高级路由功能来对它们进行流量控制等操作了。 |
这个target和SNAT target的作用是一样的,区别就是它不需要指定--to-source 。MASQUERADE是被专门设计用于那些动态获取IP地址的连接的,比如,拨号上网、DHCP连接等。如果你有固定的IP地址,还是用SNAT target吧。
伪装一个连接意味着,我们自动获取网络接口的IP地址,而不使用--to-source 。当接口停用时,MASQUERADE不会记住任何连接,这在我们kill掉接口时是有很大好处的。如果我们使用SNAT target,连接跟踪的数据是被保留下来的,而且时间要好几天哦,这可是要占用很多连接跟踪的内存的。一般情况下,这种处理方式对于拨号上网来说是较好的(这有利于已有那连接继续使用)。如果我们被分配给了一个不同于前一次的IP,不管怎样已有的连接都要丢失,但或多或少地还是有一些连接记录被保留了(真是白痴,是吧)。
即使你有静态的IP,也可以使用MASQUERADE,而不用SNAT 。不过,这不是被赞成的,因为它会带来额外的开销,而且以后还可能引起矛盾,比如它也许会影响你的脚本,使它们不能用。
注意,MASQUERADE和SNAT一样,只能用于nat表的 POSTROUTING链,而且它只有一个选项(不是必需的):
Table 6-19. MASQUERADE target
| Option | --to-ports |
| Example | iptables -t nat -A POSTROUTING -p TCP -j MASQUERADE --to-ports 1024-31000 |
| Explanation | 在指定TCP或UDP的前提下,设置外出包能使用的端口,方式是单个端口,如--to-ports 1025,或者是端口范围,如--to- ports 1024-3000。注意,在指定范围时要使用连字号。这改变了SNAT中缺省的端口选择,详情请查看 。 |
这个target是实验性的,它只是一个演示而已,不建议你使用它,因为它可能引起循环,除此之外,还可能引起严重的DoS。这个target的作用是颠倒IP头中的源目地址,然后再转发包。这会引起很有趣的事,一个骇客最后攻破的可能就是他自己的机子。看来,使用这个target至少可以使我们的机子更强壮:) 我们如果对机子A的80端口使用了MIRROR,会发生什么呢?假设有来自yahoo.com的机子B 想要访问A的HTTP服务,那他得到的将是yahoo的主页,因为请求是来自yahoo的。
注意,MIRROR只能用在INPUT、 FORWARD、 PREROUTING链和被它们调用的自定义链中。还要注意,如果外出的包是因 MIRROR target发出的,则它们是不会被filter、nat或mangle表内的链处理的,这可能引起循环或其他问题。比如,一台机子向另一台配置了MIRROR且TTL值为255的机子发送一个会被认为是欺骗的数据包,同时这台机子也欺骗自己的数据包,以使它被认为好像是来自第三个使用了MIRROR 的机子。这样,那个包就会不间断地往来很多次,直到TTL为0。如果两台机子之间只有一个路由器,这个包就会往返240-255次。对骇客来说,这是不坏的情况,因为他只要发送一个1500字节的数据(也就是一个包),就可以消耗你的连接的380K字节。对于骇客或者叫做脚本小子(不管我们把他们称作什么)来说,这可是很理想的情况。
这个target为用户空间的程序或应用软件管理包队列。它是和iptables之外的程序或工具协同使用的,包括网络计数工具,高级的数据包代理或过滤应用,等等。讨论程序的编码已超出了本文的范围。即使讨论,也要花很多时间,而且在这样一篇文章之内也无法说清有关Netfilter和iptables的编程。具体的信息请查看。
在防火墙所在的机子内部转发包或流到另一个端口。比如,我们可以把所有去往端口HTTP的包REDIRECT到HTTP proxy(例如squid),当然这都发生在我们自己的主机内部。本地生成的包都会被映射到127.0.0.1。换句话说,这个target把要转发的包的目的地址改写为我们自己机子的IP。我们在做透明代理(LAN内的机子根本不需要知道代理的存在就可以正常上网)时,这个target可是起了很大作用的。
注意,它只能用在nat表的PREROUTING、OUTPUT链和被它们调用的自定义链里。 REDIRECT只有一个选项:
Table 6-20. REDIRECT target
| Option | --to-ports |
| Example | iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080 |
| Explanation | 在指定TCP或UDP协议的前提下,定义目的端口,方式如下:
1、不使用这个选项,目的端口不会被改变。 2、指定一个端口,如--to-ports 8080 3、指定端口范围,如--to-ports 8080-8090 |
REJECT和DROP基本一样,区别在于它除了阻塞包之外,还向发送者返回错误信息。现在,此target还只能用在INPUT、FORWARD、OUTPUT和它们的子链里,而且包含 REJECT的链也只能被它们调用,否则不能发挥作用。它只有一个选项,是用来控制返回的错误信息的种类的。虽然有很多种类,但如果你有TCP/IP方面的基础知识,就很容易理解它们。
Table 6-21. REJECT target
| Option | --reject-with |
| Example | iptables -A FORWARD -p TCP --dport 22 -j REJECT --reject-with tcp-reset |
| Explanation | 告诉REJECT target应向发送者返回什么样的信息。一旦包满足了设定的条件,就要发送相应的信息,然后再象DROP一样无情地抛弃那些包。可用的信息类型有:1、icmp-net-unreachable 2、icmp-host-unreachable 3、 icmp-port-unreachable 4、icmp-proto-unreachable 5、icmp-net-prohibited 6、icmp-host-prohibited 。其中缺省的是port-unreachable。你可以在附录中看到更多的信息。还有一个类型——echo-reply,它只能和匹配 ICMP ping包的规则联用。最后一个类型是tcp-reset,(显然,只能用于TCP协议)它的作用是告诉REJECT返回一个TCP RST包(这个包以文雅的方式关闭TCP连接,有关它的详细信息在里)给发送者。正如iptables的 man page中说的,tcp-reset主要用来阻塞身份识别探针(即113/tcp,当向被破坏的邮件主机发送邮件时,探针常被用到,否则它不会接受你的信)。 |
顾名思义,它使包返回上一层,顺序是:子链——>父链——>缺省的策略。具体地说,就是若包在子链中遇到了RETURN,则返回父链的下一条规则继续进行条件的比较,若是在父链(或称主链,比如INPUT)中遇到了RETURN,就要被缺省的策略(一般是ACCEPT或DROP)操作了。(译者注:这很象C语言中函数返回值的情况)
我们来举个例子说明一下,假设一个包进入了INPUT链,匹配了某条target为--jump EXAMPLE_CHAIN规则,然后进入了子链EXAMPLE_CHAIN。在子链中又匹配了某条规则,恰巧target是--jump RETURN,那包就返回INPUT链了。如果在INPUT链里又遇到了--jump RETURN,那这个包就要交由缺省的策略来处理了。
这个target是用来做源网络地址转换的,就是重写包的源IP地址。当我们有几个机子共享一个Internet 连接时,就能用到它了。先在内核里打开ip转发功能,然后再写一个SNAT规则,就可以把所有从本地网络出去的包的源地址改为Internet连接的地址了。如果我们不这样做而是直接转发本地网的包的话,Internet上的机子就不知道往哪儿发送应答了,因为在本地网里我们一般使用的是IANA组织专门指定的一段地址,它们是不能在Internet上使用的。SNAT target的作用就是让所有从本地网出发的包看起来都是从一台机子发出的,这台机子一般就是防火墙。
SNAT只能用在nat表的POSTROUTING链里。只要连接的第一个符合条件的包被SNAT了,那么这个连接的其他所有的包都会自动地被SNAT,而且这个规则还会应用于这个连接所在流的所有数据包。
Table 6-22. SNAT target
| Option | --to-source |
| Example | iptables -t nat -A POSTROUTING -p tcp -o eth0 -j SNAT --to-source 194.236.50.155-194.236.50.160:1024-32000 |
| Explanation | 指定源地址和端口,有以下几种方式:
1、单独的地址。 2、一段连续的地址,用连字符分隔,如194.236.50.155-194.236.50.160,这样可以实现负载平衡。每个流会被随机分配一个IP,但对于同一个流使用的是同一个IP。 3、在指定-p tcp 或 -p udp的前提下,可以指定源端口的范围,如194.236.50.155:1024-32000,这样包的源端口就被限制在1024-32000了。 注意,如果可能,iptables总是想避免任何的端口变更,换句话说,它总是尽力使用建立连接时所用的端口。但是如果两台机子使用相同的源端口,iptables 将会把他们的其中之一映射到另外的一个端口。如果没有指定端口范围, 所有的在512以内的源端口会被映射到512以内的另一个端口,512和1023之间的将会被映射到 1024内,其他的将会被映射到大于或对于1024的端口,也就是说是同范围映射。还要注意,这种映射和目的端口无关。因此,如果客户想和防火墙外的HTTP服务器联系,它是不会被映射到FTP control所用的端口的。 |
TOS是用来设置IP头中的Type of Service字段的。这个字段长一个字节,可以控制包的路由情况。它也是iproute2及其子系统可以直接使用的字段之一。值得注意的是,如果你有几个独立的防火墙和路由器,而且还想在他们之间利用包的头部来传递路由信息,TOS是唯一的办法。前面说过,MARK是不能用来传递这种信息的。如果你需要为某个包或流传递路由信息,就要使用TOS字段,它也正是为这个而被开发的。
Internet上有很多路由器在这一方面并没有做好工作,因此,在发送包之前改变其TOS没有什么大用处。最好的情况是路由器根本不理它,最坏的情况是路由器会根据TOS处理,但都是错误的。然而,如果你是在一个很大的WAN或LAN里,而且有很多路由器,TOS还是能有很好的作为的。总的来说,基于TOS的值给包以不同的路由和参数还是可能的,即使在网络里是受限制的(译者注:大不了不起作用就是了)。
|
TOS只能用来设置具体的或者说是特定的值(这些预定义的值在内核源码的include文件——Linux/ip.h中),原因是很多的,但不管怎么说,你不要使用其他的值就是了。当然,我们也有办法突破这个限制,就是使用一个名为FTOS的patch,你可在由Matthew G. Marsh维护的站点 Paksecured Linux Kernel patches得到它,但要小心使用哦。除了非常特殊、极端的情况,我们是不应该使用预定义以外的值的。 |
|
注意,这个target只能在mangle表内使用。 |
|
还要注意,在一些老版(1.2.2或更低)的iptables中包含的这个target在设置了TOS之后,不会调整包的校验和,这样包会被认为是错误的并要求重发。而且,这很可能会导致更多的mangle操作,从而使整个连接无法工作。(译者注:好在我们现在不会再用这么老的版本了:) ) |
TOS target只有一个选项:
Table 6-23. TOS target
| Option | --set-tos |
| Example | iptables -t mangle -A PREROUTING -p TCP --dport 22 -j TOS --set-tos 0x10 |
| Explanation | 设置TOS的值,值的形式可以是名字或者使相应的数值(十进制或16进制的)。一般情况下,建议你使用名字而不使用数值形式,因为以后这些数值可能会有所改变,而名字一般是固定的。TOS字段有8个二进制位,所以可能的值是0-255(十进制)或0x00-0xFF(16进制)。如前所述,你最好使用预定义的值,它们是:
1、Minimize-Delay 16 (0x10),要求找一条路径使延时最小,一些标准服务如telnet、SSH、FTP- control 就需要这个选项。 2、Maximize-Throughput 8 (0x08),要求找一条路径能使吞吐量最大,标准服务FTP-data能用到这个。 3、Maximize-Reliability 4 (0x04),要求找一条路径能使可靠性最高,使用它的有BOOTP和TFTP。 4、Minimize-Cost 2 (0x02),要求找一条路径能使费用最低,一般情况下使用这个选项的是一些视频音频流协议,如RTSP(Real Time Stream Control Protocol)。 5、Normal-Service 0 (0x00),一般服务,没有什么特殊要求。这个值也是大部分包的缺省值。 完整的列表可以通过命令iptables -j TOS -h 得到。在1.2.5版时,这个列表就已经是完整的了,而且会保持很长一段时间。 |
|
这个target需要patch-o-matic里的名为TTL的patch,可从获得。此站点的FAQ是开始学习iptables和Netfilter的好地方。 |
TTL可以修改IP头中Time To Live字段的值。它有很大的作用,我们可以把所有外出包的Time To Live值都改为一样的,比如64,这是Linux的默认值。有些ISP不允许我们共享连接(他们可以通过TTL的值来区分是不是有多个机子使用同一个连接),如果我们把TTL都改为一样的值,他们就不能再根据TTL来判断了。
关于任何设置Linux的TTL默认值,请参阅附录 内的。
TTL只能在mangle表内使用,它有3个选项:
Table 6-24. TTL target
| Option | --ttl-set |
| Example | iptables -t mangle -A PREROUTING -i eth0 -j TTL --ttl-set 64 |
| Explanation | 设置TTL的值。这个值不要太大,也不要太小,大约64就很好。值太大会影响网络,而且有点不道德,为什么这样说呢?如果有些路由器的配置不太正确,包的TTL又非常大,那它们就会在这些路由器之间往返很多次,值越大,占用的带宽越多。这个target就可以被用来限制包能走多远,一个比较恰当的距离是刚好能到达DNS服务器。 |
| Option | --ttl-dec |
| Example | iptables -t mangle -A PREROUTING -i eth0 -j TTL --ttl-dec 1 |
| Explanation | 设定TTL要被减掉的值,比如--ttl-dec 3。假设一个进来的包的TTL是53,那么当它离开我们这台机子时,TTL就变为49了。为什么不是50呢?因为经过我们这台机子,TTL本身就要减1,还要被TTL target再减3,当然总共就是减去4了。使用这个 target可以限制“使用我们的服务的用户”离我们有多远。比如,用户总是使用比较近的DNS,那我们就可以对我们的DNS服务器发出的包进行几个--ttl-dec。(译者注:意思是,我们只想让距离DNS服务器近一些的用户访问我们的服务)当然,用--set-ttl控制更方便些。 |
| Option | --ttl-inc |
| Example | iptables -t mangle -A PREROUTING -i eth0 -j TTL --ttl-inc 1 |
| Explanation | 设定TTL要被增加的值,比如--ttl-inc 4。假设一个进来的包的TTL是53,那么当它离开我们这台机子时,TTL应是多少呢?答案是56,原因同--ttl-dec。使用这个选项可以使我们的防火墙更加隐蔽,而不被trace-routes发现,方法就是设置--ttl-inc 1。原因应该很简单了,包每经过一个设备,TTL就要自动减1,但在我们的防火墙里这个1又被补上了,也就是说,TTL的值没变,那么trace-routes就会认为我们的防火墙是不存在的。Trace-routes让人又爱又恨,爱它是因为在连接出问题时,它可以给我们提供极有用的信息,告诉我们哪里有毛病;恨它是由于它也可以被黑客或骇客用来收集目标机器的资料。怎么使用它呢?这里有个很好的例子,请看脚本。 |
ULOG可以在用户空间记录被匹配的包的信息,这些信息和整个包都会通过netlink socket被多播。然后,一个或多个用户空间的进程就会接受它们。换句话说,ULOG是至今iptables和Netfilter下最成熟、最完善的日志工具,它包含了很多更好的工具用于包的记录。这个target可以是我们把信息记录到MySQL或其他数据库中。这样,搜索特定的包或把记录分组就很方便了。你可以在里找到ULOGD用户空间的软件。
Table 6-25. ULOG target
| Option | --ulog-nlgroup |
| Example | iptables -A INPUT -p TCP --dport 22 -j ULOG --ulog-nlgroup 2 |
| Explanation | 指定向哪个netlink组发送包,比如-- ulog-nlgroup 5。一个有32个netlink组,它们被简单地编号位1-32。默认值是1。 |
| Option | --ulog-prefix |
| Example | iptables -A INPUT -p TCP --dport 22 -j ULOG --ulog-prefix "SSH connection attempt: " |
| Explanation | 指定记录信息的前缀,以便于区分不同的信息。使用方法和 LOG的prefix一样,只是长度可以达到32个字符。 |
| Option | --ulog-cprange |
| Example | iptables -A INPUT -p TCP --dport 22 -j ULOG --ulog-cprange 100 |
| Explanation | 指定每个包要向“ULOG在用户空间的代理”发送的字节数,如--ulog-cprange 100,表示把整个包的前100个字节拷贝到用户空间记录下来,其中包含了这个包头,还有一些包的引导数据。默认值是0,表示拷贝整个包,不管它有多大。 |
| Option | --ulog-qthreshold |
| Example | iptables -A INPUT -p TCP --dport 22 -j ULOG --ulog-qthreshold 10 |
| Explanation | 告诉ULOG在向用户空间发送数据以供记录之前,要在内核里收集的包的数量(译者注:就像集装箱),如--ulog-qthreshold 10。这表示先在内核里积聚10个包,再把它们发送到用户空间里,它们会被看作同一个netlink的信息,只是由好几部分组成罢了。默认值是1,这是为了向后兼容,因为以前的版本不能处理分段的信息。 |
