分类: Oracle
2009-02-01 20:16:39
本文我们尝试总结在多个用户并发情况下,如何识别和解决删除操作期间发生的死锁问题,在开始之前,我们先简单描述一下什么是死锁以及什么东西会导致死锁。
死锁
在任何数据库中发生死锁都是不愉快的,即使是在一个特殊的情况下发生也是如此,它们会减小应用程序的接受程度(ACCEPTANCE),因此避免并正确解释死锁是非常重要的。
当两个或更多用户相互等待锁定的数据时就会发生死锁,发生死锁时,这些用户被卡住不能继续处理业务,Oracle自动检测死锁并解决它们(通过回滚一个包含在死锁中的语句实现),释放掉该语句锁住的数据,回滚的会话将会遇到Oracle错误“ORA-00060:等待资源时检测到死锁”。
是什么导致了死锁?
明确地锁定表是为了保证读/写一致性,未建立索引的外键约束,在相同顺序下表不会锁住,没有为数据段分配足够的参数(主要是指INITTRANS,MAXTRANS和PCTFREE参数)很容易引发突发锁和死锁,原因是多种多样的,需要重新逐步审查。
识别死锁
当Oracle数据库检测到死锁时(Oracle错误消息:ORA-00060),相应的消息就写入到警告日志文件中(alert.log),另外还会在USER_DUMP_DEST目录下创建一个跟踪文件,分析警告日志文件和跟踪文件是非常耗时的。
下面是一个警告日志文件示例:
Mon Aug 07 09:14:42 2007
ORA-000060: Deadlock detected. More info in file
e:\oracle\admin\GEDEON\udump\ORA01784.TRC.
下面是从跟踪文件中节选出来的片段,从其中我们可以看出是哪个语句创造了死锁,相关的语句和被锁定的资源已经标记为粗体。
/users/ora00/log/odn_ora_1097872.trc
Oracle9i Enterprise Edition Release 9.2.0.8.0 - 64bit Production
With the Partitioning, OLAP and Oracle Data Mining options
JServer Release 9.2.0.8.0 - Production
ORACLE_HOME = /soft/ora920
System name:AIX
Node name:beaid8
Release:2
Version:5
Machine:00C95B0E4C00
Instance name: ODN
Redo thread mounted by this instance: 1
Oracle process number: 17
Unix process pid: 1097872, image: oracle@beaid8 (TNS V1-V3)
*** 2007-06-04 14:41:04.080
*** SESSION ID:(10.6351) 2007-06-04 14:41:04.079
DEADLOCK DETECTED ( ORA-00060 )
The following deadlock is not an ORACLE error. It is a
deadlock due to user error in the design of an application
or from issuing incorrect ad-hoc SQL. The following
information may aid in determining the deadlock:
Deadlock graph:
---------Blocker(s)-------- ---------Waiter(s)---------
Resource Name process session holds waits process session holds waits
TM-00001720-00000000 17 10 SX 16 18 SX SSX
TM-0000173a-00000000 16 18 SX 17 10 SX SSX
session 10: DID 0001-0011-00000002session 18: DID 0001-0010-00000022
session 18: DID 0001-0010-00000022session 10: DID 0001-0011-00000002
Rows waited on:
Session 18: obj - rowid = 00001727 - AAABcnAAJAAAAAAAAA
(dictionary objn - 5927, file - 9, block - 0, slot - 0)
Session 10: obj - rowid = 00001727 - AAABcnAAJAAAAAAAAA
(dictionary objn - 5927, file - 9, block - 0, slot - 0)
Information on the OTHER waiting sessions:
Session 18:
pid=16 serial=2370 audsid=18387 user: 21/ODN
O/S info: user: mwpodn00, term: unknown, ospid: , machine: beaida
program: JDBC Thin Client
application name: JDBC Thin Client, hash value=0
Current SQL Statement:
DELETE FROM ODNQTEX WHERE EX_ID = :B1
End of information on OTHER waiting sessions.
Current SQL statement for this session:
DELETE FROM ODNQTFN WHERE FN_ID_EXIGENCE_EX = :B1
----- PL/SQL Call Stack -----
object line object
handle number name
7000000135f7fd8 34 procedure ODN.ODNQPDR
7000000135f89f0 16 procedure ODN.ODNQPZB
我们可以使用企业管理器来决定保留所有的锁还是释放掉它们,为了便于说明,我们打开2个sqlplus实例会话(在此期间同时发生了死锁)来一起调式,当每个语句执行完毕后,我们看到锁仍然保留下来了,它可以帮助我们识别出是哪个资源引起的死锁。
下面列出了可以帮助我们监视锁的视图: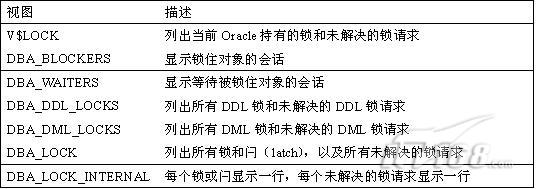
可以通过查询V$LOCK字典视图来确定锁,如:
select * from v$lock ;
下面的SQL查询可以用于确定锁住数据库对象的锁:
select
c.owner,
c.object_name,
c.object_type,
b.sid,
b.serial#,
b.status,
b.osuser,
b.machine
from
v$locked_object a ,
v$session b,
dba_objects c
where
b.sid = a.session_id
and
a.object_id = c.object_id;
解决死锁
安装顺序执行下面的修改,避免一致性访问期间的死锁问题:
设置事务一致性:我们需要确定一个隔离水平,在过程中可以使用“READ COMMITTED”或“SERIALIZABLE”,我们需要考虑两件事情:
设置事务可以在任何时间提交
相关表中行的读取顺序
Oracle数据库隔离模式通过行级锁和Oracle数据库多版本并发控制系统提供高级一致性和并发性(和高性能),READ COMMITTED模式可以提供更多的并发性,因为没有重复读,SERIALIZABLE隔离水平提供了更好的一致性,通过保护非重复读实现,在一个读写事务执行不止一次查询时这很重要,然而,SERIALIZABLE模式需要应用程序检查“不能连续访问”的错误,这样就可以在有许多访问相同数据的一致性事务的环境中大大减少吞吐量。
在我们的例子中,我们需要使用READ COMMITTED隔离水平,原因如下:
我们需要获取由另一个事务提交的查询返回的行,不仅仅是获取刚开始的事务返回的行。
如果我们将隔离水平设为SERIALIZABLE,将会获得一个“事务无法按顺序访问”的错误,因为我们想要修改的数据已经被另一个事务修改了。
在存储过程中我们放入下面的语句:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
明确锁定数据:Oracle数据库总是执行必要的锁确保数据的并发性、完整性和语句级读一致性,但在我们的例子中,我们需要独占访问资源,为了处理它的语句,事务独占访问资源,不要等待其他事务完成。
我将会用一个例子来解释,在我们的案例中,需要删除一个业务对象System,为了删除这个对象,首先我们需要删除System子表中的所有数据,现在进入其中一个子表,我们在子表上创建一个关于删除的触发器,这个触发器更新主表System的数据并锁住它,接下来进入删除操作,当我们想删除System表中的数据时,就会出现死锁,因为它已经被前面子表上的触发器给锁住了,为了避免出现这种情况,在删除操作开始之前,我们提供一个行独占锁锁住System表来解决这个问题。命令如下:
LOCK TABLE ODNQTSY IN ROW EXCLUSIVE MODE;
并行索引和查询处理:Oracle数据库使用索引增强SQL查询的性能,这有助于我们执行DML操作,如插入、更新和删除,做这些动作的时间将会极具减少了。
并行索引将会让优化器思考执行并行查询时使用索引,这是避免死锁的一个方法,当索引重建后,Oracle将会允许多个DML操作发生在同一个索引上,在索引上启用并行操作的语法如下:
ALTER INDEX
使用并行查询选项的最大好处是直接路径读取,因此需要的latch就更少了,同样,并行执行大大减少了数据密集型业务的响应时间。
并行执行选项可以通过修改INIT.ORA文件中的PARALLEL_AUTOMATIC_TUNING参数(设为TRUE)实现数据库级别的启用。
parallel_automatic_tuning=TRUE
外键上的索引:外键上如果没有建立索引会引发两个问题,第一个是如果你更新父记录主键或删除父记录,子表的外键没有索引时,会引发表级锁;第二个问题是性能。
如果你试图删除父表行,或更新父/子关联中父表行的键值,而子表的外键上没有索引时,Oracle将会尝试在子表上获得一个共享行级独占锁,接下来如果有其它会话要修改子表,它将不得不等待在它前面的SRX锁(共享行级独占锁),这样就形成了一个死锁状态。
下面的脚本可以帮助我们识别没有索引的外键(FK)约束,从脚本执行的输出中,我们可以确定在外键上创建索引将可以帮助我们改善性能,并且可以避免死锁。
column columns format a20 word_wrapped
column table_name format a30 word_wrapped
select decode( b.table_name, NULL, '****', 'ok' ) Status,
a.table_name, a.columns, b.columns
from
( select substr(a.table_name,1,30) table_name,
substr(a.constraint_name,1,30) constraint_name,
max(decode(position, 1, substr(column_name,1,30),NULL)) ||
max(decode(position, 2,', '||substr(column_name,1,30),NULL)) ||
max(decode(position, 3,', '||substr(column_name,1,30),NULL)) ||
max(decode(position, 4,', '||substr(column_name,1,30),NULL)) ||
max(decode(position, 5,', '||substr(column_name,1,30),NULL)) ||
max(decode(position, 6,', '||substr(column_name,1,30),NULL)) ||
max(decode(position, 7,', '||substr(column_name,1,30),NULL)) ||
max(decode(position, 8,', '||substr(column_name,1,30),NULL)) ||
max(decode(position, 9,', '||substr(column_name,1,30),NULL)) ||
max(decode(position,10,', '||substr(column_name,1,30),NULL)) ||
max(decode(position,11,', '||substr(column_name,1,30),NULL)) ||
max(decode(position,12,', '||substr(column_name,1,30),NULL)) ||
max(decode(position,13,', '||substr(column_name,1,30),NULL)) ||
max(decode(position,14,', '||substr(column_name,1,30),NULL)) ||
max(decode(position,15,', '||substr(column_name,1,30),NULL)) ||
max(decode(position,16,', '||substr(column_name,1,30),NULL)) columns
from user_cons_columns a, user_constraints b
where a.constraint_name = b.constraint_name
and b.constraint_type = 'R'
group by substr(a.table_name,1,30), substr(a.constraint_name,1,30) ) a,
( select substr(table_name,1,30) table_name, substr(index_name,1,30) index_name,
max(decode(column_position, 1, substr(column_name,1,30),NULL)) ||
max(decode(column_position, 2,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position, 3,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position, 4,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position, 5,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position, 6,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position, 7,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position, 8,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position, 9,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position,10,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position,11,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position,12,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position,13,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position,14,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position,15,', '||substr(column_name,1,30),NULL)) ||
max(decode(column_position,16,', '||substr(column_name,1,30),NULL)) columns
from user_ind_columns
group by substr(table_name,1,30), substr(index_name,1,30) ) b
where a.table_name = b.table_name (+)
and b.columns (+) like a.columns || '%'
外键的级联删除:在我们的案例中,已经使用“级联删除选项(On Delete Cascade)”创建了一些外键约束,这样会引发死锁问题,原因是在我们的删除事务中,我们明确地删除子表中的数据,然后再删除主表中的数据,因此在子表上就已经存在一个锁了,在删除主表之前,我们想再删除子表一次,因此导致的死锁。
为了解决这个问题,我们移除了“级联删除选项(On Delete Cascade)”,这样就修复了死锁问题。
