从上面可以看到,由于日志切换而发生的增量检查点从18:27:48开始,到18:32:45结束,用了5分钟的时间。而我们强制进行完全检查点,则只用
了大概1秒钟不到的时间。实际上,DBWR在实际写入数据文件所花费的时间都是一样的,也就是不到1秒。5分钟的差别就在于DBWR等了5分钟才实际开始
写数据文件。
在大致了解了日志缓冲区的操作过程以后,我们来深入了解一下其内部的工作原理是怎样的。
当用户发出DML语句,请求更新某些表里的数据时,在日志缓冲区中生成重做记录的过程如下所示。
1) 服务器进程判断buffer cache中是否存在要求被更新的数据块,如果没有,则从数据文件中将数据块调入buffer
cache。然后以排他(Exclusive)模式将该数据块钉住(ping)。注意,这里的数据块包括回滚段段头(事务表)、回滚段数据块以及表所对应
的数据块等。
2) 服务器进程构造一组改动向量(change vector)来描述对数据块所做的变化过程。这组改动向量会放在session的PGA中。实际上,这组改动向量也就是重做记录了。
3) 根据重做记录的大小,判断在日志缓冲区中需要多少空间。
4) 判断当前的SCN值,并将其存放到重做记录中。注意,并不是每个重做记录都具有不同的SCN值,不同的重做记录可能会共享相同的SCN值。
5) 进程获得名为redo copy的latch。
6) 进程获得名为redo allocation的latch。
7) 检查当前是否有其他进程生成了比当前持有的SCN更高的SCN值。如果是,则生成一个新的SCN值,并代替第四步所持有的SCN值。
8) 判断是否有足够的空间容纳当前的重做记录,这里足够的空间既包括日志缓冲区,也包括联机日志文件。这时的逻辑比较复杂。
a) 如果联机日志文件中有足够的空间,则判断日志缓冲区是否有足够的空间。
I. 如果日志缓冲区中没有足够的空间,则进程释放redo copy latch和redo allocation latch。然后在下面的两个选项中做一个选择:
(1)如果这时已经有其他进程或其他条件触发了LGWR,则等待LGWR的完成;
(2)如果这时LGWR没有启动,则触发LGWR启动。为了防止多个进程同时触发LGWR,oracle还引入了名为redo
writing的latch。当LGWR进程在写重做记录到联机日志文件的过程中,会一直持有redo writing
latch,这时任何试图获得该latch的进程都必须等待。
实际上,当进程发现没有足够的空间以后,会立即尝试获取redo writing
latch。如果不能获得该latch则说明LGWR正在清空日志缓冲区,所以进程会等待,过一段时间再次尝试去获得该latch;如果获得了该
latch,则立即检查这时日志缓冲区中是否还有足够的空间,如果有,则释放redo writing latch,并再次尝试获得redo copy
latch和redo allocation latch;如果没有,则释放redo writing
latch,同时触发LGWR,这时LGWR获得redo writing latch。
II. 如果日志缓冲区中有足够的空间,则从日志缓冲区中分配所需大小的空间,然后释放redo allocation
latch,注意这时仍持有redo copy
latch。将改动向量拷贝到所分配的日志缓冲区中,将重做记录所对应的脏数据块挂到检查点队列(checkpoint
queue)上去。最后,释放redo copy latch。
b) 如果联机日志没有足够的空间(可能有一部分可用空间,但是不够用。实际这就是有时你会看到归档日志文件的尺寸会小于联机日志文件的尺寸的原因),则进程会检查是否已经有进程已经触发日志切换了,如果有,则当前进程等待,如果没有则触发日志切换。然后,重复第8步。
9) 当在日志缓冲区中写完重做记录以后,检查当前日志缓冲区中的重做记录的数量是否达到限定值,如果是,则必须触发LGWR进程。
10) 最后,进程更新buffer cache中的数据块。
我们可以用一个图来描述一下上面所说的日志缓冲区的管理过程,如下图四所示。
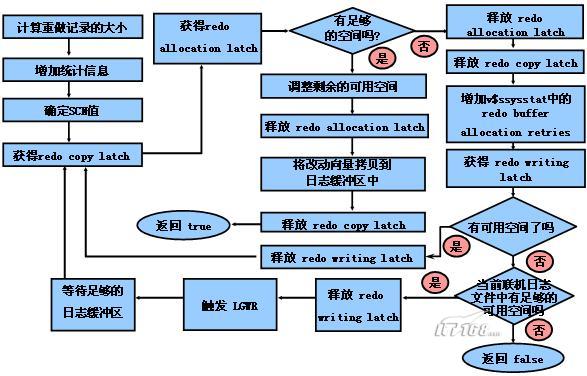
图四
上面详细介绍了重做记录的生成过程,现在详细介绍一下LGWR写重做记录的过程。
当LGWR进程启动时,
1) 首先会尝试获取redo writing latch,以确保其他前台进程不会继续触发LGWR进程。
2) 然后会获取redo allocation latch,这是为了防止前提进程继续分配更多的日志缓冲区,否则日志缓冲区中的待写入日志文件的日志块不断增长,LGWR是无法确定到底应该写多少日志块的。
3) 在获得了redo allocation
latch以后,LGWR开始确定应该写哪些日志块到日志文件。从上次LGWR启动以来所写的最后一个日志块到这个时间点时的最后一个被使用的日志块,这
段范围内的日志块都是要被写入日志文件的,其中既包含写满的日志块,也可能包含还没有写满的日志块。特别注意,这个时候,可能还有前台进程正在向这段范围
中的日志块拷贝重做记录。因为LGWR启动时,并不会阻碍前台进程获得redo copy
latch,也就不会阻碍前台进程拷贝重做记录了。这样的话,LGWR就不会阻碍前台进程向日志缓冲区的其他可用的日志块中拷贝重做记录了。
4) 在确定了要写哪些日志块以后,生成一个新的SCN号。
5) LGWR释放redo allocation latch,并释放redo writing latch。
6) LGWR会等待前台进程完成对LGWR所要写入文件的日志块的更新操作。这是通过判断这些待写的日志块上的redo copy latch是否都被释放来决定的。
7) LGWR将第4步生成的SCN号拷贝进待写的日志块的块头里,触发物理写操作,将这些待写日志块写入联机日志文件里去。
3. log buffer的优化
我们一般不太会关注日志缓冲区的优化。这是因为日志缓冲区的争用一般不会是数据库的主要性能问题。前面我们已经知道,日志块的都是按照顺序往里写,不存在
更新日志块的以前的内容,同时每个日志块大小都很小,所以几乎不会有多个进程抢同一个日志块的情况。其争用主要是进程由于找不到可用的日志块而必须等待的
情况。而我们知道LGWR负责释放脏的日志块从而提供可用日志块,LGWR在日志缓冲区中的脏日志块超过1M或者超过日志缓冲区的1/3时就会启动,而且
在将重做记录写入联机日志文件时,都是按照顺序写入,不存在类似DBWR的随机写入,所以写入的速度是非常快的,除非硬盘的I/O速度有很大的问题。可以
执行下面的SQL语句来判断硬盘的I/O是否过慢。
SQL > select total_waits,time_waited,average_wait,time_waited/total_waits as avg
2 from v$system_event where event = 'log file parallel write';
TOTAL_WAITS TIME_WAITED AVERAGE_WAIT AVG
----------- ----------- ------------ ----------
314346633 129581305 0 .41222425
我们可以看到,AVERAGE_WAIT表示LGWR完成一次写入平均需要多少时间,是用等待时间除以等待次数得出的、并四舍五入以后得到的平均值(AVG是没有四舍五入以后的值)。如果AVERAGE_WAIT大于1,就表示硬盘的I/O比较慢。
不过,对于整个数据库的健康检查来说,还是需要衡量一下数据库的日志缓冲区是否存在健康隐患。所以也还是需要了解一些有关日志缓冲区性能的一些指标。
3.1 log buffer的统计信息
有关log buffer的统计信息,我们都可以从v$sysstat里找到。我们可以运行一个DML语句,然后比较前后的统计信息,看看都发生了哪些变化。
![]() SQL> select name,value from v$sysstat where name like '%redo%' order by name;
SQL> select name,value from v$sysstat where name like '%redo%' order by name;
![]() NAME VALUE
NAME VALUE
![]() ---------------------------------------------------------------- ----------
---------------------------------------------------------------- ----------
![]() redo blocks read for recovery 110
redo blocks read for recovery 110
![]() redo blocks written 13617
redo blocks written 13617
![]() redo buffer allocation retries 0
redo buffer allocation retries 0
![]() redo entries 16868
redo entries 16868
![]() redo log space requests 0
redo log space requests 0
![]() redo log space wait time 0
redo log space wait time 0
![]() redo log switch interrupts 0
redo log switch interrupts 0
![]() redo ordering marks 1
redo ordering marks 1
![]() redo size 6228264
redo size 6228264
![]() redo subscn max counts 0
redo subscn max counts 0
![]() redo synch time 207
redo synch time 207
![]() redo synch writes 2475
redo synch writes 2475
![]() redo wastage 519976
redo wastage 519976
![]() redo write time 1105
redo write time 1105
![]() redo writer latching time 0
redo writer latching time 0
![]() redo writes 1991
redo writes 1991 ![]()
![]() SQL> update redo_test set name='cdf' where id=1;
SQL> update redo_test set name='cdf' where id=1;
![]() SQL> commit;
SQL> commit;
![]() SQL> select name,value from v$sysstat where name like '%redo%' order by name;
SQL> select name,value from v$sysstat where name like '%redo%' order by name;
![]() NAME VALUE
NAME VALUE
![]() ---------------------------------------------------------------- ----------
---------------------------------------------------------------- ----------
![]() redo blocks read for recovery 110
redo blocks read for recovery 110
![]() redo blocks written 13619
redo blocks written 13619
![]() redo buffer allocation retries 0
redo buffer allocation retries 0
![]() redo entries 16869
redo entries 16869
![]() redo log space requests 0
redo log space requests 0
![]() redo log space wait time 0
redo log space wait time 0
![]() redo log switch interrupts 0
redo log switch interrupts 0
![]() redo ordering marks 1
redo ordering marks 1
![]() redo size 6228856
redo size 6228856
![]() redo subscn max counts 0
redo subscn max counts 0
![]() redo synch time 207
redo synch time 207
![]() redo synch writes 2476
redo synch writes 2476
![]() redo wastage 520376
redo wastage 520376
![]() redo write time 1105
redo write time 1105
![]() redo writer latching time 0
redo writer latching time 0
![]() redo writes 1992
redo writes 1992
![]()
我们可以看到有些统计信息发生了变化,而有些则没有。这些统计信息都是累计值,自从实例启动以
来就一直累加而产生的。我们依次解释一些重要的统计信息。
1) redo writes、redo blocks written、redo write
time:这三个统计信息是主要的统计信息,在LGWR写完重做记录以后更新,而且只能由LGWR负责更新。redo
writes表示写了多少次,我们可以看到上例中写了1次(1992-1991);redo blocks
written表示总共写了多少日志块,可以看到写了2个日志块(13619-13617),由此我们可以知道平均写一次可以写2个日志块。redo
write
time表示将重做记录写入日志文件花了多少时间,单位是10个毫秒,我们可以看到为了写这2个日志块所需要的时间都几乎为0(1105-1105)。
2) redo size、redo
entries:这两个统计信息是在重做记录拷贝到日志缓冲区之前更新的。它们都表示产生了多少量的重做记录,redo
size以字节为单位,而redo
entries以个数为单位。比如,上例中产生了592(6228856-6228264)个字节的重做记录,共1(16869-16868)个重做记
录,平均每个重做记录为592个字节。
3) redo
wastage:该记录表示当日志缓冲区的日志块被写入日志文件时,日志块中没有被利用的空间数量,以字节为单位。因为当把重做记录拷贝到日志缓冲区中的
日志块时,需要格式化日志块以后才能实际存放日志信息,这样就会“浪费”一些日志缓冲区空间。上例中,我们可以看到为了格式化日志块而浪费了大约400
(520376-519976)个字节的空间。
注意:上例中,我们写了2个日志块 (redo blocks
written)。我们知道一个日志块的大小是512个字节,那么两个日志块的应该占用1024个字节。但是实际重做记录只占了592个字节(redo
size)。其中,为了格式化日志块而“浪费”了400个字节(redo
wastage)。同时每个日志块头需要16个字节,两个日志块就是32个字节。那么我们有:592+400+32=1024。这正是两个日志块的容量。
由此我们可以推导出这样的公式:“redo blocks written”דredo block size”=16דredo blocks
written” + “redo size” + “redo wastage”
由此我们可以看出,oracle为了更新3个字节('cdf'),需要消耗1024个字节的日志文件的空间。看来oracle在记录日志方面,确实是比较消耗磁盘空间的。所以对于更新频繁的系统而言,产生的日志量会非常大。
4) redo log space requests、redo log space wait time:redo log space
requests表示对联机日志文件空间请求的次数,redo log space wait
time表示在发出请求空间以后的等待时间。这两个统计信息只有在前台进程请求联机日志文件空间未果的情况下才会增加,这时前台进程等待日志切换完成。在
没有人为的发出alter system switch logfile命令的前提下,redo log space
requests就表示日志切换的总次数。
5) redo buffer allocation
retries:表示再次尝试在日志缓冲区中分配可用空间的次数。当进程第一次没能在日志缓冲区中获得可用空间时,该进程必须等待LGWR刷新日志缓冲区
或者等待日志切换完成等,然后会再次尝试获取空间。理想情况下,该统计信息应该为0。
注意:这
里我们可以获得在拷贝到日志块时必须等待的重做记录的数量所占的比例,计算公式为:redo buffer allocation retries /
redo
entries。该比例应该接近于0,不应大于1%。如果这个值不断变大则说明服务器进程在获得日志块之前必须等待,这时应该增加日志缓冲区,或者提高
LGWR写的效率,也就是提高硬盘物理I/O的速度。
6) redo synch writes,redo synch time:这两个统计信息是在用户每次提交(commit)时增加。redo
synch writes表示由于提交而刷新日志缓冲区的次数,而redo synch
time表示由于提交而刷新日志缓冲区所花的时间,以10个微妙为单位。
