TOOLS 让 IT 更美好
分类: NOSQL
2021-08-10 10:56:11
「世界上有着无法想象的巨量数字信息,并以极快的速度增长。从经济界到科学界,从政府部门到艺术领域,很多方面都 已经感受到了这种巨量信息的影响。科学家和计算机工程师已经为这个现象创造了一个新词汇:‘大数据’。」
——肯尼斯·库克尔《数据,无所不在的数据》
「人类正在从 IT 时代走向 DT 时代」。在 DT 时代,人们比以往时候更能收集到更丰富的数据。数据正在变革我们的生活,催生大数据行业的发展,而迅猛增长的数据也带来了严峻的数据处理问题。
在大数据时代,传统的软件已经无法处理和挖掘大量数据中的信息。最重要的变革就是谷歌的“三架马车”。谷歌在 2004 年左右相继发布谷歌分布式文件系统 GFS、大数据分布式计算框架 Mapreduce、大数据 Nosql 数据库 BigTable ,这三篇论文奠定了大数据技术的基石。
接下来,大数据相关技术不断发展,开源的做法让大数据生态逐渐形成。由于MapReduce 编程繁琐,Facebook 贡献 HiveQL 语法为数据分析、数据挖掘提供巨大帮助。Elasticsearch、Splunk等面向搜索数据内容的搜索引擎也登上舞台,主要用于对海量数据进行实时处理和分析。
CloudQuery 作为数据管控平台,在其成长规划中计划支持全类型数据源。在1.4 迭代过程中,将加入用户呼声最高的 Hive 和 Elasticsearch。
说到 Hive,我们不得不提 Hadoop。Hadoop 几乎是现有数据库系统的一种补充,它给用户提供了数据存储的无限空间,擅长存储任意的、半结构化的数据,甚至是非结构化的数据,支持用户在恰当的时候存储和获取数据,并且针对大文件的存储、批量访问和流式访问做了分类优化。
这使得用户对数据分析变得简单快捷,但是用户同样需要访问分析后的最终数据,这种需求需要的不是批量模式而是随机访问模式,这种模式对于数据库系统来说,相当于一种全表扫描和使用索引。
而 Hive 是一个构建在 Hadoop 上的数据仓库框架,是应 Facebook 每天生产的海量新兴社会网络数据进行管理和(机器)学习的需求而产生和发展的。Hive 的设计目的是让精通 SQL 技能但 Java 编程技能相对较弱的分析师能够对 Facebook 存放在 HDFS 中的大规模数据集执行查询。今天,Hive 已经是一个成功的 Apache 项目,很多组织把它用作一个通用的、可伸缩的数据处理平台。
作为 Hadoop 的主流搜索引擎之一,Hive 支持使用SQL来读、写和管理大规模数据集合。CloudQuery 在进行 Hive 数据源对接时首先考虑在大数据量情况下的查询性能问题,控制每次返回的数据为当前 viewpoint 展示用量。其次在大数据或数仓中为了便于数据分析通常为宽表存储,所以在渲染时也会增加多种展现方式切换,包含列表格式和单条格式,列表格式可以提供批量数据预览,单条格式则以列的形式进行宽表详情展示。
Hive 旧版本只支持数据查询和加载,但后续版本增加支持了插入,更新和删除以及流式 api。所以 CloudQuery 在进行数据操作与权限管控覆盖的同时兼顾数据库原生操作特性,增加多种 api 支持。同步支持分区以及分桶特性,分区表针对数据存储路径,设置不同存储路径产生多个数据文件。分桶表针对数据文件,对一个数据文件分为更容易管理的若干部分。
与 Hive 不同,Elasticsearch 是面向数据内容搜索的搜索引擎。Elasticsearch 作为一个独立的搜索服务器,提供了非常方便的搜索功能。用户完全不用关心底层 Lucene 的细节,只需要通过标准的 Http + RESTful 风格的 API,就可以进行索引数据的增删改查。数据的输入输出采用 JSON 格式,以文档和面向对象的方式,非常方便理解和表达领域数据。
同时,Elasticsearch 基于分片和副本的方式实现了一个分布式的 Lucene Directory,再结合Map-reduce 的理念,实现了一个简单的搜索请求分发合并的策略,能轻松化解海量索引和分布式高可用的问题。
如今,Elasticsearch 基本上已经是搜索引擎市场排名第一的产品,从 DB-Engines 网站的排名可以看到,Elasitcsearch 基本上是一骑绝尘,拉开第二名远远一大截。
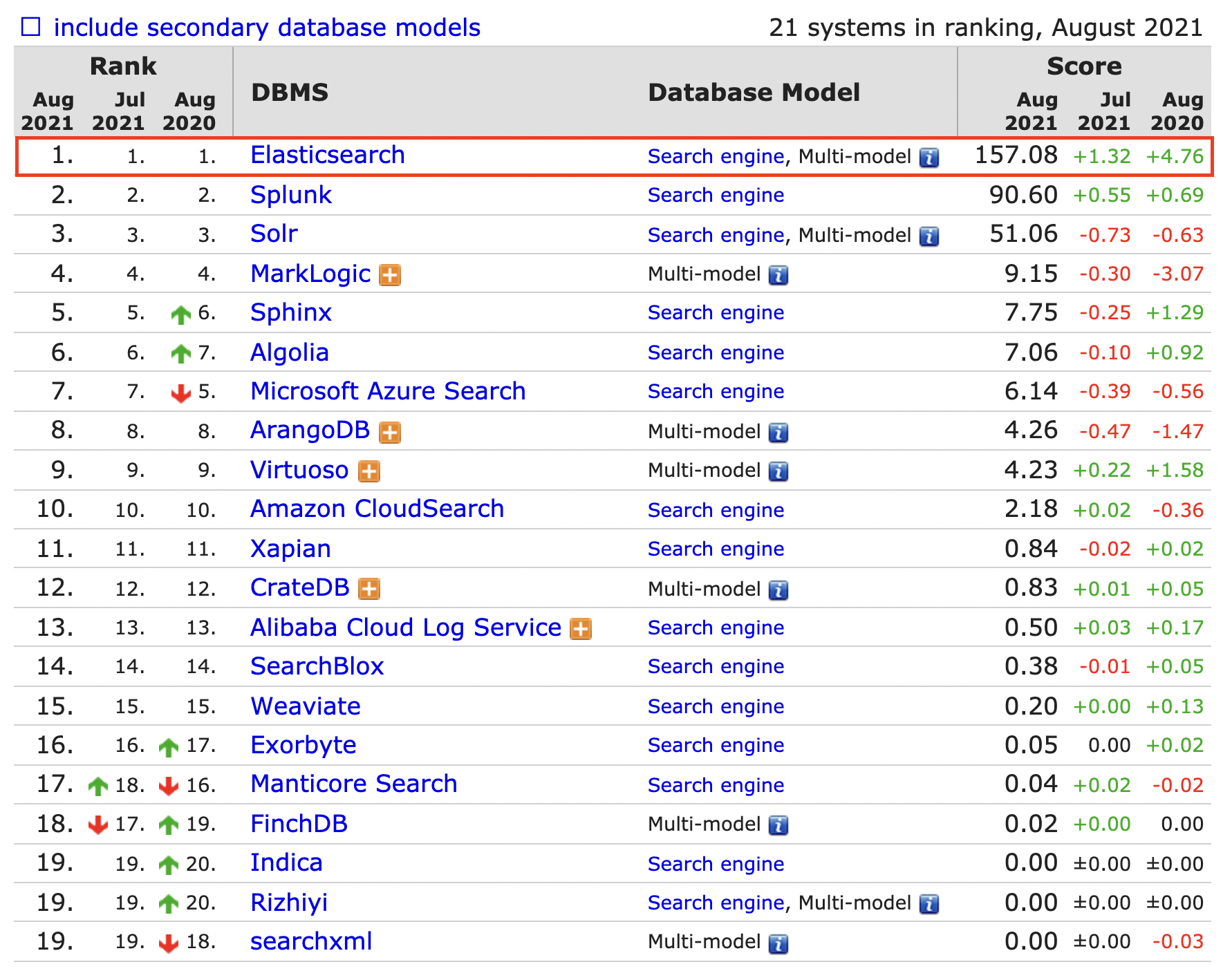
上文中也提到了,ES 与目前市面上主流的数据库之前的区别主要在于最开始它甚至并不算是数据库而是作为搜索引擎出现在大众视野中,后续随着各种技术的成熟以及广度覆盖将全文检索、数据分析以及分布式技术,合并在了一起,才形成了现在我们视野中的 ES。所以它可以同时拥有分布式、查询快速等优点。
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。CloudQuery 在进行对接支持时考虑到 ES 中存储数据类型的特殊性,将其分为文档和索引,可以对文档进行索引、搜索、排序、过滤。这种理解数据的方式与传统的二维表形式完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
在展现形式上我们选择了最通用化的「JSON」格式,因为数据间的差异性导致应用中的对象很少只是简单的键值列表,更多时候它拥有复杂的数据结构,比如包含日期、地理位置、子对象甚至数组。尽管几乎所有的语言都有相应的模块用于将任意数据结构转换为 JSON 格式,但每种语言处理细节不同,所以 CloudQuery 在处理语言和对象兼容性上也进行了水平覆盖,优先保证主流语言以及对象的序列化以及反序列化。
“新基建”的加速为数字经济创造了有利的条件和巨大的发展契机,市场将进一步拥抱云、大数据和商业智能,通过云数智的加速融合,必将加速实现企业数据价值最大化,并高效完成产业智能化的转型和落地。
